







1. HDFS概述
1.1 体系结构
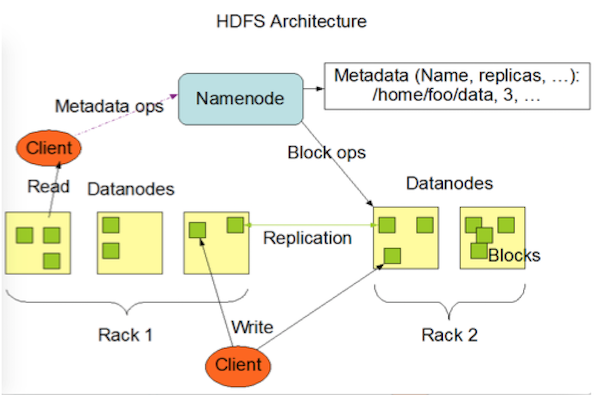
HDFS是一个主从(Master/Slave)体系结构的分布式系统。Namenode是HDFS的Master节点,负责管理文件系统的命名空间(namespace),以及数据块到具体Datanode节点的映射等信息。集群中的Datanode一般是一个节点一个,负责管理它所在节点的存储。
1.2 RPC接口
Hadoop RPC接口主要定义在org.apache.hadoop.hdfs.protocol包和org.apache.hadoop.hdfs.server.protocol包中,包括以下几个接口:
- ClientProtocol:定义了客户端与名字节点间的接口,客户端对文件系统的所有操作都需要通过这个接口,同时客户端读、写文件等操作也需要先通过这个接口与Namenode协商之后,再进行数据块的读出和写入操作。
- ClientDatanodeProtocol:客户端与数据节点间的接口。定义的方法主要是用于客户端获取数据节点信息时调用,而真正的数据读写交互则是通过流式接口进行。
- DatanodeProtocol:数据节点通过这个接口与名字节点通信,同时名字节点会通过这个接口中方法的返回值向数据节点下发指令。这是名字节点与数据节点通信的唯一方式。数据节点会通过这个接口向名字节点注册、汇报数据块的全量以及增量的存储情况。同时,名字节点也会通过这个接口中方法的返回值,将名字节点指令带回该数据块,根据这些指令,数据节点会执行数据块的复制、删除以及恢复操作。
- InterDatanodeProtocol:数据节点与数据节点间的接口,数据节点会通过这个接口和其他数据节点通信。这个接口主要用于数据块的恢复操作,以及同步数据节点存储的数据块副本的信息。
- NamenodeProtocol:第二名字节点与名字节点间的接口。
- 其他接口:主要包括安全相关接口(RefreshAuthorizationPolicyProtocol、RefreshUserMappingsProtocol)、HA相关接口(HAServiceProtocol)等。
1.3 流式接口
在HDFS中,流式接口包括了基于TCP的DataTransferProtocol接口,以及HA架构中Active Namenode和Standby Namenode之间的HTTP接口。
- DataTransferProtocol:用来描述写入或者读出Datanode上数据的基于TCP的流式接口,HDFS客户端与数据节点以及数据节点与数据节点之间的数据块传输就是基于DataTransferProtocol接口实现的。
- Active Namenode和Standby Namenode之间的HTTP接口:在HA中,Standby Namenode只需定期将自己的命名空间写入一个新的fsimage文件,然后就会向Active Namenode的ImageServlet发送HTTP GET请求/getimage?putimage=1。这个请求的URL中包括了新的fsimage文件的事务ID,以及Standby Namenode用于下载的端口和IP地址。Active Namenode接收到该请求后,会发起HTTP GET请求以下载fsimage文件。
2. HDFS主要流程
2.1 客户端读流程
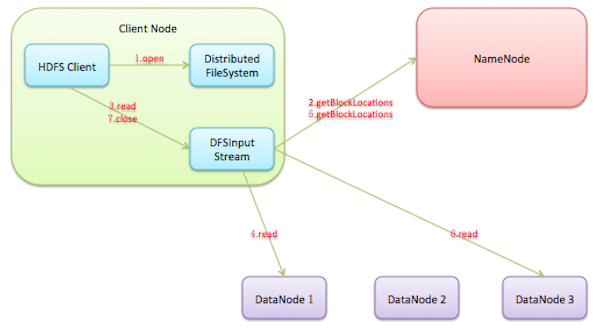
打开HDFS文件:HDFS客户端首先调用DistributedFileSystem.open()方法打开HDFS文件,底层调用ClientProtocol.open(),返回HdfsDataInputStream
