






第6章
尝试一些实际中的语法
在前一章,我们学习了通用词法结构和语法结构,并学习了如何用ANTLR的语法来表述这些结构。现在,是时候把我们学到的这些用来构建一些现实世界中的语法了。我们的主要目标是,怎样通过筛选引用手册,样例输入文件和现有的非ANTLR语法来构建一个完整语法。这一章,我们要实现五种语言,难度依次递增。现在,你不需要将它们全部都实现了,挑一个你最喜欢的实现,当你在实践过程中遇到问题了再回过头来看看就好了。当然,也可以看看上一章学习到的模式和ANTLR代码片段。
我们要实现的第一个语言就是逗点分割值格式(CSV),这种格式经常会在Excel这样的电子表格以及数据库中用到。从CSV开始是一个很好的选择,因为它不仅简单,而且应用非常广泛。第二种要实现的语言也是一种数据格式,叫做JSON,它包含嵌套数据元素,实现它可以让我们掌握实际语言中递归规则的用法。
下一个,我们要实现一个说明性语言,叫做DOT,用来描述图形(网络上的)。在这个说明性语言中,我们只感受下其中的逻辑结构而不指定控制流。DOT语言能够让我们实践更加复杂的词法结构,比如不区分大小写的关键字。
我们要实现的第四个语言是一种简单的非面向对象的编程语言,叫做Cymbol(在《语言实现模式》这本书的第6章也会讨论到这个语言)。这种语法可以作为一种典型的语法,我们可以将其作为参考,或者是实现其它编程语言的入手点(那些由函数,变量,语句和表达式组成的编程语言)。
最后,我们要实现一个函数式编程语言,R语言。(函数式编程语言通过计算表达式进行计算。)R语言是一种用在统计上的语言,现在多用于数据分析。我选择R语言作为例子,是因为其语法主要由巨型表达式规则组成。这对于我们加深对算符优先的理解,并结合到实际语言中,有着极大的好处。
当我们对建立语法比较熟练之后,我们就可以撇下语法识别,而去研究当程序看到自己感兴趣的输入时,应该怎样采取行动。在下一章,我们会创建分析监听器来创建数据结构,并通过符号表来追踪变量和函数定义,并实现语言的翻译。
那么,就让我们先从CSV文件开始吧。
6.1 解析逗点分割值
虽然,我们在第5章的序列模式中曾经介绍过一个简单的CSV语法,现在,让我们对其添加点规则:首行作为标题行,并且允许某一格的值为空。下面是一个具有代表性的输入文件的例子:
examples/data.csv
Details,Month,Amount
Mid Bonus,June,"$2,000"
,January,"""zippo"""
Total Bonuses,"","$5,000"
标题行和数据行基本上没什么差别,我们只是简单地将标题行里面的字段作为标题使用。但是,我们需要将其单独分离出来,而不是简单地使用row+这样的ANTLR片段去匹配。这是因为,当我们在这个语法上建立实际应用的时候,我们往往都需要区别对待标题行。这样,我们就可以很好地对第一行进行特殊处理了。下面是这个语法的一部分:
examples/CSV.csv
grammar CSV;
file : hdr row+ ;
hdr : row ;
注意到我们在上面引入了一个特殊的规则hdr来表示首行。但是这个规则在语法上就是一个row规则。我们通过将其分离出来使其作用更加清晰。你可以仔细对比下这种写法与直接在规则file右边写一个“row+”或者“row*”之间的差别。
row规则和前面介绍的一样:是一系列由逗号分隔开的字段,由换行符结束。
examples/CSV.csv
row : field (',' field)*'\r'?'\n';
为了让我们的字段比前面介绍的更具有通用性,我们允许这个字段出现任意文本,字符串甚至什么都不出现(两个逗号之间什么也没有,也就是空字段)。
examples/CSV.csv
field
: TEXT
| STRING
| ;
符号的定义不算太坏。TEXT符号就是一个字符的序列,这个字符的序列在遇到下一个逗号或者换行符之前结束。STRING符号就是用双引号引起来的字符序列。下面是这两个符号的定义:
examples/CSV.csv
TEXT : ~[,\n\r"]+ ;
STRING : '"'('""'|~'"')* '"' ; // quote-quote is an escaped quote
如果要在双引号引起来的字符串中间出现双引号,CSV格式采用的是使用两个双引号表示,这就是STRING规则中“(‘””’|~’”’)”子规则所代表的意义。注意,我们在这里不能使用像“(‘””’|.)*?”这样的非贪婪循环的通配符,因为这种情况下,通配符的匹配会在遇到第一个“””的时候而结束。像”x””y”这样的输入,将会被匹配为两个字符串,而不会被匹配为一个字符串中出现一个“”””。记住,非贪婪子规则就算是匹配了内部规则的时候也会尽可能地匹配最少的字符。
在测试我们的语法规则之前,我们最好先看下解析得到的符号流,以确保我们的词法分析器能够正确地分割字符流。利用重命名为grun的TestRig工具,加上-tokens选项,我们能够得到下面的结果:
➾$ antlr4 CSV.g4
➾$ javac CSV*.java
➾$ grun CSV file -tokens data.csv
<[@0,0:6='Details',<4>,1:0]
[@1,7:7=',',<1>,1:7]
[@2,8:12='Month',<4>,1:8]
[@3,13:13=',',<1>,1:13]
[@4,14:19='Amount',<4>,1:14]
[@5,20:20='\n',<2>,1:20]
[@6,21:29='Mid Bonus',< 4>,2:0]
[@7,30:30=',',<1>,2:9]
[@8,31:34='June',<4>,2:10]
[@9,35:35=',',<1>,2:14]
[@10,36:43='"$2,000"',<5>,2:15]
[@11,44:44='\n',<2>,2:23]
[@12,45:45=',',<1>,3:0]
[@13,46:52='January',<4>,3:1]
...
