







1. logistic classifier
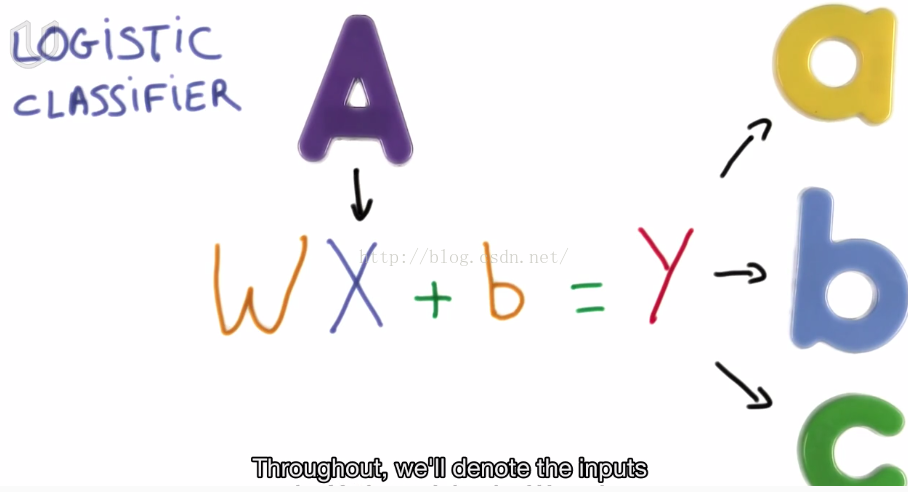
model: W*X + b = Y
where W is the Weights Vector, X is input vector, b is bias and Y is output.
Y, the output vector is a numeric vector.

As show in picture above, y should be transformed into another numeric vector where value presents the probability of corresponding class.
2. Softmax Function
softmax function can transform y into probability vector.
it can be implemented in python as follows:
"""Softmax."""
scores = [3.0, 1.0, 0.2]
import numpy as np
def softmax(x):
"""Compute softmax values for each sets of scores in x."""
# each column is a set of data
# TODO: Compute and return softmax(x)
s = np.exp(x)
r = np.sum(s,axis=0)
return s/r
print(softmax(scores))
# Plot softmax curves
import matplotlib.pyplot as plt
x = np.arange(-2.0, 6.0, 0.1)
scores = np.vstack([x, np.ones_like(x), 0.2 * np.ones_like(x)])
plt.plot(x, softmax(scores).T, linewidth=2)
plt.show()
when we multiple y by a positive number greater than 1, the result vector will give a rise to more bias distribution.
and by a positive number smaller than 1 will lead to a more uniform distribution result.
3. one hot encoding