对象用于读取数据块。HdfsDataInputStream是DFSInputStream的装饰类,真正进行数据块读取操作的是DFSInputStream对象。从NameNode获取Datanode地址:在DFSInputStream的构造方法中,会调用ClientProtocol.getBlockLocations()方法向名字节点获取该HDFS文件起始位置数据块的位置信息。NameNode返回的数据块的存储位置是按照与客户端的距离远近排序的,所以DFSInputStream可以选择一个最优的Datanode节点,然后与这个节点建立数据连接读取数据块。
连接到Datanode读取数据块:HDFS客户端通过调用DFSInputStream.read()方法从这个最优的Datanode读取数据块,数据会以数据包(packet)为单位从数据节点通过流式接口传送到客户端。当到达一个数据块的末尾时,DFSInputStream就会再次调用ClientProtocol.getBlockLocations()获取文件下一个数据块的位置信息,并建立和这个新的数据块的最优节点之间的连接,然后HDFS客户端就可以继续读取数据块了。
关闭输入流:当客户端成功完成文件读取后,会通过HdfsDataInputStream.close()方法关闭输入流。
注:当数据块损坏时,HDFS客户端就会通过ClientProtocol.reportBadBlocks()向NameNode汇报这个损坏的数据块副本。
2.2 客户端写流程
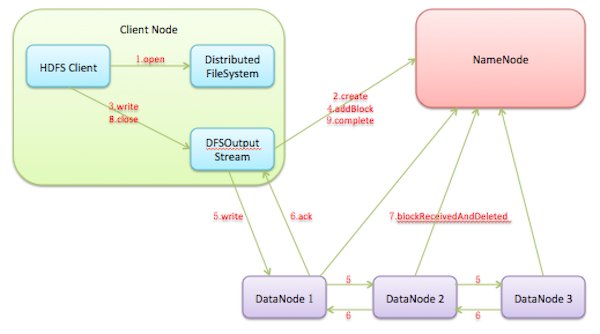
创建文件:HDFS客户端写一个新的文件时,会首先调用DistributedFileSystem.create()方法在HDFS文件系统中创建一个新的空文件。底层调用ClientProtocol.create()方法通知Namenode执行对应的操作,Namenode会首先在文件系统目录树中的指定路劲下添加一个新的文件,然后将创建新文件的操作记录到editlog中。完成ClientProtocol.create()调用后,DistributedFileSystem.create()方法就会返回一个HdfsDataOutputStream对象,底层包装了一个DFSOutputStream对象,真正执行写数据操作的其实是DFSOutputStream。
建立数据流管道:获取到DFSOutputStream对象后,HDFS客户端就可以调用DFSOutputStream.write()方法来写数据了。由于DistributedFileSystem.create()方法只是在文件系统目录树中创建了一个空文件,并没有申请任何数据块,所以DFSOutputStream会首先调用ClientProtocol.addBlock()向Namenode申请一个新的空数据块,addBlock()方法会返回一个LocatedBlock对象,这个对象保存了存储这个数据块的所有数据节点的位置信息。获得了数据流管道中所有数据节点的信息后,DFSOutputStream就可以建立数据流管道写数据块了。
通过数据流管道写入数据:成功地建立数据流管道后,HDFS客户端就可以向数据流管道写入数据了。写入DFSOutputStream中的数据会被缓存在数据流中,之后这些数据会被切分成一个个数据包(packet)通过数据流管道发送到所有数据节点。通过数据流管道依次写入数据节点的本地存储。每个数据包都有一个确认包,确认包会逆序通过数据流管道回到输出流。输出流在确认了所有数据节点已经写入这个数据包之后,就会从对应的缓存队列删除这个数据包。当客户端写满一个数据块之后,会调用addBlock()申请新的数据块,然后循环执行上述操作。
