









“The observation of and the search forsimilarities and differences are the basis of all human knowledge.” —— ALFREDB. NOBEL
“人类所有知识的基础就是观察和寻找相似与相异” —— 阿尔弗雷德·伯恩哈德·诺贝尔
1、前言
我们生活在数据大爆炸时代,每时每刻都在产生海量的数据如视频,文本,图像和博客等。由于数据的类型和大小已经超出了人们传统手工处理的能力范围,聚类,作为一种最常见的无监督学习技术,可以帮助人们给数据自动打标签,已经获得了广泛应用。聚类的目的就是把不同的数据点按照它们的相似与相异度分割成不同的簇(注意:簇就是把数据划分后的子集),确保每个簇中的数据都是尽可能相似,而不同的簇里的数据尽可能的相异。从模式识别的角度来讲,聚类就是在发现数据中潜在的模式,帮助人们进行分组归类以达到更好理解数据的分布规律。
聚类的应用非常广泛,比如在商业应用方面,聚类可以帮助市场营销人员将客户按照他们的属性分层,发现不同的客户群和他们的购买倾向(如下图将客户按照他们对颜色喜好归类)。这样公司就可以寻找潜在的市场,更高效地开发制定化的产品与服务。在文本分析处理上,聚类可以帮助新闻工作者把最新的微博按照的话题相似度进行分类,而快速得出热点新闻和关注对象。在生物医学上,可以根据对相似表达谱的基因进行聚类,从而知道未知基因的功能。

由于聚类是无监督学习方法,不同的聚类方法基于不同的假设和数据类型,比如基于。由于数据通常可以以不同的角度进行归类,因此没有万能的通用聚类算法,并且每一种聚类算法都有其局限性和偏见性。也就是说某种聚类算法可能在市场数据上效果很棒,但是在基因数据上就无能为力了。
聚类算法很多,包括基于划分的聚类算法(如:k-means),基于层次的聚类算法(如:BIRCH),基于密度的聚类算法(如:DBSCAN),基于网格的聚类算法( 如:STING )等等。本文将介绍聚类中一种最常用的方法——基于密度的聚类方法(density-based clustering)。
2、DBSCAN原理及其实现
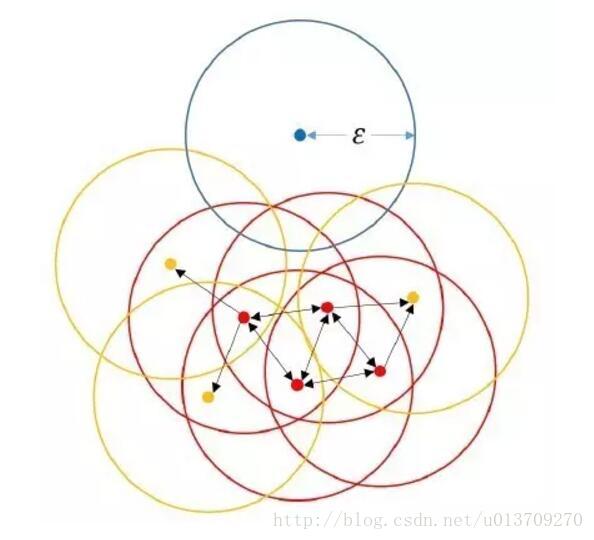
相比其他的聚类方法,基于密度的聚类方法可以在有噪音的数据中发现各种形状和各种大小的簇。DBSCAN(Ester, 1996)是该类方法中最典型的代表算法之一(DBSCAN获得2014 SIGKDD Test of Time Award)。其核心思想就是先发现密度较高的点,然后把相近的高密度点逐步都连成一片,进而生成各种簇。算法实现上就是,对每个数据点为圆心,以eps为半径画个圈(称为邻域eps-neigbourhood),然后数有多少个点在这个圈内,这个数就是该点密度值。