结果看起来不错,标点符号,文本,字符串都像预期的那样被正确分割开了。
接下来,让我们看看应该怎样去识别输入的语法结构。使用-tree选项,测试工具就会以文本的方式打印出语法分析树(书中对其做了删减)。
➾$ grun CSV file -tree data.csv
<(file
(hdr (row (field Details) , (field Month) ,(field Amount) \n))
(row (field Mid Bonus) , (field June) , (field"$2,000") \n)
(row field , (field January) , (field"""zippo""") \n)
(row (field Total Bonuses) , (field"") , (field "$5,000") \n)
)
树的根节点代表了file规则匹配的所有内容,包括一个开始的标题行规则以及许多行规则作为子节点。下面是这棵语法树的可视化显示(使用-ps file.ps选项):
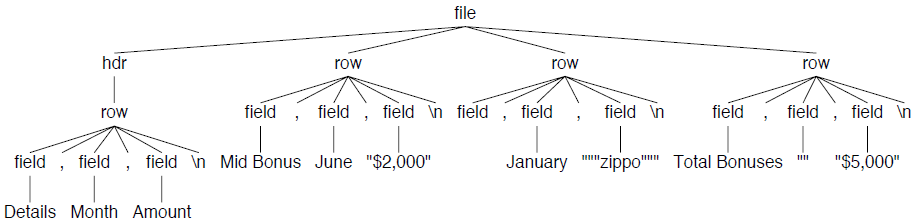
CSV格式非常的简单直观,但是却无法实现在一个字段中包含很多值这种需求。为此,我们需要一种支持嵌套元素的数据格式。
6.2 解析JSON
JSON是一种文本的数据格式,它包含了键值对的集合,并且,值本身也可以是一个键值对的集合,所以JSON是一种嵌套的结构。在设计JSON的时候,我们可以学习到如何从语言的参考手册中推导语法,并可以尝试更多的复杂词法结构。把问题具体化,下面是一个简单的JSON数据文件:
examples/t.json
{
"antlr.org": {
"owners": [],
"live": true,
"speed": 1e100,
"menus": ["File","Help\nMenu"]
}
}
我们的目标是根据JSON的参考手册以及参考一些已有语法的图表来建立一个ANTLR语法。我们将提取出手册中的关键短语,并指出如何将其表述成ANTLR规则。那么从语法结构开始吧。
JSON语法规则
JSON的语法手册是这么写的:一个JSON文件可以是一个对象,也可以是一个值的数组。从语法上说,这显然是一个选项模式,于是我们便可以向下面这样来指定规则:
examples/JSON.g4
json: object
| array
;
下一步就应该将json中的引用规则继续向下推导。对于object规则,参考手册中是这么写的:
一个对象(object)就是一个键值对的无序集合。它由左大括号“{”开始,以右大括号“}”结束。每一个键的后面都跟着一个冒号“:”,并且键值对是用逗号“,”分割开的。
JSON官网中的语法图中也指明,键一定是一个字符串。
将这段文字表述转换为语法结构,我们将这段表述拆开并寻找能够符合我们所了解的模式(序列,选项,符号约束和嵌套短语)的短语。最开始的那句话“一个对象就是…”显然指出了我们需要定义一个叫做object的规则。然后,“一个键值对的无序集合”其实指的就是键值对的序列。“无序集合”是指键的语义上的意义;具体来说,就是键的顺序并没有意义。这也意味着,在解析的过程中,我们只需要匹配任何出现的键值对列表就可以了。
第二句话说object是由大括号包含起来的,这显然是在说明一个符号约束模式。最后一句话定义了我们的键值对序列是一个由逗号分隔开的序列。总结起来,我们将这些用ANTLR来表示是这个样子的:
examples/JSON.g4
object
: '{' pair (','pair)*'}'
| '{' '}' // empty object
;
pair: STRING ':' value;
为了清晰并减少代码重复,最好将键值对也定义成一个规则,不然的话,object的第一个选项就会看起来像这个样子:
object : '{' STRING':'value (','STRING ':'value)*'}'| ... ;
注意,我们将STRING作为一个符号来处理,而不是一个语法规则。我们已经非常确定,我们的程序只处理完整的字符串,而不会进一步拆成字符来处理。关于这部分,详细可以参考第5.6节。
JSON参考手册也会有一些非正式的语法规则,我们来将这些规则和ANTLR的规则做个对比。下面是从参考手册中找到的语法定义:
object
{}
{ members }
members
pair
pair , members
pair
string : value
参考手册中也将pair规则给单独提取出来了,但是参考手册中定义了member规则,我们没有定义这个。在“循环对抗尾递归”一节中会具体描述如果没有“(…)*”循环的时候,语法是怎么解析序列的。
接下来再看另一个高层结构,数组。参考手册中是这样描述数组的:
数组(array)是一个有序的值的集合。数组由左中括号“[”开始,由右中括号“]”结束。不同的数值之间用逗号“,”分割开。
就像object规则一样,array规则也是一个逗号分割的序列,并且由中括号构成符号约束。
| 循环对抗尾递归 |
| JSON参考手册中的members规则看起来非常奇怪,因为它看起来并没有直接像描述的那样“由一系列的逗号分割开的pair组成”,并且,它引用到了自己。 members pair pair , members 会有这样的差别,是因为ANTLR支持扩展的BNF语法(EBNF),而JSON中的规则遵循的是直接的BNF语法。BNF并不支持像“(…)*”这样的循环结构,所以,其使用尾递归(在规则的一个选项中的最后一个元素调用自己)来实现这种循环。 为了更好地说明文字描述的规则和这种尾递归形式之间的区别,下面是members规则匹配1个,2个,3个pair的例子: members => pair
members => pair , members => pair , pair
members => pair , members => pair , pair , members => pair , pair , pair 这一现象体现了我们在5.2节给出的警告,现有的语法只能作为一个参考,而不能将其作为绝对真理来使用。 |
|
|
examples/JSON.g4
array
: '[' value (','value)*']'
| '[' ']' // empty array
;
再继续往下走,我们就得到了规则value,这个规则在参考手册中北描述为一种选项模式。