关闭输入流并提交文件:当HDFS客户端完成了整个文件中所有数据块的写操作之后,就可以调用close()方法关闭输出流,并调用ClientProtocol.complete()方法通知Namenode提交这个文件中的所有数据块,也就完成了整个文件的写入流程。
写文件时,数据流管道中的数据节点出现故障,则输出流会进行下面操作来进行故障恢复。
输出流中缓存的没有确认的数据包会重新加入发送队列。但输出流会通过调用ClientProtocol.updateBlockForPipeline()方法为数据块申请一个新的时间戳,然后重新建立管道。这种机制保证了故障Datanode上的数据块会过期,然后在故障恢复后,由于数据块的时间戳与Namenode元数据中的不匹配而被删除。
故障数据节点会从输出流管道中删除,然后输出流会通过调用ClientProtocol.getAdditionalDatanode()方法通知Namenode分配新的数据节点到数据流管道中。由于新添加的数据节点上并没有存储这个新的数据块,这时HDFS客户端会通过DataTransferProtocol通知数据流管道中的一个Datanode复制这个数据块到新的Datanode上。
数据流管道重新建立之后,输出流会调用ClientProtocol.updatePipeline()更新Namenode中的元数据。
2.3 客户端追加写流程
- 打开已有的HDFS文件:客户端调用DistributedFileSystem.append()方法打开一个已有的HDFS文件,append()方法首先会调用ClientProtocol.append()方法获取文件最后一个数据块的位置信息,如果文件的最后一个数据块已经写满则返回null。然后append()方法会调用DFSOutputStream.newStreamForAppend()方法创建到这个数据块的DFSOutputStream输出流对象,获取文件租约,并将新构建的DFSOutputStream方法包装为HdfsDataOutputStream对象,最后返回。
- 建立数据流捅到:DFSOutputStream类的构造方法会判断文件最后一个数据块是否已经写满,如果没有写满,则根据ClientProtocol.append()方法返回的该数据块的位置信息建立到该数据块的数据流管道;如果写满,则调用ClientProtocol.addBlock()向Namenode申请一个新的空数据块之后建立数据流管道。
- 通过数据流管道写入数据:成功建立数据流管道后,HDFS客户端就可以向数据流管道写入数据(这部分和写HDFS文件流程类似)。
- 关闭输入流并提交文件:这部分和写HDFS文件流程类似
2.4 Datanode启动、心跳以及执行名字节点指令流程
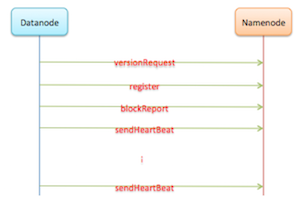
Datanode启动时会首先通过DatanodeProtocol.versionRequest()获取Namenode的版本号以及存储信息等,然后Datanode会对NameNode的当前软件版本号和Datanode的当前软件版本号进行比较,确保它们是一致的。
成功地完成握手操作后,Datanode会通过DatanodeProtocol.register()方法向Namenode注册。Namenode接收到注册请求后,会判断当前Datanode的配置是否属于这个集群,它们之间的版本号是否一致。
