










本文只介绍原论文中的 Isolation Forest 孤立点检测算法的原理,实际的代码实现详解请参照我的另一篇博客:Isolation Forest算法实现详解。
或者读者可以到我的GitHub上去下载完整的项目源码以及测试代码(源代码程序是基于maven构建): https://github.com/JeemyJohn/AnomalyDetection。
前言
随着机器学习近年来的流行,尤其是深度学习的火热。机器学习算法在很多领域的应用越来越普遍。最近,我在一家广告公司做广告点击反作弊算法研究工作。想到了异常检测算法,并且上网调研发现有一个算法非常火爆,那就是本文要介绍的算法 Isolation Forest,简称 iForest 。
南大周志华老师的团队在2010年提出一个异常检测算法Isolation Forest,在工业界很实用,算法效果好,时间效率高,能有效处理高维数据和海量数据,这里对这个算法进行简要总结。
1. iTree的构造
提到森林,自然少不了树,毕竟森林都是由树构成的,看Isolation Forest(简称iForest)前,我们先来看看Isolation Tree(简称iTree)是怎么构成的,iTree是一种随机二叉树,每个节点要么有两个女儿,要么就是叶子节点,一个孩子都没有。给定一堆数据集D,这里D的所有属性都是连续型的变量,iTree的构成过程如下:
随机选择一个属性Attr;
随机选择该属性的一个值Value;
根据Attr对每条记录进行分类,把Attr小于Value的记录放在左女儿,把大于等于Value的记录放在右孩子;
然后递归的构造左女儿和右女儿,直到满足以下条件:
传入的数据集只有一条记录或者多条一样的记录;
树的高度达到了限定高度;

iTree构建好了后,就可以对数据进行预测啦,预测的过程就是把测试记录在iTree上走一下,看测试记录落在哪个叶子节点。iTree能有效检测异常的假设是:异常点一般都是非常稀有的,在iTree中会很快被划分到叶子节点,因此可以用叶子节点到根节点的路径h(x)长度来判断一条记录x是否是异常点;对于一个包含n条记录的数据集,其构造的树的高度最小值为log(n),最大值为n-1,论文提到说用log(n)和n-1归一化不能保证有界和不方便比较,用一个稍微复杂一点的归一化公式:
s(x,n) 就是记录x在由n个样本的训练数据构成的iTree的异常指数, s(x,n) 取值范围为[0,1]异常情况的判断分以下几种情况:
越接近1表示是异常点的可能性高;
越接近0表示是正常点的可能性比较高;
如果大部分的训练样本的 s(x,n) 都接近于0.5,说明整个数据集都没有明显的异常值。
由于是随机选属性,随机选属性值,一棵树这么随便搞肯定是不靠谱,但是把多棵树结合起来就变强大了;
2. iForest的构造
iTree搞明白了,我们现在来看看iForest是怎么构造的,给定一个包含n条记录的数据集D,如何构造一个iForest。iForest和Random Forest的方法有些类似,都是随机采样一部分数据集去构造每一棵树,保证不同树之间的差异性,不过iForest与RF不同,采样的数据量 Psi 不需要等于n,可以远远小于n,论文中提到采样大小超过256效果就提升不大了,并且越大还会造成计算时间的上的浪费,为什么不像其他算法一样,数据越多效果越好呢,可以看看下面这两个个图:
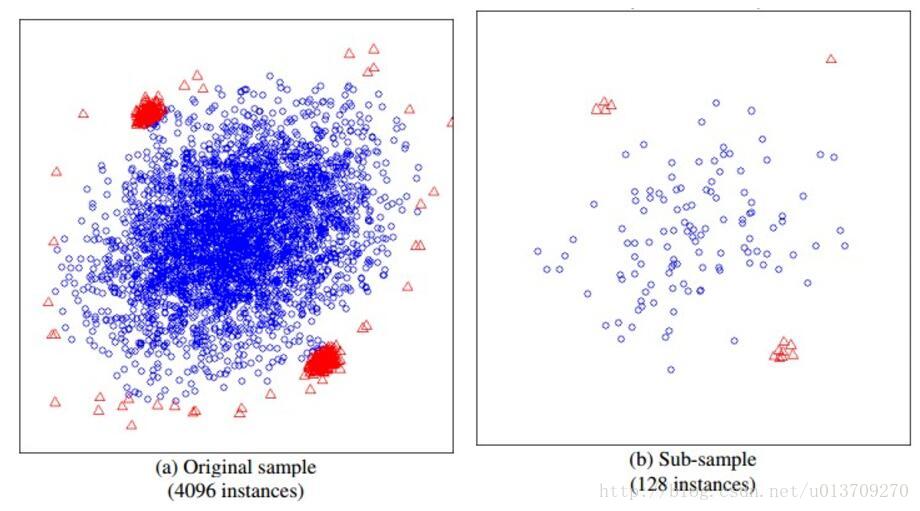
左边是原始数据,右边是采样了数据,蓝色是正常样本,红色是异常样本。可以看到,在采样之前,正常样本和异常样本出现重叠,因此很难分开,但我们采样之和,异常样本和正常样本可以明显的分开。
除了限制采样大小
Ψ
以外,还要给每棵iTree设置最大高度

