






-
- 设计目标
-
- 平台无关。如果服务于平台有关,需要有良好设计的可插拔接口
- 可插拔组件:不能假定特殊的工具或技术。任何特殊的工具或技术都要跟组件封装在一起。与组件的依赖只包括puppet来管理配置,数据库来保存状态。
- 可管理组件的版本,而不影响集群的状态。
- 扩展性:可以很容易的添加服务、组件和API,修改配置。也需要考虑不只是支持HDP,而是整个Hadoop栈。
- 在任意组件失败时,系统应该保持可用。系统应该可以对失败的组件进行完整的挂起操作(?),如果组件不能恢复,系统也应该是继续可用的。
- 1)在web端和api都应该提供基于角色的认证和授权。2)使用Kerbros来保障对Hadoop栈的安装、管理和监控操作。3)ambari组件间的通信要认证和加密(server-agent之间)。
- 尽量简化异常的跟踪过程。应该将充分的失败信息细节展现给客户。
- 操作应是准实时的,并且能将中间状态反馈给用户
- 术语
-
- 服务(service):指的是Hadoop栈中的服务,例如:HDFS、HBase、Pig。一个服务可能包含多个组件,例如HDFS包括Namenode、SecondaryNameNode、Datanode。一个服务可能只包含客户端程序,例如Pig服务没有守护进程,只有客户端程序。
- 组件(component):一个服务由一个或多个组件构成。组件在服务中可能是可选的。组件可能被安装在多个节点上,例如Datanode。
- 节点(node)/主机(host):指的是集群中的一台主机,节点或主机代表的是同一个意思。
- 组件实例(Node-Component):组件实例指的是安装在一个节点上的一个组件。例如:一个安装在特定节点上的Datanode组件就是一个组件实例。
- 操作(Operation):一个操作包含一系列施加在集群上的改变或动作,这些改变或动作是为了响应用户的请求,或者使集群进入另外一个状态。例如,启动一个服务和执行一次冒烟测试都是一个操作。如果一个用户请求包括添加一个新服务的同时执行冒烟测试,这也是一个操作。而且这些动作是按照顺序执行的。
- 任务(Task):任务是发往一个节点的工作单元。一个任务作为一个动作的一部分,被一个节点执行。例如,一个动作包含一个在n1节点安装Datanode和在n2节点安装DataNode和SecondaryNameNode的任务,在这里任务1包含在n1安装Datanode,任务2包含在n2安装Datanode和SecondaryNameNode。
- 阶段(stage):阶段是指为了完成一个操作,互相独立的多个任务,一个阶段中的多个任务可以在多个节点中并行执行。
- 动作(Action):一个动作由在一台或多台主机上运行的一个或多个任务组成。动作可以根据action-id属性来跟踪,节点上报的状态记录也都是动作粒度的。动作可以被看做是正在执行的阶段。在本文档中除非特殊说明,阶段和动作都是一对一的关系,acton-id和request-id、stage-id都可以进行双向查找。
- 阶段计划(Stage Plan):一个操作一般由在多个节点上的多个任务组成,这些任务往往有依赖关系,并且按照顺序执行。因此,在有很多任务时,任务应该可以被分解为多个阶段,当一个阶段全部完成后,才能执行下一个阶段。但在同一个阶段里,不同节点的任务可以被并行执行。
- (Manifest):Manifest是指被发往节点被执行的任务的定义。Manifest必须完成的定义任务,并且能够被序列化,从而被持久化到磁盘上,用来记录或恢复。
- 角色(Role):角色可以指组件,例如Namenode、Datanode;也可以是一个动作,例如:HDFS数据均衡,HBase冒烟测试等...)