value可以是一个用双引号引起来的字符串,或者是一个数字,或者是true和false,或者是null,或者是一个object,或者是一个array。这些结构可以嵌套。
其中的术语嵌套自然就是指我们的嵌套短语模式,这也就意味着我们需要使用一些递归的规则引用。在ANTLR中,value规则看起来像图4所展示的那样。
通过引用object或array规则,value规则就变成了(非直接)递归规则。不管调用value中的object规则还是array规则,最终都会再次调用到value规则。
examples/JSON.g4
value
:STRING
|NUMBER
|object // recursion
|array // recursion
| 'true' // keywords
| 'false'
| 'null'
;
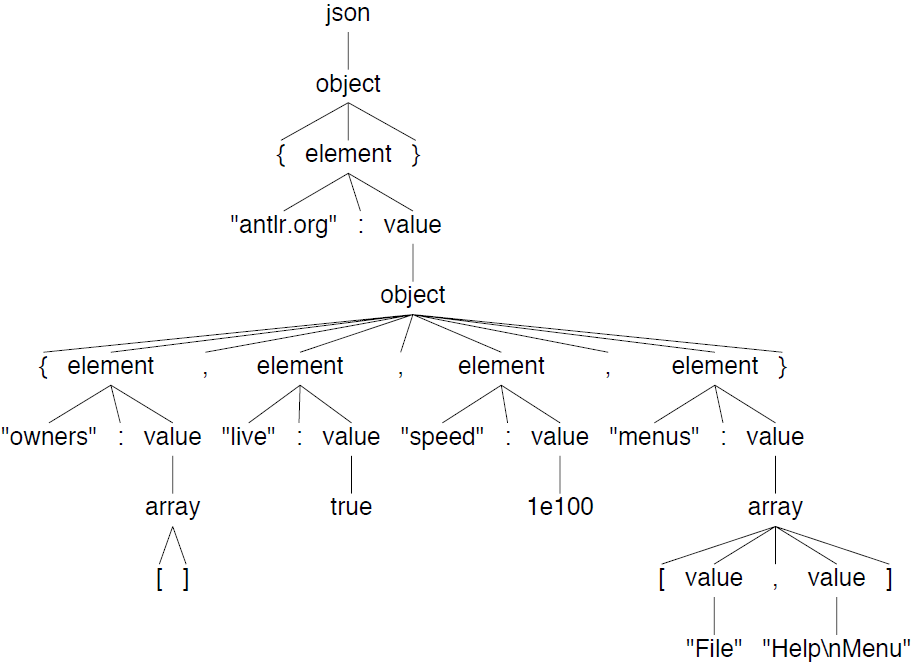
图4 ANTLR中的value规则
value规则直接引用字符串来匹配JSON的关键字。我们同样将数字作为一个符号来处理,这是因为我们的程序同样只需要将数字作为整体来处理。
这就是所有的语法规则了。我们已经完全指定了一个JSON文件的结构了。下面是针对之前给出的例子,我们的语法分析树的样子:
当然,我们在完成词法之前是无法生成上面所示的这棵语法树的。我们需要为STRING和NUMBER这两个关键字指定规则。
JSON词法规则
在JSON的参考手册中,字符串是这么被定义的:
字符串(string)是由零个或多个Unicode字符组成的序列,被双引号括起来,可以使用反斜杠转义字符。单个字符可以被看成只有一个字符的字符串。JSON中的字符串和C语言或Java中的字符串非常相似。
看吧,就像我们在上一章讨论的那样,字符串在大部分语言中都是非常相似的。JSON中的字符串与我们之前讨论过的字符串非常相似,只是需要添加对Unicode转义字符的支持。看一下现有的JSON语法,我们能看出其描述是不完整的。语法描述如下所示:
char
any-Unicode-character-except-"-or-\-or-control-character
\"
\\
\/
\b
\f
\n
\r
\t
\u four-hex-digits
这个语法定义了所有的转义字符,也定义了我们需要匹配除了双引号和反斜杠之外的所有Unicode字符。这种匹配,我们可以使用“~[“\\]”来反转字符集。(“~”操作符代表“除了”。)我们的STRING规则定义如下所示:
examples/JSON.g4
STRING : '"' (ESC |~["\\])* '"' ;
ESC规则既可以匹配一个预定义的转义字符,也可以匹配一个Unicode序列。
examples/JSON.g4
fragment ESC :'\\' (["\\/bfnrt] | UNICODE) ;
fragment UNICODE : 'u' HEX HEX HEX HEX ;
fragment HEX : [0-9a-fA-F] ;
我们将UNICODE规则中的十六进制数单独提取出来,成为一个HEX规则。(规则的前面如果加上fragment前缀的话,这条规则就只能被其它规则引用,而不会单独被匹配成符号。)
最后一个需要的符号就是NUMBER。JSON手册中是这么定义数字的:
数字(number)非常类似于C语言或Java中的数字,但是JSON中不使用八进制或十六进制的数字。
JSON的语法中有相当复杂的数字的规则,但是我们可以把这些规则总结成三个主要的选项。
examples/JSON.g4
NUMBER
: '-'? INT '.'INTEXP? // 1.35, 1.35E-9, 0.3, -4.5
| '-'? INT EXP // 1e10 -3e4
| '-'? INT // -3, 45
;
fragment INT :'0' | [1-9] [0-9]* ; // no leading zeros
fragment EXP :[Ee] [+\-]? INT ;// \- since - means "range"inside [...]
这里再说明一次,使用片段规则INT和EXP可以减少代码重复率,并且可以提高语法的可读性。
我们从JSON的非正式语法中可以得知,INT不会匹配0开始的整数。
int
digit
digit1-9 digits
- digit
- digit1-9 digits
我们在NUMBER中已经很好地处理了“-”符号操作符,所以我们只需要好好关注开头的两个选项:digit和digit1-9 digits。第一个选项匹配任何单个数码的数字,所以可以完美匹配0。第二个选项说明数字的开始只能是1到9,而不能是0。
译者注:依照本书中所写的JSON的NUMBER规则,则像1.03这样的输入不会被正确匹配,这一点有待于证实。
不同于上一节中的CSV的例子,JSON需要考虑空白字符。
空白字符(whitespace)可以出现在任何键值对的符号之间。
这是对空白字符的非常经典的定义,所以,我们可以直接利用前面“词法新人工具包”中的语法。
examples/JSON.g4
WS : [ \t\n\r]+ -> skip ;
现在,我们有JSON的完整的语法和词法规则了,接下来让我们测试下。以样例输入“[1,”\u0049”,1.3e9]”为例,测试其符号分析结果如下:
➾$ antlr4 JSON.g4
➾$ javac JSON*.java
➾$ grun JSON json -tokens
➾[1,"\u0049",1.3e9]
➾EOF
< [@0,0:0='[',<5>,1:0]
[@1,1:1='1',<11>,1:1]
[@2,2:2=',',<4>,1:2]
[@3,3:10='"\u0049"',<10>,1:3]
[@4,11:11=',',<4>,1:11]
[@5,12:16='1.3e9',<11>,1:12]
[@6,17:17=']',<1>,1:17]
[@7,19:18='<EOF>',<-1>,2:0]
可以看出,词法分析器正确地将输入流切分成符号流了,接下来,再试试看语法规则的测试结果。
➾$ grun JSON json -tree
➾[1,"\u0049",1.3e9]
➾EOF
<(json (array [ (value 1) , (value"\u0049") , (value 1.3e9) ]))
语法成功地被解释为含有三个值的数组了,如此看来,一切工作正常。要此时一个更加复杂的语法,我们需要测试更多的输入才能保证其正确性。