every column represents a y output vector.
so there should be only one '1' in each column.
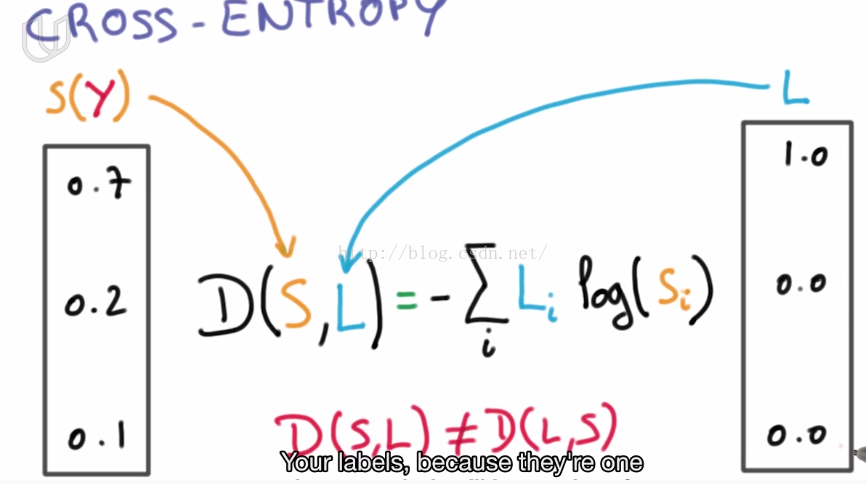
4. cross entropy
A function is needed to describe the differences between probability vector and classification label vector.
In classification result vector, there is only one '1' which means the corresponding class. And other positions will be filled with '0'.
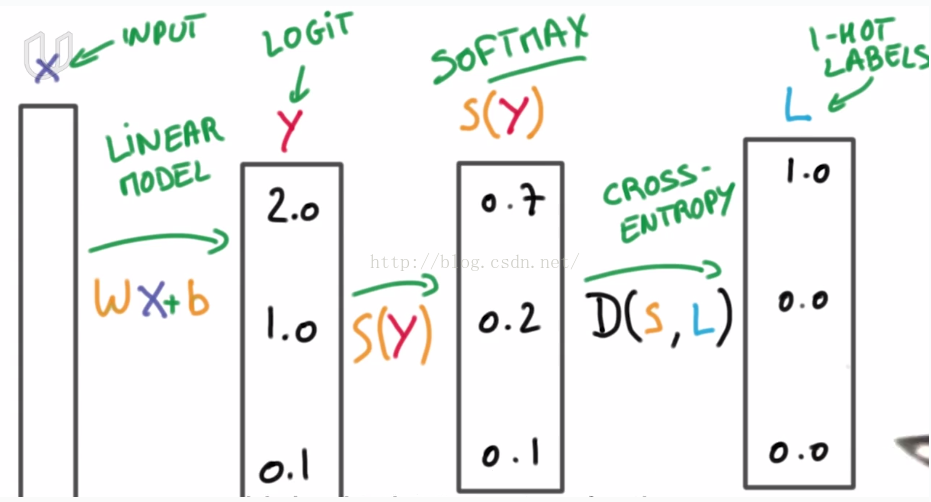
so, a partial logistic classification process can be described as follows:
however, how to find a proper weight vector and bias vector to get a good enough accuracy?
An optimization method is employed to minimize the differences between computational results and labels(minimize average cross entropy).
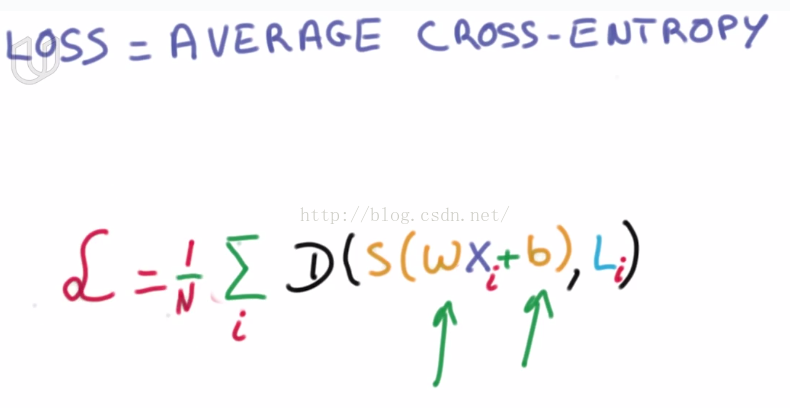
Gradient descent method can achieve our expectation.
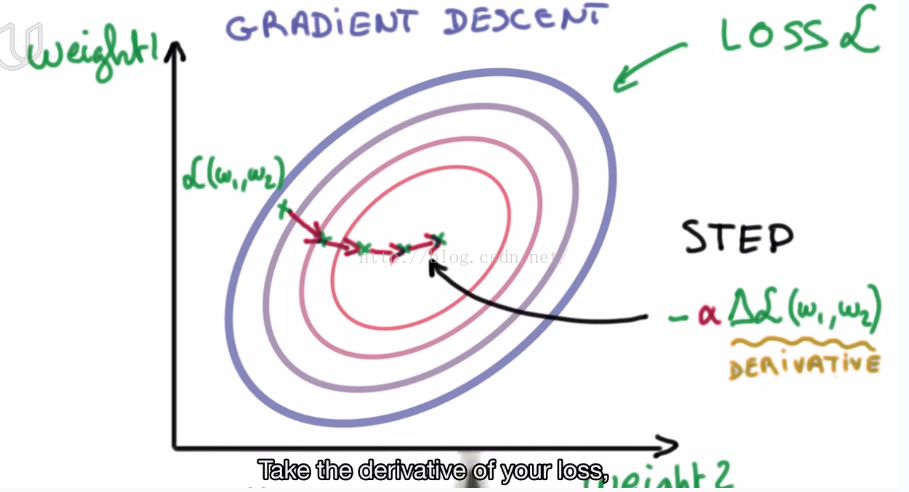
alpha represents learning rate.
5. training set, validation set and test set
validation set is a small subset of training set for tuning parameters and getting a better performance.
so tuning parameters means that validation set has had an influence on training set. Maybe sometimes you will get an over-fitting model. (you think that your model is perfect but get a shit when testing another set)
However, our test set is still pure.
Sometimes noise gets you an increasing accuracy by 0.1%. Be careful, Do not be blind by noise.
6.Stochastic Gradient Descent
when we train a big data-set with gradient descent method, it is a long time to get model parameters.
However Stochastic Gradient Descent saved us.
It uses a random subset of training set to find a good descent direction.
and then use another random subset of training set to find next good direction.
That is the core of deep learning.
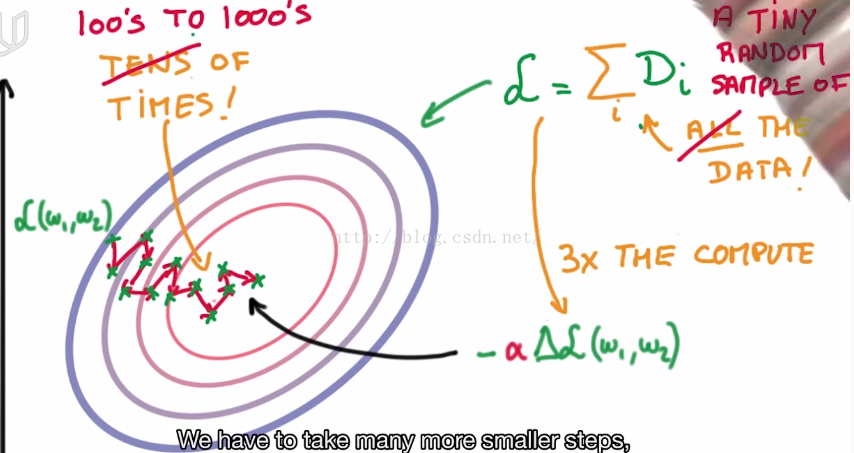
(1) Tips: initialization
normalize input with 0 average value and small variance
initialize weight randomly with 0 average value and small variance