- Ambari架构
-
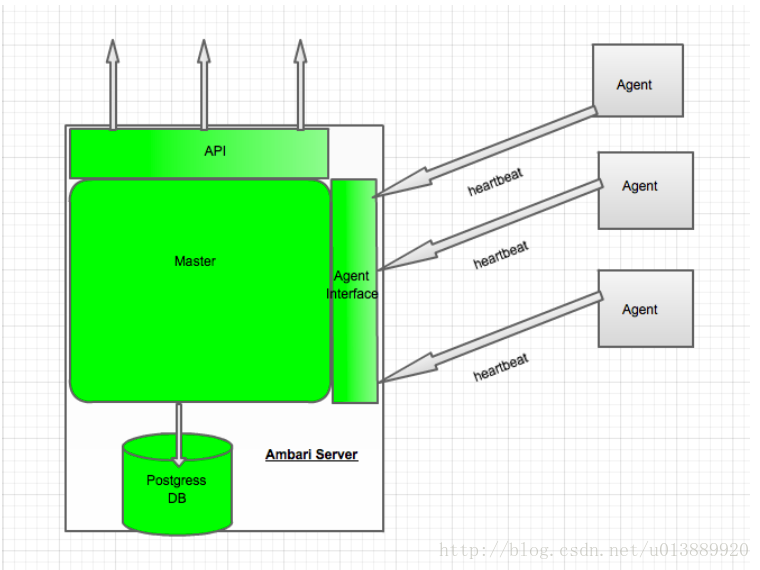
- 高层架构
- ambari-server设计
- ambari-agent设计
- 高层架构
- 用例
-
- 添加服务:为现有集群添加服务。下面的例子是在有HDFS服务的基础上,添加HBase master和slave服务。
-
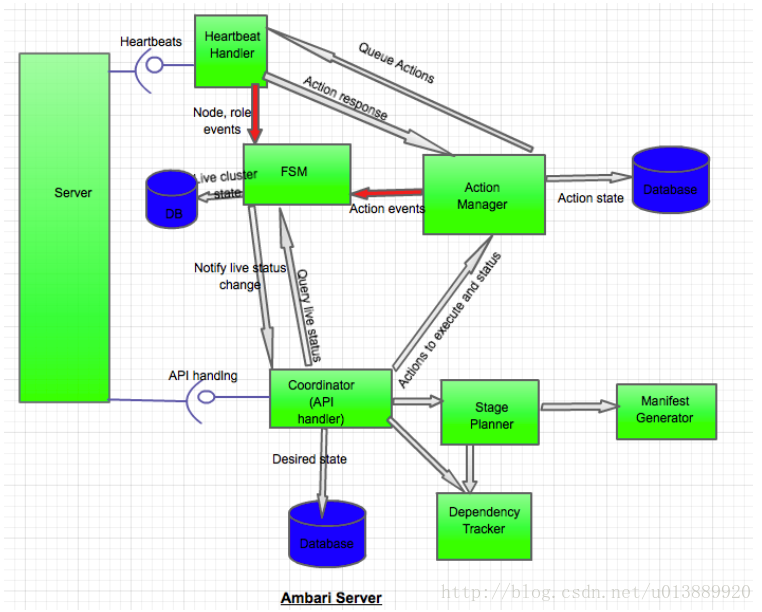
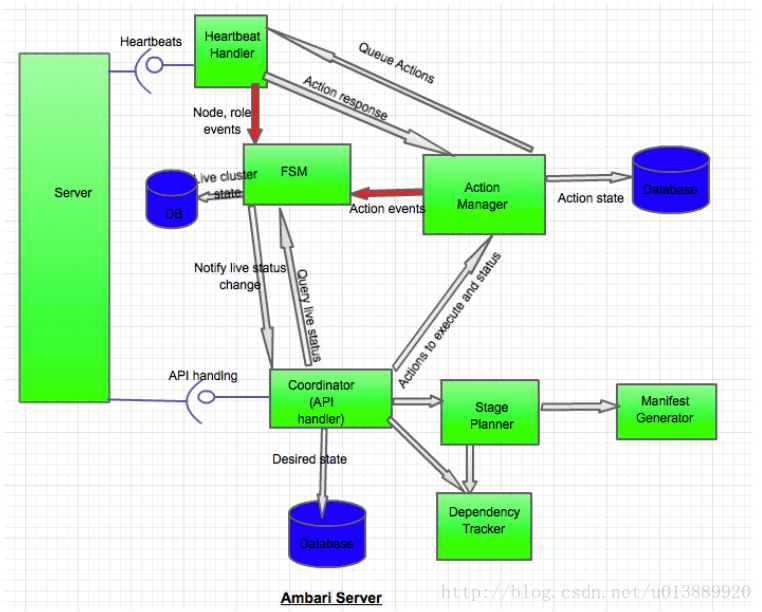
- 请求通过API发送到server端,生成了一个request-id并与请求绑定,然后调用Coordinator(协调器)组件来处理请求。
- 这个API需要实现多个步骤最终完成在集群中启动新服务的操作。在这个例子中,具有的步骤为:按照特定的顺序,在集群中安装先决条件和各个组件,重新配置Nagios服务器来提供监控服务。
- Coordinator组件会查询依赖跟踪器(Dependency Tracker)来找到HBase需要的先决条件。依赖跟踪器会返回HDFS和ZOOKEEPER。Coordinator组件还会查找Nagios服务器的依赖条件,会返回HBase Client。以来跟踪器同时也会返回所有这些组件和他们需要处于的状态。Coordinator将会把我们期望这些组件所处的状态写到数据库中(注意是期望的状态,并不是现在的实际状态)
- 在上一步中,Coordinator组件可能还需要客户输入Zookeeper节点信息,这依赖于API的语法。
- 然后Coordinator组件会把一个组件列表以及他们的期望状态传给阶段计划(Stage Planner)组件,节点计划组件会返回操作在每个节点执行的阶段及其顺序,包括安装、启动、修改等...阶段计划组件还会调用Manifest生成器来生成每个任务的Manifest。
- Coordinator组件把这些有顺序的阶段说明,连同request-id一起传给了Action Manager组件。
- Action Manager会更新每个组件实例(node-component)的状态,在FSM中,反映为操作正在执行中状态。每个组件实例的改变都会更新FSM。在这个步骤,FSM可能检测到不合法的事件,并抛出失败,这会导致退出操作,所有动作都会被标记为因为同一个错误而失败。
- Action Manager会为每个操作创建一个action-id,并把他加入到计划中。Action Manager首先挑选计划中的第一个阶段,并把所有任务向受影响的节点发出。当第一个阶段完成后,第二个节点就会被执行。Action Manager也会开启一个定时动作。
- 心跳句柄(heartbeat handler)会返回动作的响应,并通知Action Manager。然后Action Manager向FSM发出一个事件来更新状态。如果发生超时,动作将会再次被调度执行,或者被标记为失败。一旦一个动作所涉及的所有节点都返回了完成信息,这个动作就被认为已经完成了。当一个阶段的所有动作都完成了,这个节点也就被认为是完成了。(这个描述跟之前“术语”中描述的动作(Action)和阶段(Stage)的描述不一致)
