










- 摘要
- 安装微软caffe
- 数据集准备
- CPU训练
- 网络模型和solver方案
- 训练
- 后序优化工作
1、摘要
一般情况下,caffe的训练和使用都是在linux下使用的,但是特殊要求,所以要在windows下进行训练和使用。除了训练的工作之外,windows下caffe工程主要用来学习和代码阅读。
2、安装caffe
windows下的caffe版本,有两个。一个是某网友做的开源项目;一个是微软caffe。现在在caffe的官网文档介绍,推荐的windows caffe就是微软caffe.
(1)版本1
项目链接地址
https://github.com/happynear/caffe-windows
第三方库可以使用作者提供的百度云盘下载。然后解压到3rdparty目录下;其他请看开源项目的README.md文件。
(2)版本2
项目链接地址:
https://github.com/BVLC/caffe/tree/windows
项目基本上不需要进行配置。
如果不使用gpu的话,需要修改进行以下操作。
将.\windows\CommonSettings.props 设置CpuOnlyBuild = true
UseCudnn = false。然后 build .\windows\Caffe.sln
其他请参照官网。
安装好之后,运行编译。我们需要用到的工程
- caffe 用于训练
- classification 用于分类
- computer_image_mean 计算图像像素的均值
- convert_imageset 转化图像为lmdb数据格式
- libcaffe lib库,其他工程的引用工程。
依次编译即可。
然后可在项目路径下找到可执行文件。
路径: caffe-master\Build\x64\Release
3.数据集准备
性别的数据集国外不少,但是包括亚洲人的数据集不多。我做过总结。如下。
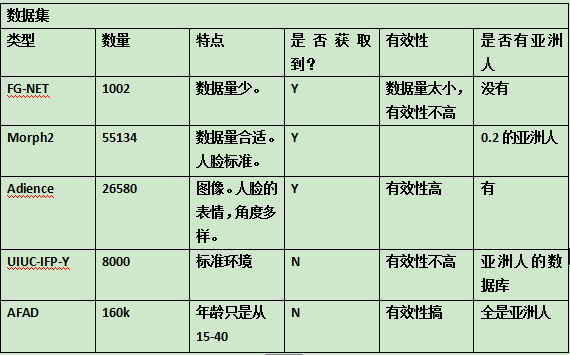
其中的AFAD数据集是今年的CVPR的文章[1]。但是我们给作者发了邮件,不过并没有回信。
显而易见的是:使用非亚洲人的数据集训练的模型,对亚洲人分类效果特别差。所以,为了训练一个好的性别模型,收集一个较大的亚洲人数据集是至关重要的。
本人所在的实验室收集了一个2万左右的亚洲人数据集:明星数据集。
(1)数据集介绍
| 明星数据集 | 男性 | 女性 | 总数 |
|---|---|---|---|
| 训练集 | 8776 | 7989 | 23377 |
| 测试集 | 3487 | 3122 |

(2)数据集的获取
我们实验室的数据集不公布。但是说下我们的收集方式。
- 使用百度批量下载软件 下载明星人脸数据集。这个可以百度搜下
- 编写简单的爬虫代码
3、CPU训练过程
请先标注好数据集
一般工程都是先转化为lmdb文件。
(1)运行convert_imageset.cpp 产生lmdb文件
在运行前请先编译。然后进入到
caffe-master\Build\x64\Release目录下。运行 convert_imageset.exe文件。
命令格式:
covert_imageset.exe 你的图片的根目录(第一个参数) 你的txt文件(第二个参数)
(2)编译运行 computer_image_mean
命令格式:
Computer_image_mean.exe 你的train的lmdb文件
(3)编译caffe
命令格式:
运行 caffe.exe train –solver=你的solver文件
这样大概就运行起来了,开始训练了。
4、网络模型和solver方案
请参考我的开源项目中的网络模型。
https://github.com/zhangqianhui
在assets 目录下的deploy.prototxt 文件。
solver文件大同小异。
test_iter: 1000
test_interval: 1000
base_lr: 0.01
lr_policy: "step"
gamma: 0.1
#power:0.75
stepsize: 2000
display: 20
max_iter: 10000
momentum: 0.9
weight_decay: 0.0005
snapshot: 100005、训练
首先说下,我训练用的是GPU版本(数据集过大,最好使用GPU版本),CUDA版本7.5,之前已经安装好了。
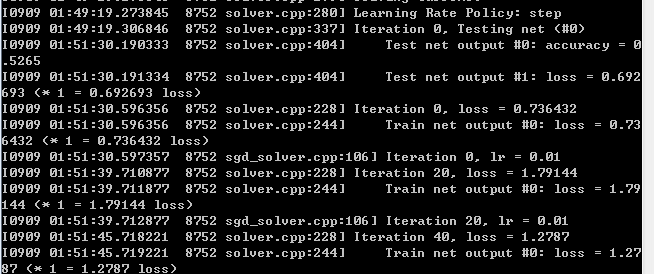
测试集的实验结果:
实验结果: 88%
6、后序优化工作
现在做性别预测,比较好的预测率能达到95以上。本次只是将模型跑了起来,那么如何做优化,达到更好的分类效果,是下面最为重要的问题。
本人未来的的优化工作如下。
修改模型
修改模型的工作没有那么容易做,一般要有较好的调参经验,才能在短时间内做到优化。最近比较热门的网络模型也可以关注,比如BN网络,Resnet,都可以作为未来模型优化的一个尝试。
修改数据集
最简单,最暴力的优化方式,就是增大数据集。基本上,增大数据集一定会提高测试集的识别率。还有就是对数据集做优化,去除一些相似的图片,增大图片之间的差异性,也就是非线性程度。















 185
185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









