







 本文深入剖析了Hadoop 2.x版本中DataNode的逻辑结构,包括HDFS Federation、Datanode的三层结构(数据层、逻辑层、服务层)以及存储、文件系统数据集、BlockPoolManager、流式接口等功能的实现细节。着重介绍了DataNode的升级机制,如升级、回滚和提交过程,并探讨了数据块扫描器和DirectoryScanner的角色。
本文深入剖析了Hadoop 2.x版本中DataNode的逻辑结构,包括HDFS Federation、Datanode的三层结构(数据层、逻辑层、服务层)以及存储、文件系统数据集、BlockPoolManager、流式接口等功能的实现细节。着重介绍了DataNode的升级机制,如升级、回滚和提交过程,并探讨了数据块扫描器和DirectoryScanner的角色。
1. Datanode逻辑结构
1.1 HDFS Federation
Federation的HDFS集群可以定义多个Namenode/Namespace,这些Namenode之间是互相独立的,它们各自分工管理着自己的命名空间。而Datanode则提供数据块的共享存储功能,每个Datanode都会向集群中所有Namenode注册,且周期性地向所有Namenode发送心跳和块汇报,然后执行Namenode通过响应发回的指令。
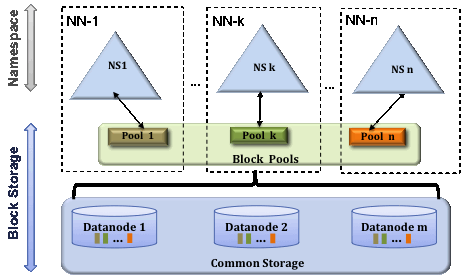
块池(BlockPool)
一个块池由属于同一个命名空间的所有数据块组成,这个块池中的数据块可以存储在集群中的所有Datanode上,而每个Datanode都可以存储集群中所有块池的数据块。
命名空间卷(NamespaceVolume)
一个Namenode管理的命名空间以及它对应的块池一起被称为命名空间卷,当一个Namenode/Namespace被删除后,对应的块池也会被删除。集群升级时,命名空间卷是基本的升级单元
1.2 Datanode逻辑结构
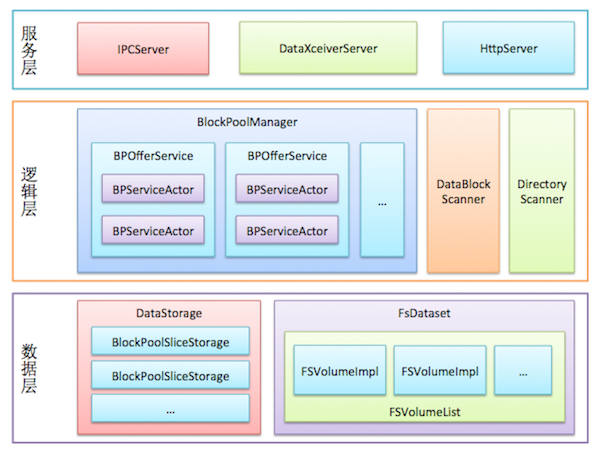
1.2.1 数据层
- 数据存储(DataStorage):负责管理与组织Datanode的磁盘存储空间,同时也负责管理存储空间的生命周期(包括升级、回滚、提交等操作)。BlockPoolSliceStorage类管理Datanode上单个块池的存储空间。DataStorage类会持有所有BlockPoolSliceStorage对象的引用,并通过这些引用管理所有块池。
- 文件系统数据集(FsDataset):抽象了Datanode管理数据块的所有操作,例如创建数据块文件、维护数据块文件和校验和文件的对应关系等。
1.2.2 逻辑层
- BlockPoolManager:管理所有块池的接口类。BlockPoolManager对象持有多个BPOfferService,每个BPOfferService对象都管理这个Datanode的一个块池。每个BPOfferService持有两个BPServiceActor对象,每个BPServiceActor对应HA机制中的一个Namenode,该对象负责向这个Namenode发送心
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