- 动作完成也会被记录在数据库中。
- Action Manager会执行下一个阶段并重复这个过程。
- 执行冒烟测试:HDFS和HBase已经安装完成,用户想要执行冒烟测试。
-
- 跟上面一样,server通过api接收到了请求,并生成一个request-id,由Coordinator组件的handler来处理这个请求。
- handler调用dependency tracker来确认HBase服务已经被安装,并且正在运行着。如果HBase没有在运行,dependency trakcer会抛出一个错误。handler还会决定冒烟测试在哪里进行。dependency traker会暴露一个方法来告诉Coordinator哪个HBase客户端会用来执行测试。Stage Planner被调用来生成一个计划来执行测试。在这个用例中,计划只有涉及到一个组件实例的一个阶段。
- 剩下的步骤跟前一个例子相似。在这个例子中,FSM将hbase-smoketest作为一个角色看待。
- 重新配置服务(Reconfigure Service)
-
- 集群已经启动,并且服务和依赖也都已经安装并启动。
- 服务器接收到了一个保存配置的请求,一个新的配置快照被保存在了服务器。请求可能也包含了配置更新会影响哪些服务或者角色、节点。这意味着持久层要针对服务、组件、节点记录配置的修改,配置的最后的版本是什么,以及在请求中影响了哪些对象。
- 用户可以通过多次调用这个操作,来设置配置的多个checkpoint
- 有时候,用户希望将新配置部署到集群中。在这个场景,用户发出一个请求,来将新配置部署到指定的服务、组件、组件实例上。
- 可以根据API的不同,指定配置的版本,或使用最新版本的配置。
- Coordinator将会用两步来完成“重新配置”操作。首先,会生成一个阶段来停止请求中的服务,然后会生成一个阶段来开启服务。Coordinator将会通过Action Manager来先后执行这两个计划,剩下的步骤就跟前面描述的一样了。
- ambari master故障和重启
-
- 假设ambari master宕掉了,有多个场景需要被讨论。
- 假设
-
- 期望状态已经被保存进了数据库
- 所有接下来要执行的操作都被保存到了数据库
- 执行状态已经被记录到了DB,但agent不能将最新的状态返回,所以命令(require)将基于DB的状态(这个没看懂)
-
-
Live status is tracked in the DB. However, the agent cannot send backlive status currently so require will be based on DB state.
-
- 所有的动作都是幂等的
- 动作要求
-
- ambari master
-
- 需要把之前所有没完成的动作重新排列交给心跳handler,允许agent按照用户请求重新执行这些步骤。
- 在ambari server没有完全恢复前,不能接受新的请求,