到目前为止,我们已经实践了两个数据语言的语法了(CSV和JSON),下面,让我们尝试下一个叫做DOT的声明式语言,这个实践增加了语法结构的复杂性,同时引进了一种新的词法模式:大小写不敏感的关键字。
6.3 解析DOT
DOT是一种用来描述图结构的声明式语言,用它可以描述网络拓扑图,树结构或者是状态机。(之所以说DOT是一种声明式语言,是因为这种语言只描述图是怎么连接的,而不是描述怎样建立图。)这是一个非常普遍而有用的图形工具,尤其是你的程序需要生成图像的时候。例如,ANTLR的-atn选项就是使用DOT来生成可视化的状态机的。
先举个例子感受下这个语言的用途,比如我们需要将一个有四个函数的程序的调用树进行可视化。当然,我们可以用手在纸上将它画出来,但是,我们可以像下面那样用DOT将它们之间的关系指定出来(不管是手画而是自动生成,都需要从程序源文件中计算出函数之间的调用关系):
examples/t.dot
digraph G{
rankdir=LR;
main [shape=box];
main -> f -> g; // main calls f which calls g
f -> f [style=dotted] ; // f isrecursive
f -> h; // f calls h
}
下图是使用DOT的可视化工具graphviz生成的图像结果:
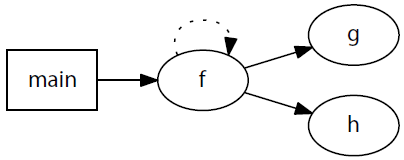
幸运的是,DOT的参考手册中有我们需要的语法规则,我们几乎可以将它们全部直接引用过来,翻译成ANTLR的语法就行了。不幸的是,我们需要自己指定所有的词法规则。我们不得不通读整个文档以及一些例子,从而找到准确的规则。首先,让我们先从语法规则开始。
DOT的语法规则
下面列出了用ANTLR翻译的DOT参考手册中的核心语法:
examples/DOT.g4
graph : STRICT? (GRAPH | DIGRAPH) id? '{'stmt_list '}' ;
stmt_list : ( stmt ';'? )* ;
stmt : node_stmt
|edge_stmt
|attr_stmt
| id '=' id
|subgraph
;
attr_stmt : (GRAPH | NODE | EDGE) attr_list ;
attr_list : ('[' a_list?']')+ ;
a_list : (id ('=' id)?','?)+ ;
edge_stmt : (node_id | subgraph) edgeRHS attr_list? ;
edgeRHS : ( edgeop (node_id | subgraph) )+ ;
edgeop : '->' | '--';
node_stmt : node_id attr_list? ;
node_id : id port? ;
port : ':' id (':'id)? ;
subgraph : (SUBGRAPH id?)? '{' stmt_list '}' ;
id : ID
|STRING
|HTML_STRING
|NUMBER
;
其中,唯一一个和参考手册中语法有点不同的就是port规则。参考手册中是这么定义这个规则的。
port: ':' ID [ ':' compass_pt ]
| ':' compass_pt
compass_pt
: (n | ne | e | se| s | sw | w | nw)
如果说指南针参数是关键字而不是合法的变量名,那么这些规则这么写是没问题的。但是,手册中的这句话改变了语法的意思。
注意,指南针参数的值并不是关键字,也就是说指南针参数的那些字符串也可以当作是普通的标识符在任何地方使用…
这意味着我们必须接受像“n ->sw”这样的边语句,而这句话中的n和sw都只是标识符,而不是指南针参数。手册后面还这么说道:“…相反的,编译器需要接受任何标识符。”这句话说的并不明确,但是这句话听起来像是编译器需要将指南针参数也接受为标识符。如果真是这样的话,那么我们也不用去考虑语法中的指南针参数;我们可以直接用id来替换规则中的compass_pt就可以了。
port: ':' id (':'id)? ;
为了验证我们的假设,我们不妨用一些DOT的查看器来尝试下这个假设,比如用Graphviz网站上的一些查看器。事实上,DOT也的确接受下面这样的图的定义,所以我们的port规则是没问题的:
digraph G { n -> sw; }
现在,我们的语法规则已经就位了,假设我们的词法定义也实现了,那么我们来看看t.dot这个样例输入的语法分析树长什么样子(使用grun DOT graph -gui t.dot)。
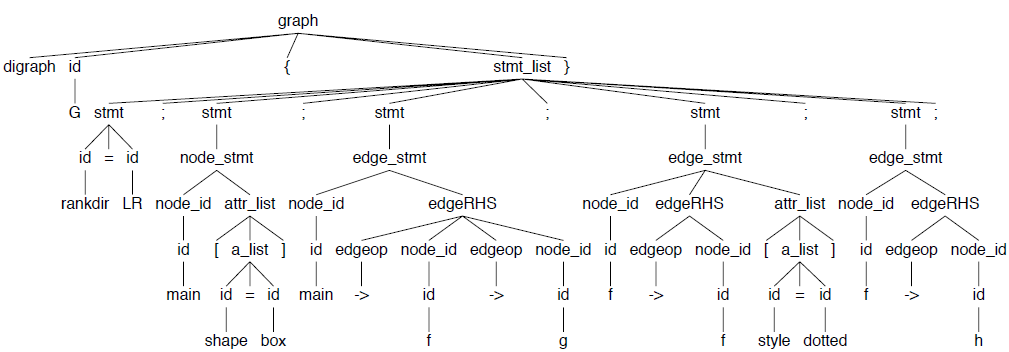
好,让我们接下来定义词法规则。
DOT词法规则
由于手册中没有提供正式的词法规则,我们只能自己从文本描述中提取出词法规则。关键字非常简单,所以就让我们从关键字开始吧。
手册中是这么描述的:“node,edge,graph,digraph,subgraph,strict关键都是大小写不敏感的。”如果它们是大小写敏感的话,我们只需要简单地将单词列出来就可以了,比如’node’这样。但是为了接受像’nOdE’这样多种多样的输入,我们需要将词法规则中的每个字母都附上大小写。
examples/DOT.g4
STRICT : [Ss][Tt][Rr][Ii][Cc][Tt] ;
GRAPH : [Gg][Rr][Aa][Pp][Hh] ;
DIGRAPH :[Dd][Ii][Gg][Rr][Aa][Pp][Hh] ;
NODE : [Nn][Oo][Dd][Ee] ;
EDGE : [Ee][Dd][Gg][Ee] ;
SUBGRAPH :[Ss][Uu][Bb][Gg][Rr][Aa][Pp][Hh] ;
标识符的定义和大多数编程语言中的定义一致。
标识符由任何字母([a-zA-Z\200-\377]),下划线和数字组成,且不能以数字开头。
\200-\377是八进制范围,用十六进制范围表示就是80到FF,所以,我们的ID规则看起来就应该像这样:
examples/DOT.g4
ID : LETTER (LETTER|DIGIT)*;
fragment
LETTER : [a-zA-Z\u0080-\u00FF_] ;