然后我们可以选取一个密度阈值MinPts,如圈内点数小于MinPts的圆心点为低密度的点,而大于或等于MinPts的圆心点高密度的点(称为核心点Core point)。如果有一个高密度的点在另一个高密度的点的圈内,我们就把这两个点连接起来,这样我们可以把好多点不断地串联出来。之后,如果有低密度的点也在高密度的点的圈内,把它也连到最近的高密度点上,称之为边界点。这样所有能连到一起的点就成一了个簇,而不在任何高密度点的圈内的低密度点就是异常点。下图展示了DBSCAN的工作原理。
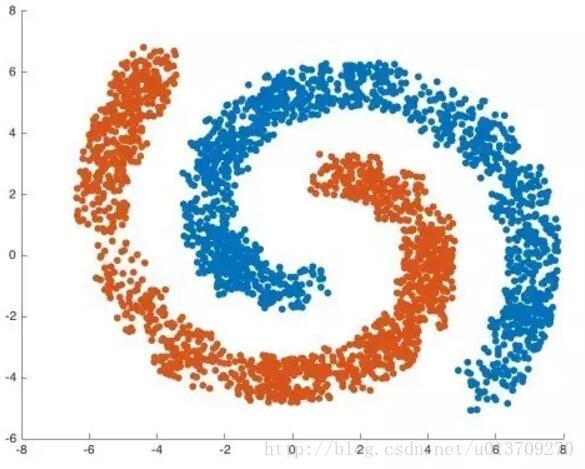
由于DBSCAN是靠不断连接邻域内高密度点来发现簇的,只需要定义邻域大小和密度阈值,因此可以发现不同形状,不同大小的簇。下图展示了一个二维空间的DBSCAN聚类结果。
DBSCAN算法伪码表达如下:

3、发现不同密度的簇
由于DBSCAN使用的是全局的密度阈值MinPts, 因此只能发现密度不少于MinPts的点组成的簇,即很难发现不同密度的簇。其成功与失败的情况举例如下:
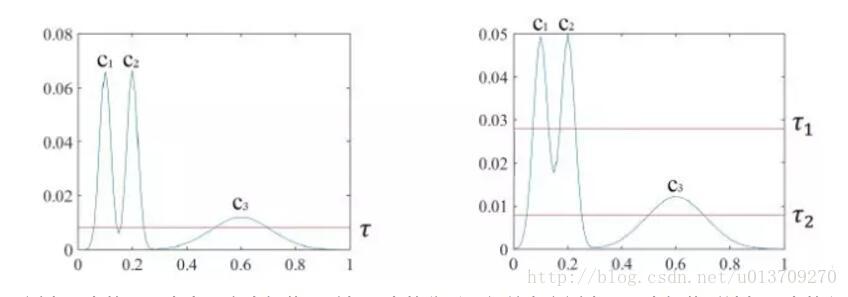
为了解决其发现不同密度的簇,目前已经有很多新的方法被发明出来,比如OPTICS(Ordering points to identify the clustering structure)将邻域点按照密度大小进行排序,再用可视化的方法来发现不同密度的簇,如下图所示。OPTICS必须由其他的算法在可视化的图上查找“山谷”来发现簇,因此其性能直接受这些算法的约束。
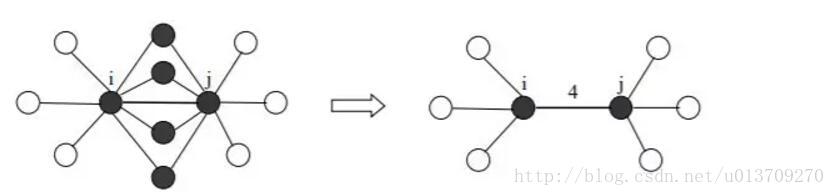
另外SNN采用一种基于KNN(最近邻)来算相似度的方法来改进DBSCAN。对于每个点,我们在空间内找出离其最近的k个点(称为k近邻点)。两个点之间相似度就是数这两个点共享了多少个k近邻点。如果这两个点没有共享k近邻点或者这两个点都不是对方的k近邻点,那么这两个点相似度就是0。然后我们把DBSCAN里面的距离公式替换成SNN相似度,重新算每个点的邻域和密度,就可以发现不同密度的簇了。SNN的核心就是,把原始的密度计算替换成基于每对点之间共享的邻域的范围,而忽略其真实的密度分布。SNN的缺点就是必须定义最近邻个数k, 而且其性能对k的大小很敏感。下图展示了SNN计算相似度的方法。
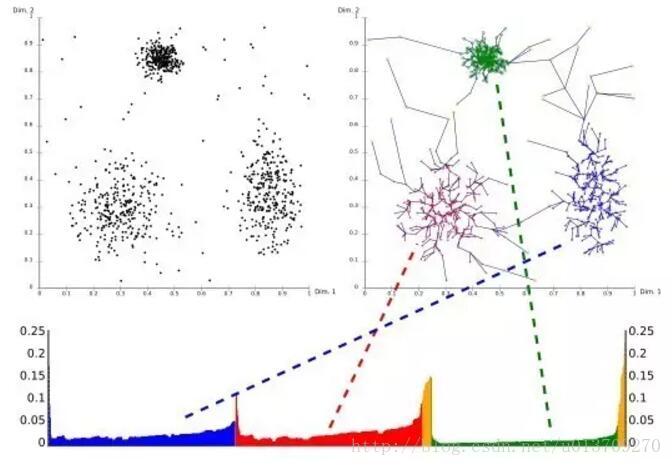
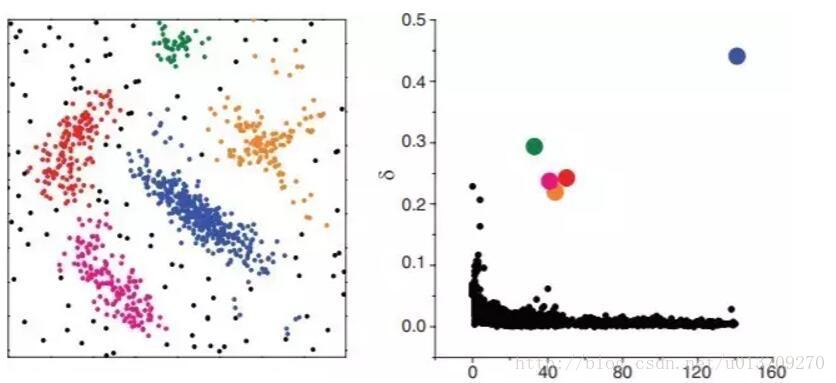