- 如果当前状态和期望的状态不一致,例如,期望状态是STARTED,当前状态是INSTALLED。应该有一个触发器来生成一个阶段计划,来把当前状态变成期望状态。但是如果期望状态是STOPPED,实际状体是STOP_FAILED,这样可能通过接口已经不能完成停止的操作。就需要管理员来人工完成停止的动作。(这可能根据API规范或产品决定的变化而变化)
- ambari agent
-
- 当master消失的时候,agent不应该死掉,应该仍按照规则发心跳包,当master恢复的时候,也要恢复正常工作。
- 当master死掉后,agent应保留所有要传递给master的必要信息,并在master恢复后发送给master。
- 如果master死掉的时候agent正在注册,应该再次重新注册。
- 下架(Decommission)一个Datanodes子集
-
- Decommissioning操作将在puppet层,作为一个动作,使用hadoop-admin角色来执行。hadoop-admin将作为一个新的角色来定义,包含所有hadoop的管理操作。这个角色将要求hadoop-client组件被安装,并且觉有管理员权限。
- Decommission操作的manifest将由带有特定参数hadoop-admin角色组成,例如一个datanodes的列表,具有特定标识的动作等...
- Coordinator将确定一个节点,用来执行hadoop-admin操作。这个节点必须是可用的。
- 节点是否被下架,应该可以在另外一个进程中被查询到。这个信息在namenode UI中是可用的。ambari应该提供另外的api来查询正在下架或已经下架的节点、
- ambari没有记录一个datanode是否正在被下架,或者已经被下架了。为了在ambari中处理已经被下架的datanode节点,应该提供另外的api来让ambari停止或卸载那些datanode。
- The decommission action will follow the state machine for node-roles that are actions. 如果下架操作已经在namenode上被执行了,就应该认为是成功了。例如在管理命令成功发送到datanode的时候
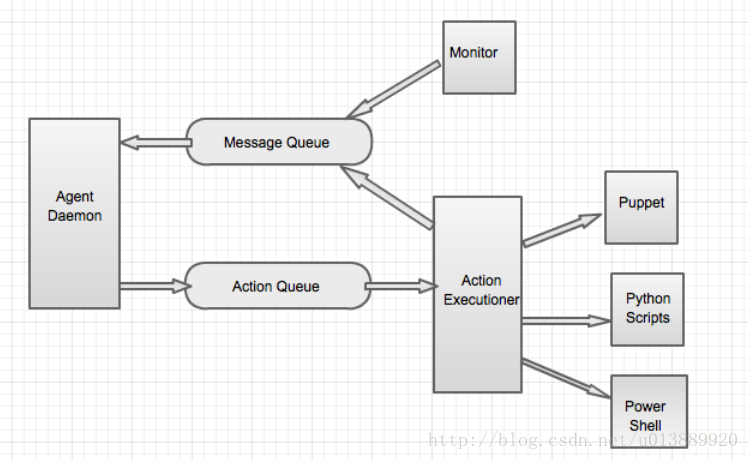
- Agent:
-
- agent每隔几秒就会向master发一次心跳包,并且通过心跳包的回应接收命令。心跳回应是master向agent发送命令的唯一途径。在agent端,命令会被放在一个动作队列中,被动作执行器拿来执行。动作执行器会根据命令类型和动作类型来挑选合适的工具(Puppet、Python、etc)执行命令。因此心跳回应中的命令会在agent端被异步执行。动作执行器会把回应和进行时信息放到消息队列中。agent会在下一次的心跳包中把消息队列中的所有消息发往master。
-
- 恢复:master的故障恢复有两种选择
-