注册成功之后,Datanode就需要将本地存储的所有数据块以及缓存的数据块上报到Namenode,Namenode会利用这些信息重新建立内存中数据块与Datanode之间的对应关系。
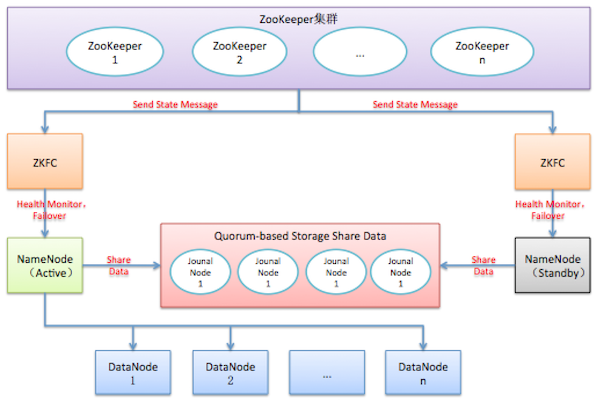
2.5 HA切换流程
3. RPC
3.1 概述
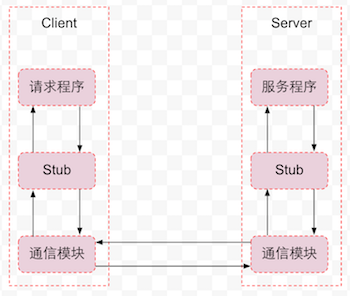
- 通信模块:传输RPC请求和响应的网络通信模块,可以基于TCP协议,也可以基于UDP协议,可以是同步,也可以是异步的。
- 客户端Stub程序:服务器和客户端都包括Stub程序。在客户端,Stub程序表现的就像本地程序一样,但底层却会将调用请求和参数序列化并通过通信模块发送给服务器。之后Stub程序等待服务器的响应信息,将响应信息反序列化并返回给请求程序。
- 服务器端Stub程序:在服务器端,Stub程序会将远程客户端发送的调用请求和参数反序列化,根据调用信息触发对应的服务程序,然后将服务程序返回的响应信息序列化并发回客户端。
- 请求程序:请求程序会像调用本地方法一样调用客户端Stub程序,然后接收Stub程序返回的响应信息。
- 服务程序:服务器会接收来自Stub程序的调用请求,执行对应的逻辑并返回执行结果。
3.2 Hadoop RPC的使用
通信模块
Hadoop实现了org.apache.hadoop.ipc.Client类以及org.apache.hadoop.ipc.Server类提供的基于TCP/IP Socket的网络通信功能。
同时为了RPC机制更加健壮,Hadoop RPC允许客户端配置使用不同的序列化框架(例如protobuf、avro)。
服务器端,为了提高性能,Server类采用了Java NIO提供的基于Reactor设计模式的事件驱动I/O模型,当Server完整地从网络接收一个RPC请求后,会调用call()方法响应这个请求。
客户端Stub程序
客户端的Stub可以看作是一个代理对象,它会将请求程序的RPC调用序列化,并调用Client.call()方法将该请求发送给远程服务器。
Hadoop定义了RpcEngine接口抽象使用不同序列化框架的RPC引擎,该接口包括两个重要方法:
- getProxy():客户端会调用RpcEngine.getProxy()方法获取一个本地接口的代理对象,然后在这个代理对象上调用本地接口的方法(RpcInvocationHandler)。这个对象会将请求序列化,并调用Client.call()发送请求,同时RpcInvocationHandler会将响应信息反序列化并返回给调用程序。
- getServer():该方法用于产生一个RPC Server对象,服务器会启动这个Server对象监听客户端发来的请求。成功从网络接收请求数据后,Server对象会调用RpcInvoker(在RpcEngine的实现类中定义)对象处理这个请求。
服务器端Stub程序
服务器端Stub程序会将通信模块接收的数据反序列化,然后调用服务程序对应的方法响应这个RPC请求。
3.3 Client发送请求与接收响应流程
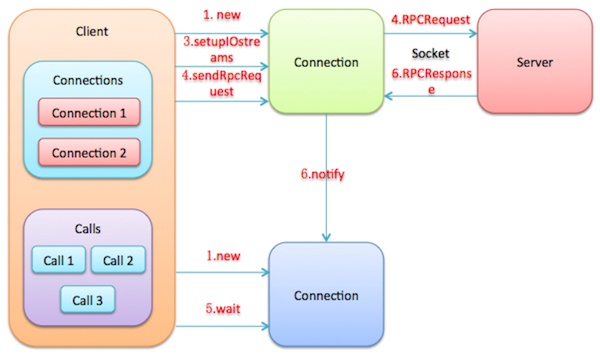
- Client.call()方法将RPC请求封装成一个Call对象,Call对象中保存了RPC调用的完成标志、返回值信息以及异常信息;随后,Client.call()方法会创建一个Connection对象,Connection对象用于管理Client与Server的Socket连接。