2014年Science杂志刊登了一种基于密度峰值的算法DP(Clustering by fast search and find of density peaks),也是采用可视化的方法来帮助查找不同密度的簇。其思想为每个簇都有个最大密度点为簇中心,每个簇中心都吸引并连接其周围密度较低的点,且不同的簇中心点都相对较远。为实现这个思想,它首先计算每个点的密度大小(也是数多少点在邻域eps-neigbourhood内),然后再计算每个点到其最近的且比它密度高的点的距离。这样对每个点我们都有两个属性值,一个是其本身密度值,一个是其到比它密度高的最近点的距离值。对这两个属性我们可以生成一个2维图表(决策图),那么在右上角的几个点就可以代表不同的簇的中心了,即密度高且离其他簇中心较远。然后我们可以把其他的点逐步连接到离其最近的且比它密度高的点,直到最后连到某个簇中心点为止。这样所有共享一个簇中心的点都属于一个簇,而离其他点较远且密度很低的点就是异常点了。由于这个方法是基于相对距离和相对密度来连接点的,所以其可以发现不同密度的簇。DP的缺陷就在于每个簇必须有个最大密度点作为簇中心点,如果一个簇的密度分布均与或者一个簇有多个密度高的点,其就会把某些簇分开成几个子簇。另外DP需要用户指定有多少个簇,在实际操作的时候需要不断尝试调整。下图展示了一个DP生成的决策图。
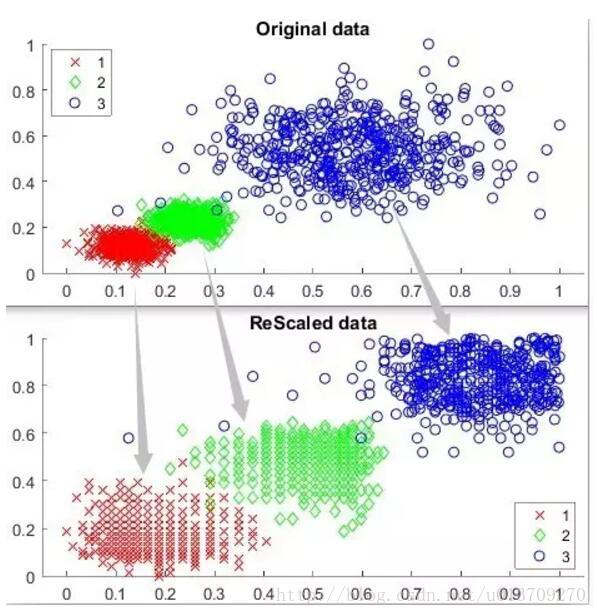
除此之外,还可以用密度比估计(Density-ratio estimation)来克服DBSCAN无法发现不同密度簇的缺陷。密度比的核心思想就是对每个点,计算其密度与其邻域密度的比率,然后用密度比计算替换DBSCAN的密度计算来发现核心点Core point,而其他过程和DBSCAN不变。这样一来,每个局部高密度点就会被选出来作为核心点,从而发现不同密度的簇。基于这个思想,我们还可以把原始数据按其密度分布进行标准化(ReScale),即把密度高的区域进行扩张,密度低的区域继续收缩。这样以来,不同密度的簇就可以变成密度相近的簇了,我们再在标准化后的数据上直接跑DBSCAN就搞定了。这种方法需要用户设置邻域范围来计算密度比,下图展示了标准化前后的数据分布对比。
4、讨论
基于密度的聚类是一种非常直观的聚类方法,即把临近的密度高的区域练成一片形成簇。该方法可以找到各种大小各种形状的簇,并且具有一定的抗噪音特性。在日常应用中,可以用不同的索引方法或用基于网格的方法来加速密度估计,提高聚类的速度。基于密度的聚类也可以用在流数据和分布式数据中,关于其他方向的应用,详见(Aggarwal 2013).
5、源码下载 (Matlab)
DP: https://au.mathworks.com/matlabcentral/fileexchange/53922-densityclust
DBSCAN, SNN, OPTICS 和 Density-ratio: https://sourceforge.net/projects/density-ratio/

参考文献 :