IForest构造好后,对测试进行预测时,需要进行综合每棵树的结果,于是
E(h(x)) 表示记录x在每棵树的高度均值,另外 h(x) 计算需要改进,在生成叶节点时,算法记录了叶节点包含的记录数量,这时候要用这个数量 Size 估计一下平均高度, h(x) 的计算方法如下:

3. 对高维数据的处理
在处理高维数据时,可以对算法进行改进,采样之后并不是把所有的属性都用上,而是用峰度系数Kurtosis挑选一些有价值的属性,再进行iTree的构造,这跟随机森林就更像了,随机选记录,再随机选属性。
4. 只使用正常样本
这个算法本质上是一个无监督学习,不需要数据的类标,有时候异常数据太少了,少到我们只舍得拿这几个异常样本进行测试,不能进行训练,论文提到只用正常样本构建IForest也是可行的,效果有降低,但也还不错,并可以通过适当调整采样大小来提高效果。
5. 总结
iForest具有线性时间复杂度。因为是ensemble的方法,所以可以用在含有海量数据的数据集上面。通常树的数量越多,算法越稳定。由于每棵树都是互相独立生成的,因此可以部署在大规模分布式系统上来加速运算。
iForest不适用于特别高维的数据。由于每次切数据空间都是随机选取一个维度,建完树后仍然有大量的维度信息没有被使用,导致算法可靠性降低。高维空间还可能存在大量噪音维度或无关维度(irrelevant attributes),影响树的构建。对这类数据,建议使用子空间异常检测(Subspace Anomaly Detection)技术。此外,切割平面默认是axis-parallel的,也可以随机生成各种角度的切割平面,详见“On Detecting Clustered Anomalies Using SCiForest”。
iForest仅对Global Anomaly 敏感,即全局稀疏点敏感,不擅长处理局部的相对稀疏点 (Local Anomaly)。目前已有改进方法发表于PAKDD,详见“Improving iForest with Relative Mass”。
iForest推动了重心估计(Mass Estimation)理论发展,目前在分类聚类和异常检测中都取得显著效果,发表于各大顶级数据挖掘会议和期刊(如SIGKDD,ICDM,ECML)。
注意:目前我还没有发现有Java开源库实现了该算法。目前只有Python机器学习库scikit-learn的0.18版本对此算法进行了实现。而我的项目绝大多数都是Java实现的,因此我需要自己实现该算法。算法源码已实现并开源到我的GitHub上,读者可以下载源码并用IDEA集成开发环境直接打开项目,并运行测试程序以查看算法的检测效果:https://github.com/JeemyJohn/AnomalyDetection
对机器学习,人工智能感兴趣的小伙伴可以加我微信:JeemyJohn,我拉你进我的机器学习群(群里很多高手哦!),或者扫描二维码!当然你也可以关注我的公众号,点击链接:燕哥带你学算法公众号团队简介

参考文献:
http://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/icdm08b.pdf
https://github.com/scikit-learn/scikit-learn/blob/master/sklearn/ensemble/iforest.py
http://scikit-learn.org/dev/modules/generated/sklearn.ensemble.IsolationForest.html
有任何问题,加微信聊
















 1952
1952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