- 用ConnectionId作为key,将新建的Connection对象放入Client.connections字段中保存(对于Connection对象,由于涉及了与Server建立Socket连接,会比较耗费资源,所以Client类使用一个HashTable对象connections保存那些没有过期的Connection,如果可以复用,则复用这些Connection对象);以callId作为key,将构造的Call对象放入Connection.calls字段中保存。
- Client.call()方法调用Connection.setupIOstreams()方法建立与Server的Socket连接。setupIOstreams()方法还会启动Connection线程,Connection线程会监听Socket并读取Server发回的响应信息。
- Client.call()方法调用Connection.sendRpcRequest()方法发送RPC请求到Server。
- Client.call()方法调用Call.wait()在Call对象上等待,等待Server发回响应信息。
- Connection线程收到Server发回的响应信息,根据响应信息中携带的信息找到对应的Call对象,然后设置Call对象的返回值字段,并调用call.notify()唤醒调用Client.call()方法的线程读取Call对象的返回值。
3.4 Server接收请求与发送响应流程
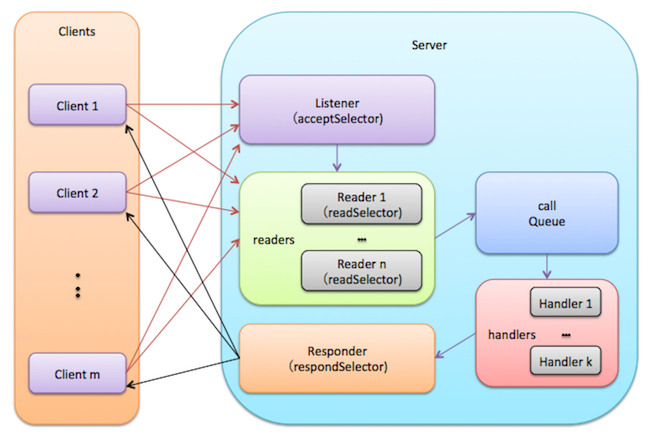
Server类的设计是一个典型的多线程加多Reactor的网络服务器结构。Server类处理RPC请求的流程如下:
- Listener线程acceptSelector在ServerSocketChannel上注册OP_ACCEPT事件,并且创建readers线程池。每个Reader的readSelector此时并不监听任何Channel。
- Client发送Socket连接请求,触发Listener的acceptSelector唤醒Listener线程。
- Listener调用ServerSocketChanel.accept()创建一个新的SocketChannel。
- Listener从readers线程池中挑选一个线程,并在Reader的readSelector上注册OP_READ事件。
- Client发送RPC请求数据包,触发Reader的selector唤醒Reader线程。
- Reader从SocketChannel中读取数据,封装成Call对象,然后放入共享队列CallQueue中。
- 最初,handlers线程池中的线程都在CallQueue(调用BlockingQueue.take())上阻塞,当有Call对象被放入后,其中一个Handler线程被唤醒,然后根据Call对象的信息调用BlockingService对象的callBlockingMethod()方法。随后,Handler尝试将响应写入SocketChannel。
- 如果Handler发现无法将响应完全写入SocketChannel时,将在Responder的respondSelector上注册OP_WRITE事件。当Socket恢复正常时,Responder将被唤醒,继续写响应。当然,如果一个Call响应在一定时间内都无法被写入,则会被Responder移除。















 1726
1726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