Aggarwal, C. C., & Reddy, C. K.(Eds.). (2013). Data clustering: algorithms and applications. CRC press.
Ankerst, M., Breunig, M. M., Kriegel, H.P., & Sander, J. (1999, June). OPTICS: ordering points to identify theclustering structure. In ACM Sigmod record (Vol. 28, No. 2, pp. 49-60). ACM.
Ertöz, L., Steinbach, M., & Kumar,V. (2003, May). Finding clusters of different sizes, shapes, and densities innoisy, high dimensional data. In Proceedings of the 2003 SIAM InternationalConference on Data Mining(pp. 47-58). Society for Industrial and AppliedMathematics.
Ester, M., Kriegel, H. P., Sander, J.,& Xu, X. (1996, August). A density-based algorithm for discovering clustersin large spatial databases with noise. In SIGKDD (Vol. 96, No. 34, pp.226-231).
Han, J., Pei, J., & Kamber, M.(2011).Data mining: concepts and techniques. Elsevier.
Rodriguez, A., & Laio, A. (2014).Clustering by fast search and find of density peaks.Science,344(6191),1492-1496.
Zhu, Y., Ting, K. M., & Carman, M.J. (2016). Density-ratio based clustering for discovering clusters with varyingdensities. Pattern Recognition, Volume 60, 2016, Pages 983-997, ISSN 0031-3203.














 3869
3869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