辅助规则DIGIT同时也是我们在匹配数字的时候需要用到的一个规则。手册中说,数字遵循下面这个正则表达式:
[-]?(.[0-9]+ | [0-9]+(.[0-9]*)? )
把其中的[0-9]替换成DIGIT,那么DOT中的数字规则就如下所示:
examples/DOT.g4
NUMBER : '-'? ('.'DIGIT+ | DIGIT+ ('.' DIGIT*)? ) ;
fragment
DIGIT : [0-9] ;
DOT的字符串非常的寻常。
双引号引起来的任何字符序列(”…”),包括转义的引号(\”),就是字符串。
我们使用点通配符来匹配双引号内部的任意字符,直到遇到结束字符串的双引号为止。当然,我们也将转义的双引号作为子规则循环中的一个选项进行匹配。
examples/DOT.g4
STRING : '"' ('\\"'|.)*?'"' ;
DOT同时也支持HTML字符串。尽可能简单地说,HTML字符串就是双引号内部的字符串还用尖括号括起来的字符串。手册中使用“<…>”符号,并这样描述:
…在HTML字符串中,尖括号必须成对匹配,并且允许非转义的换行符。另外,HTML字符串的内容必须符合XML标准,所以一些特殊的XML转义序列(”,&,<,>)可能就会非常重要,因为我们可能会需要将其嵌入到属性值或原始文本中。
这段描述告诉了我们大部分我们需要的信息,但是却没有说明我们是否可以在HTML元素内部使用尖括号。这似乎意味着我们可以在尖括号中这样包含字符序列:“<<i>hi</i>>”。从用DOT查看器来做实验的结果来看,事实确实是这样的。DOT似乎允许尖括号之间出现任何字符串,只要括号匹配就行。所以,出现在HTML元素内部的尖括号并不会像其它XML解析器那样被忽略掉。HTML字符串“<foo<!--ksjdf > -->>”就会被看成是“foo<!--ksjdf> --”。
要实现HTML字符串,我们可以使用“'<'.*? '>'”这种结构。但是这种结构不能支持尖括号的嵌套,因为这种结构会将第一个“>”与第一个“<”进行结合,而不是与它最近的“<”结合。下面的规则实现了这种嵌套:
examples/DOT.g4
/** "HTML strings, angle brackets must occur in matchedpairs, and
* unescaped newlines are allowed."
*/
HTML_STRING : '<' (TAG|~[<>])*'>' ;
fragment
TAG : '<' .*? '>';
HTML_STRING规则允许出现带有一对尖括号的TAG规则,实现了标签的单层嵌套。“~[<>]”字符集要小心匹配XML字符实体,比如<。这个集合匹配除了左右尖括号以外的所有字符。我们不能在这里使用非贪婪循环的通配符。“(TAG|.)*?”会匹配像“<<foo>”这样的无效输入,因为循环内部的通配符是可以匹配上“<foo”的。在非贪婪模式下,HTML_STRING就不会调用TAG去匹配一个标签或这标签的一部分。
你可能会试着去用递归来匹配尖括号嵌套,就像这样:
HTML_STRING : '<' (HTML_STRING|~[<>])*'>' ;
但是,这样仅仅会匹配嵌套标签,而不会去平衡标签的起始和结束的位置。嵌套标签可以匹配这样的输入:“<<i<br>>>”,但是这并不是我们应该接受的输入。
DOT还有最后一种我们之前没有见过的词法结构。DOT匹配并丢弃以“#”符号开头的行,因为DOT将其认为是C语言的预处理器输出。我们可以将其作为单行的注释规则来看待。
examples/DOT.g4
PREPROC : '#' .*? '\n'-> skip ;
以上就是DOT的语法(除了一些我们已经非常熟悉的规则以外)。这是我们实现的第一个比较复杂的语法!先不管那些更复杂的语法和词法结构,这一章主要强调了我们应该查阅多方面的资源来实现一个完整的语言。语言结构越庞大,我们需要的参考资源和代表性输入就需要越多。有时候翻出一些现有的实现程序才是我们测试边缘情况的唯一方法。没有任何的语言手册会是完美无缺的。
我们也经常要面临一些选择,在语法分析过程中怎样划分才是合理的,哪些又是需要作为分割短语而稍后进行处理的。举个例子,我们在处理特殊的port的名称的时候,比如ne和sw,就是将其作为简单的标识符传递给语法分析器。同时,我们也不去翻译“<…>”内部的HTML信息。从某些方面来说,一个完整的DOT实现应该识别并处理这些HTML元素,但是语法分析器只需要将其视为一整块就可以了。
下面,是时候尝试一些编程语言了。在下一节,我们要建立一个传统的命令式编程语言的语法(比较像C语言)。然后,我们就要开始我们最大的挑战,实现一个函数式编程语言,R语言。
6.4 解析Cymbol
接下来我们主要说明如何解析从C语言衍生过来的编程语言,我们要实现一个我设计的语言,叫做Cymbol。Cymbol是一个很简单的,不支持对象的编程语言,它看起来就像是没有structs的C语言。如果你懒得去从头到尾设计一门新的语言,你可以将这个语言的语法作为其它新的编程语言的原型。在这里面,我们不会看到新的ANTLR语法,但是我们的语法将实践怎样建立简单的左递归表达式规则。
当我们设计新语言的时候,我们就没有正式语法或语言手册来参考了。相反的,我们从建立语言的样例输入开始。从这里开始,我们就要像5.1节中说的那样来衍生一个语言的语法了。(当我们要处理一些没有官方语法规范或参考手册的现有语言的时候也可以这么做。)下面是一个Cymbol代码的例子,其中包括全局变量的声名以及递归函数的声明:
examples/t.cymbol
// Cymbol test
int g = 9; // a global variable
int fact(int x) { // factorial function
if x==0 then return 1;
return x * fact(x-1);
}
为了直观,我们先看看程序的最终效果,从而可以对程序的任务有一个更好的把握。下面的语法树展示了我们的程序应该怎样解析输入程序(通过grun Cymbol file -gui t.cymbol命令):
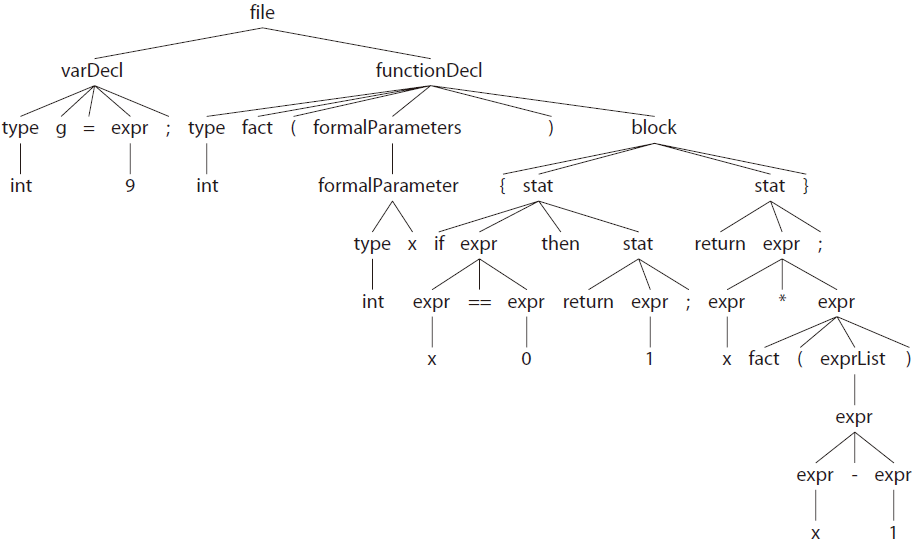
从最高的层次上来考虑Cymbol程序,我们可以发现其是由一系列的全局变量和函数声明组成的。
examples/Cymbol.g4
file: (functionDecl | varDecl)+ ;
