







 本文详细介绍了在Windows环境下使用Caffe进行人脸识别年龄和性别识别的实验过程,包括环境配置、数据选择与处理、图片数据转化为LDMB格式、计算训练样本均值、网络定义与设置等步骤。在训练过程中,作者遇到并解决了网络参数配置不当导致的问题。
本文详细介绍了在Windows环境下使用Caffe进行人脸识别年龄和性别识别的实验过程,包括环境配置、数据选择与处理、图片数据转化为LDMB格式、计算训练样本均值、网络定义与设置等步骤。在训练过程中,作者遇到并解决了网络参数配置不当导致的问题。
一、环境配置
http://blog.csdn.net/ITSophia/article/details/77799927
环境配置好以后,可以直接用网上的模型先测试一下正确率 http://www.openu.ac.il/home/hassner/projects/cnn_agegender/
下载下来这个压缩包cnn_age_gender_models_and_data.0.0.2.zip,里面是训练好的caffe模型(.caffemodel)和网络结构(.prototxt),用python自己写了一个图片预处理的文件和加载caffe模型的程序,测试了30张图片,运行结果发现性别正确率还行,但是年龄差距就太大了。于是重新训练
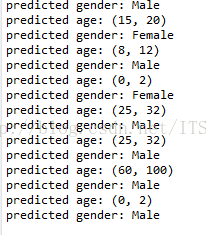
二、选择数据
选择数据是很重要的一步骤,因为很多数据源脏数据很多,可以先用python分析一遍数据源,数据源地址:http://www.openu.ac.il/home/hassner/Adience/data.html#agegender
可以从该网站提供的FTP:agas.openu.ac.il上下载数据源,通过Python分析得到的数据情况为:
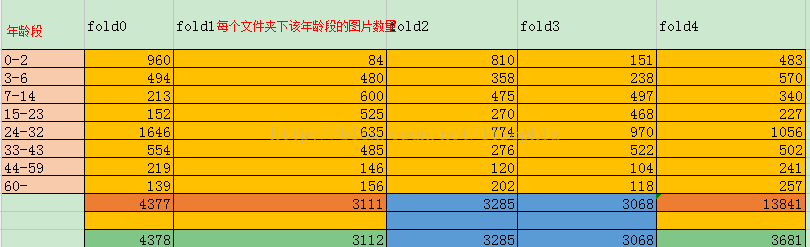
发现根据我划分的年龄段,数据源中的(38, 48),(8, 23)年龄段就不在这个范围内,但是已经很大程度上涵盖了,因此剔除了这两个年龄段的数据图片,数量也就是个位数,相较于一万多张图片来说是比较好的年龄段划分了。
还有性别的图片数据比例

训练集、验证集、测试集的划分数量为:

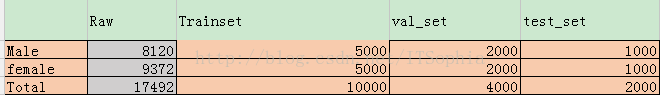
写一个Python脚本,来整理出需要的训练集、验证集图片,以及对应的txt文件,txt文件里的内容是图片名称(如果train文件夹下的图片还有子目录,记得txt文件里的图片名称前要带上子目录的名称的,生成LDMB文件时会用到,幸好下载下来的数据源里的文件名称都正常的)
三、将图片数据转化成LDMB格式
训练集和验证集的准备,以及标签文件的准备可以参考博文:http://www.cnblogs.com/TensorSense/p/6744075.html
虽然caffe是可以直接读图片的,但因为训练的数据很多,所以一般都会选择转换成LDMB(caffe认识图片的格式),生成LDMB非常简单。我们配caffe时,需要在C++里编译很多项目,编译好后会在C:\caffe-master\Build\x64\Release目录下生成convert_imageset.exe,这就是用来帮我们转成LDMB的工具。
现在,我把训练和验证的图片以及对应的train_gender.txt和val_gender.txt放在F:\analyseData\train和F:\analyseData\val目录下,在F:\analyseData目录下新建 comput_image_mean.txt
C:\caffe-master\Build\x64\Release\convert_imageset.exe train/ train_gender.txt train_lmdb -backend=lmdb -resize_height=227 -resize_width=227 -shuffle
pause  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1948
1948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









