







1.linux基本I/O接口介绍
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, void *buf, size_t count);以上两个是linux下的两个系统调用,用于对文件行基本的I/O操作。fd是非负文件描述符,其实相当于标识一个文件的唯一编号。默认标号0是标准输入(终端输入),1是标准输出(终端输出),2是标准错误。所以用户通过 open 能够打开的文件得到的文件描述符的最小编号是3。
在Linux中,read 和 write 是基本的系统级I/O函数。当用户进程使用read 和 write 读写linux的文件时,进程会从用户态进入内核态,通过I/O操作读取文件中的数据。内核态(内核模式)和用户态(用户模式)是linux的一种机制,用于限制应用可以执行的指令和可访问的地址空间,这通过设置某个控制寄存器的位来实现。进程处于用户模式下,它不允许发起I/O操作,所以它必须通过系统调用进入内核模式才能对文件进行读取。
从用户模式切换到内核模式,主要的开销是处理器要将返回地址(当前指令的下一条指令地址)和额外的处理器状态(寄存器)压入到栈中,这些数据到会被压到内核栈而不是用户栈。另外,一个进程使用系统调用还隐含了一点——调用系统调用的进程可能会被抢占。当内核代表用户执行系统调用时,若该系统调用被阻塞,该进程就会进入休眠,然后由内核选择一个就绪状态,当前优先级最高的进程运行。另外,即使系统调用没有被阻塞,当系统调用结束,从内核态返回时,若在系统调用期间出现了一个优先级更高的进程,则该进程会抢占使用了系统调用的进程。内核态返回会返回到优先级高的进程,而不是原本的进程。
虽然我们可以每次进行读写时都使用系统调用,但这样会增大系统的负担。当一个进程需要频繁调用 read 从文件中读取数据时,它便要频繁地在用户态与内核态之间进行切换,极端点地设想一个情景,每次read调用都只读取一个字节,然后循环调用read读取n个字节,这便意味着进程要在用户态和内核态之间切换n次,虽然这是一个及其愚蠢的编程方法,但能够毫无疑问说明系统调用的开销。下图是调用read(int fd, void *buf, size_t count)读取516,581,760字节,每次read可以读取的最大字节数量(count的值)的不同对CPU的存取效率的影响。
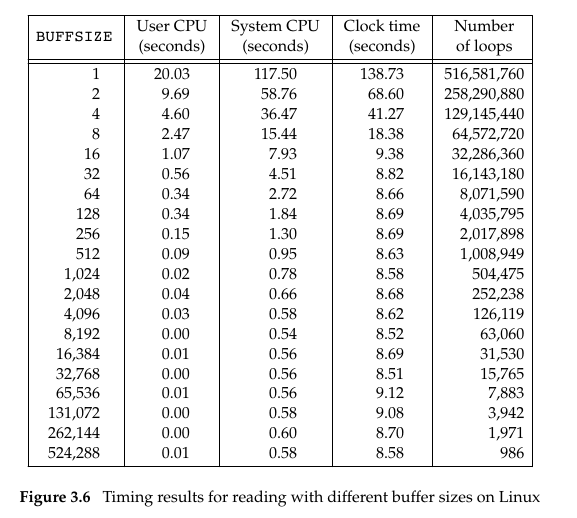
这张表的运行结果是基于块大小为4096-byte的ext4文件系统上的,所以可以看到当 BUFFSIZE=4096时,System CPU 几乎达到了最小值,之后块大小若继续增加,System CPU时间减小的幅度很小,甚至还有所增加。这是若 BUFFSIZE 过大,其缓冲区便跨越了不同的块,导致存取效率降低。
2.RIO包
RIO,全称 Robust I/O,即健壮的IO包。它提供了与系统I/O类似的函数接口,在读取操作时,RIO包加入了读缓冲区,一定程度上增加了程序的读取效率。另外,带缓冲的输入函数是线程安全的,这与Stevens的 UNP 3rd Edition(中文版) P74 中介绍的那个输入函数不同。UNP的那个版本的带缓冲的输入函数的缓冲区是以静态全局变量存在,所以对于多线程来说是不可重入的。RIO包中有专门的数据结构为每一个文件描述符都分配了相应的独立的读缓冲区,这样不同线程对不同文件描述符的读访问也就不会出现并发问题(然而若多线程同时读同一个文件描述符则有可能发生并发访问问题,需要利用锁机制封锁临界区)。
另外,RIO还帮助我们处理了可修复的错误类型:EINTR。考虑read和write在阻塞时被某个信号中断,在中断前它们还未读取/写入任何字节,则这两个系统调用便会返回-1表示错误,并将errno置为EINTR。这个错误是可以修复的,并且应该是对用户透明的,用户无需在意read 和 write有没有被中断,他们只需要直到read 和 write成功读取/写入了多少字节,所以在RIO的rio_read()和rio_write()中便对中断进行了处理。
#define RIO_BUFSIZE 4096
typedef struct
{
int rio_fd; //与缓冲区绑定的文件描述符的编号
int rio_cnt; //缓冲区中还未读取的字节数
char *rio_bufptr; //当前下一个未读取字符的地址
char rio_buf[RIO_BUFSIZE];
}rio_t;这个是rio的数据结构,通过rio_readinitb(rio_t *, int)可以将文件描述符与rio数据结构绑定起来。注意到这里的rio_buf的大小是4096,这个参考了上图,为linux中文件的块大小。
void rio_readinitb(rio_t *rp, int fd)
/**
* @brief rio_readinitb rio_t 结构体初始化,并绑定文件描述符与缓冲区
*
* @param rp rio_t结构体
* @param fd 文件描述符
*/
{
rp->rio_fd = fd;
rp->rio_cnt = 0;
rp->rio_bufptr = rp->rio_buf;
return;
}