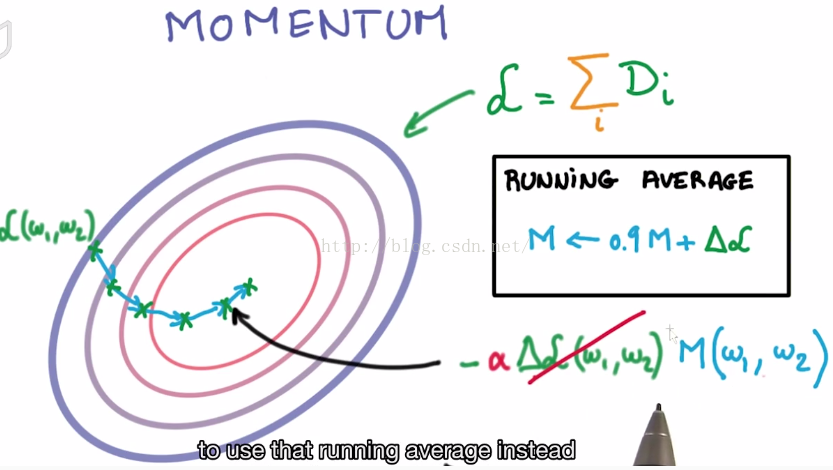
(2) Tips: momentum
change derivative into M(w1,w2)
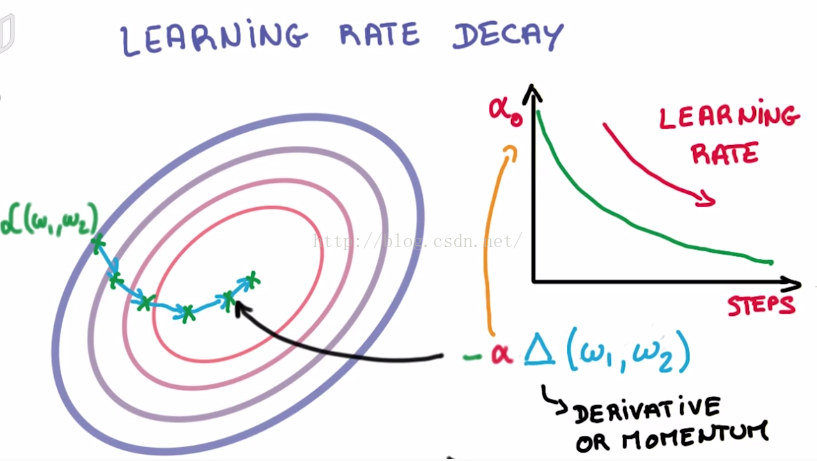
(3) Tips: learning rate decays
there are many ways of decreasing learning rate by steps.
common using exponential decay.
(4) Tips: S.G.D black magic

there is a new method call ADAGRAD, which is a derivative from S.G.D and implements initial learning rate, learning rate decay, and momentum. Using this method, only batch size and weight initialization are what you need concern about.
Keep Calm and lower your Learning Rate!














 303
303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