- 动作恢复:在这个例子中,动作会被持久化,然后在恢复时被重新构建执行计划。集群状态也会被持久化到数据库中,并在重启后重新构建状态。有种情况可能会发生,就是动作已经执行完毕,但由于master崩溃而没有记录状态,这时需要有一种机制来确认这个操作时幂等的,并且将数据库中所有被标记为完成或失败的动作都重新制定计划并执行。被持久化的动作可以通过redo logs查看。
- 还有一种情况是基于期望状态的恢复。在这种情况下,master持久化了一个期望状态,并通过重启的手段来使集群达到这个状态。
- 因为我们提前对操作做了执行计划并持久化了它,所以这种基于动作的恢复跟我们的整体设计结合的很好。尽管我们持久化了期望状态,我们仍然需要对动作重新做执行计划。而且从ambari的视角来看,设置期望状态的实践没有捕获操作对集群状态的改变。持久化的动作可以通过redo logs来查看。
- agent的恢复只需要重启agent就可以了,因为agent是无状态的。agent的失败可以由master通过一定时间的心跳包缺失而获知。
- 待定的:agent重启是怎么样的?
- 安全:
-
- 一种方式是使用HTTP基础认证。这意味着客户端的每次请求都要通过一个credentials(可能是base46编码过的),服务端必须对每次调用都做认证。这种方法对命令行客户端使用api比较容易。这种方法服务端不保存客户端的session状态。
- 还有一种方式是使用HTTP session和Cookies。每当服务端做了一次认证,就生成一个session-id,存储起来,并将session-id作为一个id返回并存储到客户端。在接下来的请求中,客户端可以使用这个session-id来做认证。这种方法在不需要每次请求都做认证的请求下会很有效率。VMWare的vCloud REST API 1.0中就使用了这种方法。但是,由于安全问题,他们在之后的版本中弃用了这种方法(http://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displ
ayKC&externalId=1025884)。这种方法在服务端保持了session状态,而没有做到RESTFulnes(如果我们在意这个的话) - 我们可以同时支持以上两种方式。
- 对于命令行工具,推荐使用第一种方式。对于基于浏览器的应用,第二种方式可以防止重复认证。
- 以上两种认证方式都应该通过HTTPS方式来完成。用户认证信息和session令牌永远不要在HTTP下进行传输。
- 向导:
-
- 在HMC(1.0发布版)(小型机控制软件)中,向导在安装、配置主机过程中是一个非常integrated的过程。在ambari1.1中,在主机上安装agent是,向导是一个非常有用的方法。在HMC1.0中,向导会获得主机信息,并将其添加到数据库中。这将成为ambari中agent向master注册过程的一部分。向导将只通过SSH连接主机并安装agent。在执行向导的过程中,数据库不会被改变(??)。
Ambari系统架构设计
最新推荐文章于 2023-08-08 23:09:24 发布















 372
372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