static ssize_t rio_read(rio_t *rp, char *usrbuf, size_t n)
/**
* @brief rio_read RIO--Robust I/O包 底层读取函数。当缓冲区数据充足时,此函数直接拷贝缓
* 冲区的数据给上层读取函数;当缓冲区不足时,该函数通过系统调用
* 从文件中读取最大数量的字节到缓冲区,再拷贝缓冲区数据给上层函数
*
* @param rp rio_t,里面包含了文件描述符和其对应的缓冲区数据
* @param usrbuf 读取的目的地址
* @param n 读取的字节数量
*
* @returns 返回真正读取到的字节数(<=n)
*/
{
int cnt;
while(rp->rio_cnt <= 0)
{
rp->rio_cnt = read(rp->rio_fd, rp->rio_buf, sizeof(rp->rio_buf));
if(rp->rio_cnt < 0)
{
if(errno != EINTR) //遇到中断类型错误的话应该进行读取,否则就返回错误
return -1;
}
else if(rp->rio_cnt == 0) //读取到了EOF
return 0;
else
rp->rio_bufptr = rp->rio_buf; //重置bufptr指针,令其指向第一个未读取字节,然后便退出循环
}
cnt = n;
if((size_t)rp->rio_cnt < n)
cnt = rp->rio_cnt;
memcpy(usrbuf, rp->rio_bufptr, n);
rp->rio_bufptr += cnt; //读取后需要更新指针
rp->rio_cnt -= cnt; //未读取字节也会减少
return cnt;
}
ssize_t rio_readnb(rio_t *rp, void *usrbuf, size_t n)
/**
* @brief rio_readnb 供用户使用的读取函数。从缓冲区中读取最大maxlen字节数据
*
* @param rp rio_t,文件描述符与其对应的缓冲区
* @param usrbuf void *, 目的地址
* @param n size_t, 用户想要读取的字节数量
*
* @returns 真正读取到的字节数。读到EOF返回0,读取失败返回-1。
*/
{
size_t leftcnt = n;
ssize_t nread;
char *buf = (char *)usrbuf;
while(leftcnt > 0)
{
if((nread = rio_read(rp, buf, n)) < 0)
{
if(errno == EINTR) //其实这里可以不用判断EINTR,rio_read()中已经对其处理了
nread = 0;
else
return -1;
}
leftcnt -= nread;
buf += nread;
}
return n-leftcnt;
}
ssize_t rio_readlineb(rio_t *rp, void *usrbuf, size_t maxlen)
/**
* @brief rio_readlineb 读取一行的数据,遇到'\n'结尾代表一行
*
* @param rp rio_t包
* @param usrbuf 用户地址,即目的地址
* @param maxlen size_t, 一行最大的长度。若一行数据超过最大长度,则以'\0'截断
*
* @returns 真正读取到的字符数量
*/
{
size_t n;
int rd;
char c, *bufp = (char *)usrbuf;
for(n=1; n<maxlen; n++) //n代表已接收字符的数量
{
if((rd=rio_read(rp, &c, 1)) == 1)
{
*bufp++ = c;
if(c == '\n')
break;
}
else if(rd == 0) //没有接收到数据
{
if(n == 1) //如果第一次循环就没接收到数据,则代表无数据可接收
return 0;
else
break;
}
else
return -1;
}
*bufp = 0;
return n;
}
ssize_t rio_writen(int fd, void *usrbuf, size_t n)
{
size_t nleft = n;
ssize_t nwritten;
char *bufp = (char *)usrbuf;
while(nleft > 0)
{
if((nwritten = write(fd, bufp, nleft)) <= 0)
{
if(errno == EINTR)
nwritten = 0;
else
return -1;
}
bufp += nwritten;
nleft -= nwritten;
}
return n;
}以上便是rio的基本输入输出函数。注意到rio_writen(int fd, void *, size_t)代表文件描述符的参数是int类型,而不是rio_t类型。因为rio_writen不需要写缓冲。这是为什么呢?按道理来说,既然我们为read封装的rio_readn提供了缓冲区,为什么不也为write提供一个有缓冲的rio_writen函数呢?