变量的声明和C语言十分类似,是由一个类型说明符后面跟上一个标识符组成的,这个标识符后面还可以选择出现初始化表达式。
examples/Cymbol.g4
varDecl
: typeID ('=' expr)?';'
;
type: 'float' | 'int'| 'void' ; // user-defined types
函数声明也基本是相同的:类型说明符,后面跟一个函数名,后面跟一个括号括起来的参数列表,后面跟一个函数体。
examples/Cymbol.g4
functionDecl
: typeID '(' formalParameters?')'block // "void f(int x) {...}"
;
formalParameters
:formalParameter (',' formalParameter)*
;
formalParameter
: typeID
;
函数体其实就是由花括号括起来的语句块。这里,我们考虑以下6种不同的语句:嵌套语句,变量声明,if语句,return语句,赋值语句以及函数调用。这6种语句用ANTLR语法来写如下所示:
examples/Cymbol.g4
block: '{' stat* '}' ; // possibly empty statement block
stat: block
|varDecl
| 'if' expr 'then'stat ('else' stat)?
| 'return' expr? ';'
| expr '=' expr ';' // assignment
| expr ';' // func call
;
最后一个主要的语法就是表达式语法了。因为Cymbol只是创建其它编程语言的原型,所以我们在表达式中只考虑一些常见的运算符。我们要处理的运算符有:一元取反,布尔非,乘法,加法,减法,函数调用,数组下标,等值比较,变量,整数以及括号表达式。
examples/Cymbol.g4
expr: ID '(' exprList?')'// func call like f(), f(x), f(1,2)
| expr '[' expr ']' // array index like a[i], a[i][j]
| '-' expr // unary minus
| '!' expr // boolean not
| expr '*' expr
| expr ('+'|'-') expr
| expr '==' expr // equality comparison (lowest priority op)
| ID // variable reference
| INT
| '(' expr ')'
;
exprList : expr (',' expr)* ; // arg list
在这里我们需要注意的是,我们需要根据优先级从高到低列出每一条选项。(在第14章会详细讨论ANTLR是怎样处理左递归以及符号优先级的。)
更直观一些来看优先级的处理,我们可以看看输入“-x+y;”和“-a[i];”的语法分析树(为了直观,规则从stat开始分析)。
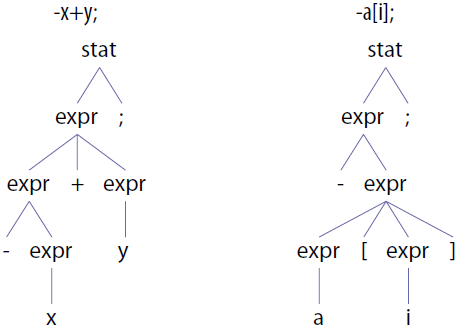
左边的语法树显示了一元减符号会先和x结合,因为其优先级比加号要高。这是因为,在语法中,一元减符号选项在加号选项之前出现。在右边的语法树中,一元减符号的优先级要比取数组下标符号低,这是因为一元减符号选项出现在取数组下标符号选项的后面。右边的语法树清楚地表明,负号是作用在“a[i]”上的,而不是作用在标识符“a”上面的。在下一节,我们会看到一些更复杂的表达式。
我们暂时不去关注这个语言的词法规则,因为词法规则都和前面的差不多。这里,我们关注的焦点应该是命令式编程语言中的语法结构。
我们可以想象一下无结构体或无类和对象的Java语言是什么样子的,这样有助于我们建立我们的Cymbol语言。并且,如果这个语法你已经理解得十分透彻的话,你可以尝试着去创建你自己的更复杂的命令式编程语言了。
接下来,我们要去尝试另一个极端的语言。要实现一个差不多的R语言,我们不得不推导出非常精确的语言结构。我们可以通过参考多个手册,测试样例程序以及在现有的一些R编译器上进行测试的方法来推导其语言结构。
6.5 解析R
R语言是在统计问题领域内非常有表现力的一个编程语言。例如,R语言非常容易创建向量,并支持函数对向量操作以及对向量进行过滤(下面展示了一些R的交互脚本)。
➾x <- seq(1,10,.5) # x = 1, 1.5, 2, 2.5, 3, 3.5, ..., 10
➾y <- 1:5 #y = 1, 2, 3, 4, 5
➾z <- c(9,6,2,10,-4) # z = 9, 6, 2, 10, -4
➾y + z #add two vectors
<[1] 10 8 5 14 1 # result is 1-dimensionalvector
➾z[z<5] #all elements in z < 5
<[1] 2 -4
➾mean(z) #compute the mean of vector z
<[1] 4.6
➾zero <- function() { return(0) }
➾zero()
<[1] 0
R语言是一个中小型但是却又十分复杂的编程语言,并且大部分人都有一个障碍存在:我们都不了解R语言。这意味着我们不可能像写Cymbol那样直接凭着直觉来编写R语言的语法结构了。我们不得不根据大量的文献资料、例子,以及一个现有实现中的正式的yacc语法来获取R语言的准确语法结构。
开始之前,最好先看一些R语言的语言概述。同时,我们最好也看一些R语言的例子,从而对R语言有一个更好的把握,并从中选择一些作为成功测试的例子。Ajay Shah已经建立了一些挺不错的例子,我们可以直接使用。能够成功解析这些例子就表明我们能够处理大部分的R程序了。(在不了解一门语言的前提下要完美实现一门语言怎么想都是不可能。)在R语言的官网主页上有许多能够帮助我们建立R语言的文档,这里我们着重关注于“R-intro”和语言定义文档“R-lang”。
和前面的一样,我们从一个非常粗糙的层次开始我们的语法结构。从语言概述中可以得知,R程序就是由一系列的表达式和赋值语句组成的。就算是函数定义也是赋值语句;我们将一个函数赋值给一个变量。唯一我们不熟悉的就是R语言中有三种赋值操作符:<-,=,以及<<-。我们的目的只是建立解析器,所以我们不需要关心这三种操作符的意义。所以我们程序的第一个主要结构就应该看起来这样:
