







 本文介绍了递归下降分析器的工作原理,特别是LL(1)算法,以及如何处理右递归。接着深入讨论了左递归的概念,包括直接左递归和间接左递归,并提供了消除左递归的方法。通过计算FIRST和FOLLOW集合,展示了如何将左递归转化为右递归,以适应LL(1)解析器。最后提到了ANTLR4在解决左递归方面的作用。
本文介绍了递归下降分析器的工作原理,特别是LL(1)算法,以及如何处理右递归。接着深入讨论了左递归的概念,包括直接左递归和间接左递归,并提供了消除左递归的方法。通过计算FIRST和FOLLOW集合,展示了如何将左递归转化为右递归,以适应LL(1)解析器。最后提到了ANTLR4在解决左递归方面的作用。
在介绍递归文法之前,首先介绍一下递归下降分析器及其原理,然后分析右递归是如何处理的,再来分析左递归和间接左递归。
递归下降分析器
自顶向下语法分析的目的是为输入串寻找最左推导,或者说,从根节点(文法开始符号)开始,自上而下,从左到右地为输入字符串建立一棵分析树,并以预先确定的顺序创建分析树的节点。这种自顶向下分析的一般形式,称之为递归下降分析法。“下降”表示自顶向下,“递归”表示可能会调用自身。
在递归下降分析器中,最简单的一种,就是 LL(1) 递归下降分析器。我们尝试来构造一个简单的满足 LL(1) 的递归下降语法分析器。语法结构如下
stat : assign_stat
| ifstat
| return_stat
;
assign_stat : ID '=' expr ;
ifstat : IF expr THEN stat ;
return_stat : RETURN expr ;
expr : ID '<' NUM
| NUM
;
当我们解析 if x < 0 then x = 0 这句语句时,会构造成如图 4-1 所示的解析树
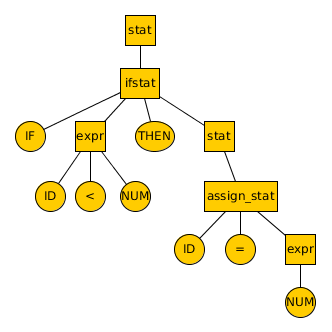
解析树里面含有语句的所有语法结构的信息。而解析就是将线性的词法单元序列组成带有结构的解析树。
语法解析器能检查句子的结构是否符合语法规范(语言实际上就是合法句子的集合)。为了验证句子是否合法,解析器必须识别句子的解析树。不过解析器实际上并不需要构造出形式上的树型结构,只要识别出各种句子结构和相关的词法单元即可。解析器不必构造出具体的解析树,只要为解析树中的指定子结构编写专用的函数,就能从解析函数的调用序列中隐式的得到解析树的信息。比如函数 f(),在匹配其子节点时会调用相应的函数,而需要匹配词法单元时会调用 match() 的辅助函数。顺着这条思路,可以为 return x+1 这条语句编写如下的识别函数
void stat() {
returnstat(); }
void returnstat() {
match("return"); expr();}
void expr() {
match("x"); match("+"); match("1"); }
match() 函数将输入流里的词法单元与传入它的参数进行比较,然后将输入指针往前移动。但是对于 stat 语法分支,情况就会变得复杂,因为需要考虑到三种不同的情况,
void stat() {
if (超前扫描词法单元是 return) returnstat();
else if (超前扫描词法单元是 ID) assignstat();
else if (超前扫描词法单元是 IF) ifstat();
else 错误处理
}
这种自顶向下的语法解析器,从解析树的顶部开始,一直向下处理,直到叶子节点。
LL(1) 算法
LL(1)语法解析器,是一种相对来说最简单的自顶向下的语法解析器,两个 L 都表示 left-to-right,第一个 L 表示解析器按照从左到右的顺序解析输入内容,第二个 L 表示下降解析时也是按照从左到右的顺序遍历子节点。1 代表决定语法解析器的每一步动作时向前扫描一个词法单元。
正如上面构造出的简单的递归下降分析器,在 stat 中,如果是 ifstat 子句,我们会调用 ifstat() 函数,定义如下
void ifstat() {
match("if");
expr();
match("then");
stat();
}