试想一个场景,你正在写一个http的请求报文,然后将这个报文写入了对应socket的文件描述符的缓冲区,假设缓冲区大小为8K,该请求报文大小为1K。那么,如果缓冲区被设置为被填满才会自动将其真正写入文件(而且一般也是这样做的),那就是说如果没有提供一个刷新缓冲区的函数手动刷新,我还需要额外发送7K的数据将缓冲区填满,这个请求报文才能真正被写入到socket当中。所以,一般带有缓冲区的函数库都会一个刷新缓冲区的函数,用于将在缓冲区的数据真正写入文件当中,即使缓冲区没有被填满,而这也是C标准库的做法。然而,如果一个程序员一不小心忘记在写入操作完成后手动刷新,那么该数据(请求报文)便一直驻留在缓冲区,而你的进程还在傻傻地等待响应。
3.C标准IO库
绝大部分的系统都提供了C接口的标准IO库,与RIO包相比,标准IO库有更加健全的,带缓冲的并且支持格式化输入输出。标准IO和RIO包都是利用read, write等系统调用实现的(在windows等非Unix标准的系统则有其他对应的调用)。既然已经存在一个健全的,带缓冲的IO借口,那为什么还需要上述的RIO包呢? 正是标准IO的缓冲机制对文件描述符的读写产生了一点负面影响,如果程序员忽略这些问题,那么在对网络套接字进行读写操作时就会出现很大的问题。
标准IO操作的对象与Unix I/O的不太相同,标准IO接口的操作对象是围绕流(stream)进行的。当使用标准I/O接口打开或创建一个文件时,我们令一个流和一个文件相关联。在默认的情况下,使用标准IO打开的文件流是带有缓冲的(或许是全缓冲,或许是行缓冲)。这样,在使用fputs等输出函数时,数据会先被写入文件流的缓冲区中,等到缓冲满才真正将数据写入文件。当FILE *fopen(const char *path, const char *mode);中的参数mode以读和写类型(r+,w+,a+等)打开文件时,具有如下限制:
- 如果中间没有fflush, fseek, fsetpo 或rewind,则在输出的后面不能直接跟随输入。
- 如果中间没有fseek, fsetpos或 rewind,或者一个输入操作没有达到文件尾端,则在输入操作之后不能直接跟随输入。
在Ubuntu15.10 x64中,经过测试,对于普通文件(非socket)的操作,似乎不遵守这个规则读写也正常。然而,为了程序的可移植性和健壮性,依然建议遵守标准的规定编程。
man fopen 中的一段话:
If this condition is not met, then a read is allowed to return
the result of writes other than the most recent.) Therefore it is good
practice (and indeed sometimes necessary under Linux) to put an
seek(3) or fgetpos(3) operation between write and read operations on
such a stream. This operation may be an apparent no-op (as in
fseek(…, 0L, SEEK_CUR) called for its synchronizing side effect).
在网络套接字的编程中,对套接字使用lseek函数是非法的,而fseek,fsetpos和rewind都是通过lseek函数重置当前的文件位置,所以对于套接字来说,可使用的便只有fflush函数,这个函数的作用是刷新缓冲区,将缓冲区中的数据真正写入文件中。
所以,对于大多数应用程序而言,标准IO更简单,是优于Unix I/O的选择。然而在网络套接字的编程中,建议不要使用标准IO函数进行操作,而要使用健壮的RIO函数。RIO函数提供了带缓冲的读操作,与无缓冲的写操作(对于套接字来说不需要),且是线程安全的。通过RIO包的学习,理解底层Unix I/O的实现也能更好避免在使用上层IO接口中犯错。
参考书籍:
《深入理解计算机系统》
《Unix网络编程卷1第三版》
《Unix高级编程第二版》

















 321
321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