prog : (expr_or_assign '\n')* EOF ;
expr_or_assign
: expr ('<-' | '=' | '<<-' ) expr_or_assign
| expr
;
在读了一些例子之后,我们发现,在同一行内我们可以同时书写多个表达式,只要用分号分开它们就可以了。“R-intro”中证实了这一点。同时,虽然手册中没有写,但是R编译器允许并忽略空行。所以,我们需要根据这些规定来调整我们的起始规则。
examples/R.g4
prog: ( expr_or_assign (';'|NL)
| NL
)*
EOF
;
expr_or_assign
: expr('<-'|'='|'<<-') expr_or_assign
| expr
;
为了考虑到Windows下的换行符(\r\n),我们使用NL来作为换行符,而不是直接使用’\n’符号,这个我们在之前定义过。
examples/R.g4
// Match both UNIX and Windows newlines
NL : '\r'? '\n' ;
注意,NL并不像前面那样可以直接丢弃。因为语法解析器同时需要将其作为表达式的终结符,就像Java语法中的分号一样,所以,词法分析器必须将其传递给语法分析器。
R语言的主体部分就是表达式,所以我们接下来关注的重点也在表达式上。R语言中主要有三种不同的表达式:语句表达式,操作符表达式和函数关联表达式。由于R语言的语句和命令式编程语言非常接近,所以就让我们先从语句表达式开始入手。下面是处理expr规则的语句选项(expr规则中出现在运算符选项后面的):
examples/R.g4
| '{' exprlist'}' // compound statement
| 'if' '(' expr ')' expr
| 'if' '(' expr ')' expr 'else' expr
| 'for' '(' ID 'in' expr ')' expr
| 'while' '(' expr ')' expr
| 'repeat' expr
| '?' expr // get help on expr, usually string or ID
| 'next'
| 'break'
根据“R-intro”中描述,第一个选项匹配的是表达式块。“R-intro”中是这么描述的:“基础命令可以通过花括号组合成符合表达式。”下面是exprlist的定义:
examples/R.g4
exprlist
:expr_or_assign ((';'|NL)expr_or_assign?)*
|
;
大部分的R表达式需要处理非常多的运算符。为了获得这些表达式的准确定义,我们最好的方法就是参考其yacc语法。可执行的代码通常(但不是所有的都这样)是了解语言作者意图的最好方式。要知道运算符的优先级,我们首先需要看一些运算符优先级表,优先级表列出了所有相关的运算符的优先级。例如,下面是yacc语法中对算术运算符的描述(用“%left”列在前面的表示优先级比较低):
%left '+' '-'
%left '*' '/'
“R-lang”文档中有一节叫做“中缀和前缀操作符”,在这一节中给出了运算符的优先级规则,但是,这一节中似乎没有关于“:::”运算符的描述,而其却能在yacc语法中找到。将这些信息全部合起来,我们就能得到下面这些针对二元运算符,前缀运算符以及后缀运算符的规则了:
examples/R.g4
expr: expr '[[' sublist']' ']' // '[[' follows R'syacc grammar
| expr'[' sublist ']'
| expr('::'|':::') expr
| expr('$'|'@') expr
| expr'^'<assoc=right> expr
| ('-'|'+') expr
| expr':' expr
| exprUSER_OP expr // anything wrappedin %: '%' .* '%'
| expr('*'|'/') expr
| expr('+'|'-') expr
| expr ('>'|'>='|'<'|'<='|'=='|'!=') expr
| '!' expr
| expr('&'|'&&') expr
| expr('|'|'||') expr
| '~' expr
| expr'~' expr
| expr ('->'|'->>'|':=') expr
我们只是想识别输入的话,就暂时不用管这些操作符到底是什么意思。我们只需要关心我们的语法是否能正确匹配优先级和结合顺序。
在上面的expr的规则中,有一种用法我们不常用到,那就是在第一条选项中(expr ‘[[‘ sublist ‘]’ ‘]’)使用’[[‘来代替’[‘ ’[‘。([[…]]的作用是选择一个单个元素,其中的[…]用于产生一个子列表。)我直接从R语言的yacc语法中抄过来的’[[‘这种表述,这样写法大概是要表明两个左中括号之间不能有空白字符,但是这一点在参考手册中并没有任何说明。
“^”运算符跟了一个后缀“<assoc=right>”,这是因为“R-lang”中这样指定了这个运算符:
幂运算符“^”和左赋值运算符“<-= <<-”的结合顺序是从右到左的,剩下的其它运算符都是从左到右结合的。例如,2^2^3的结果应该是2^8,而不是4^3。
语句和运算符表达式都搞定之后,我们可以开始着手我们的最后一个expr规则的构成部分了:定义以及调用函数。我们可以使用下面的两个选项:
examples/R.g4
| 'function' '(' formlist?')' expr // define function
| expr '(' sublist')' // call function
formlist和sublist分别定义了声明过程中的形式参数列表和调用过程中的实际参数列表。我将规则的名字和yacc语法中的规则名字保持一致,这样可以方便我们对比这两种语法。
在“R-lang”中,形式参数列表是这样表述的:
…由逗号分隔开来,其中的每一项可以是一个标识符,也可以是“标识符 = 默认值”这种形式,或者是一个特殊的标记“…”。默认值可以是任何一个有效的表达式。
用ANTLR语法来表述这一点和yacc语法中的formlist比较相似(见图5)。
examples/R.g4
formlist : form (',' form)* ;
form: ID
| ID '=' expr
| '...'