在 ifstat 中,匹配到 then 后,后面还是一个 stat 子句,调用 stat 函数进行匹配。这里就是一个右递归。在 ifstat 匹配完成后,调用 stat 匹配 then 后面的部分。递归下降分析器通过调用自身,是可以处理右递归的。
左递归
对于形如
expr -> expr + term
这样的产生式,右部的最左符号与产生式左部的非终结符相同,这样的产生式即为左递归产生式。假定 expr 对应的过程要使用这个产生式,因为右部是由 expr 开始的,expr 过程会被递归调用,导致无限循环。只有右部终结符与超前扫描符号匹配时,超前扫描符号才会改变。这个产生式中,右部是以非终结符 expr 开始的,输入符号在递归调用期间没有机会改变,所以导致无限循环。
左递归如何消除
如果 文法 1 具有一个非终结符 A 使得对某个字符串 α \alpha α 存在推导
A ⟹ A α (文法1) A \implies A\alpha \tag {文法1} A⟹Aα(文法1)
则称 文法1 是左递归的。
考虑下面 文法2
A ⟹ B | a | C B D (1) A \implies \text{B | a | C B D} \tag 1 A⟹B | a | C B D(1)
B ⟹ C | b (2) B \implies \text{C | b} \tag 2 B⟹C | b(2)
C ⟹ A | c (3) C \implies \text{A | c} \tag 3 C⟹A | c(3)
D ⟹ d (4) D \implies d \tag 4 D⟹d(4)
由该文法能产生诸如 a, cbd 等的串。能够发现,该文法不是直接左递归的,因为并没有直接的类似于文法1一样的产生式。但是,文法 G 确实是左递归的,因为我们可以通过推导,获得
A ⟹ A | c | b | a | C B D A \implies \text{A | c | b | a | C B D} A⟹A | c | b | a | C B D
这就是左递归文法了。再来分析一下这个文法,计算一下文法的 FIRST 和 FOLLOW 集合。
在计算 FIRST 和 FOLLOW 集合之前,首先介绍一下这两个集合。
如果 α \alpha α 是任意的文法符号串,则我们定义 F I R S T ( α ) FIRST(\alpha) FIRST(α) 是从 α \alpha α 推导出的串的开始符号的终结符集合,即
F I R S T ( α ) = { a ∣ α ⟹ a ⋯ , a 是 终 结 符 } FIRST(\alpha) = \{a | \alpha \implies a \cdots,a 是终结符 \} FIRST(α)={
a∣α⟹a⋯,a是终结符}
如果
α ⟹ ϵ \alpha \implies \epsilon α⟹ϵ
则 ϵ \epsilon ϵ 也属于 F I R S T ( α ) FIRST(\alpha) FIRST(α) 。运用如下规则,来计算文法符号 X 的 FIRST(X) 集合,直到没有终结符或者 ϵ \epsilon ϵ 可加到某个 FIRST 集合为止
- 如果 X 是终结符,则 FIRST(X) 是 {X}
- 如果 X ⟹ ϵ X \implies \epsilon X⟹ϵ 是一个产生式,则将 ϵ \epsilon ϵ 加入到 FIRST(X) 中
- 如果 X 是非终结符,且 $ X \implies Y_1Y_2Y_3…Y_n$ 是一个产生式,则
- F I R S T ( Y i ) FIRST(Y_i) FIRST(Yi) 中所有符号在 FIRST(X) 中
- 若对于某个 i,a 属于 F I R S T ( Y i ) FIRST(Y_i) FIRST(Yi) 且 ϵ \epsilon ϵ 属于 F I R S T ( Y 1 ) FIRST(Y_1) FIRST(Y1) ,……。 F I R S T ( Y i − 1 ) FIRST(Y_{i-1}) FIRST(Yi−1) ,即 Y 1 . . . Y i − 1 ⟹ ϵ Y_1...Y{i-1} \implies \epsilon
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4577
4577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