;
图5 formlist的ANTLR表述
下面,要调用一个函数,“R-lang”描述的参数列表语法如图6所示。
每一个参数都可以进行标记(标记名=表达式),或者只是一个简单的表达式。同时,参数也可以为空,或者是一些特殊的符号,比如’…’,’..2’等。
图6 调用函数时的参数语法
偷看一下yacc语法中的这一部分,我们对参数的语法就有更明确的认识;yacc语法中表明了,我们也可以使用像“”n”=0”,“n=1”以及“NULL=2”这样的写法。结合这些规范,我们就得到了下面的函数调用参数的规则:
examples/R.g4
sublist : sub (',' sub)* ;
sub : expr
| ID '='
| ID '=' expr
| STRING'='
|STRING '=' expr
| 'NULL' '='
| 'NULL' '=' expr
| '...'
|
;
你可能会奇怪,在sub规则中怎么去匹配像“..2”这样的输入。其实,我们并不需要精确地去匹配这些,因为我们的词法分析器会将其识别成标识符。根据“R-lang”所描述的那样:
标识符是由字母,数字,小数点(“.”)和下划线组成。标识符不能以数字或下划线打头,也不能以一个小数点后面跟数字打头。…注意,以小数点打头的标识符(比如“…”以及“..1”,“..2”等)都具有特殊意义。
为了表述上面描述的标识符,我们使用下面的标识符规则:
examples/R.g4
ID : '.' (LETTER|'_'|'.')(LETTER|DIGIT|'_'|'.')*
|LETTER (LETTER|DIGIT|'_'|'.')*
;
fragment LETTER: [a-zA-Z] ;
第一个选项指定了以小数点开头的标识符,我们不得不保证第二个字符不能是数字。对于这一点,我们可以使用子规则“(LETTER|’_’|’.’)”来实现。为了确保标识符不会以数字或者下划线开头,我们在第二个选项中使用了辅助规则LETTER。要匹配“..2”这样的输入,我们使用第一个选项就可以了。其中第一个小数点匹配第一个子规则“’.’”,第二个小数点匹配第二个子规则“(LETTER|’_’|’.’)”,而最后一个子规则匹配了数字“2”。
词法规则的剩余部分和我们之前写过的那些规则大同小异,所以我们在这里就不再讨论它们了。
下面,让我们使用grun来测试下目前为止我们的所有工作吧,测试输入如下:
examples/t.R
addMe <- function(x,y) { return(x+y) }
addMe(x=1,2)
r <- 1:5
下面是针对输入t.R如何建立可视化语法树的过程(语法树见图7):
$ antlr4 R.g4
$ javac R*.java
$ grun R prog -gui t.R
只要我们将表达式写在一行里面,我们的R语法就能工作得很好。然而,这样的假设不合适,因为R语言允许函数或其他表达式拆成多行编写。尽管如此,我们将先止步于此,因为我们的目的仅仅是了解R语言的语法结构。在code/extras资源目录中,你可以找到忽略表达式中间的换行符这个小问题的解决方案(参见R.g4,RFilter.g4以及TestR.java)。这个解决方案会根据语法适当地选择保留或剔除换行符。
这一章中,我们的目的是巩固我们的ANTLR语法的知识,并学习如何从语言参考手册、样例输入和现有非ANTLR语法中派生语法。最后,我们实现了两个数据语言(CSV,JSON),一个声明式语言(DOT),一个命令式语言(Cymbol)和一个函数式语言(R)。对于建立一个中等复杂的语言,这些例子几乎覆盖了所有你需要的技能。在你开始继续学习之前,我建议最好先下载这些语法,并有针对性地做些小小的修改,从而巩固新学到的知识。例如,你可以给Cymbol语言添加更多的运算符和语句。然后,可以使用TestRig工具来查看你修改后的语法是怎样工作在样例输入上的。
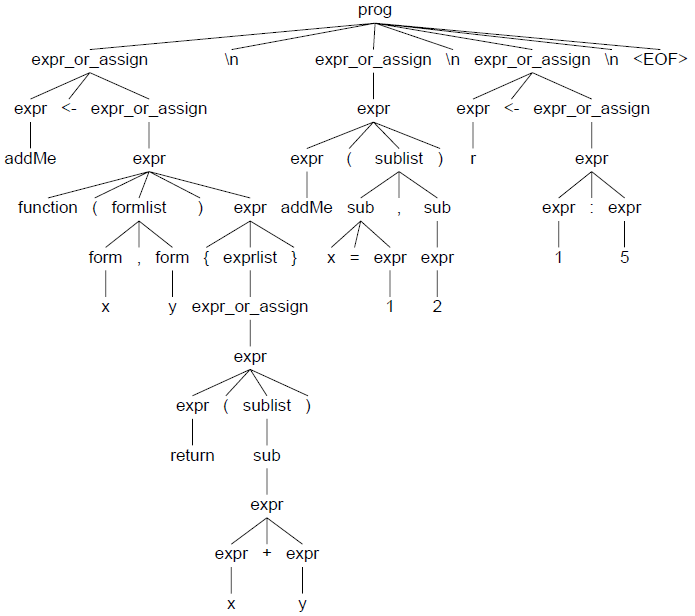
图7 t.R的语法分析树
到目前为止,我们已经学习了怎样识别语言,但是,语法本身必须还能识别只符合语言本身的输入。下面,我们将学习如何在解析机制中加入特定应用程序的代码,这将在下一章具体介绍。完成这个之后,我们就可以试着建立真正的语言应用程序了。














 1649
1649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









