







表1:Student
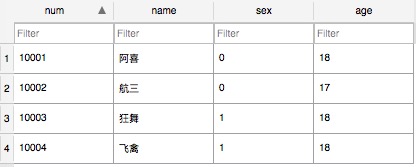
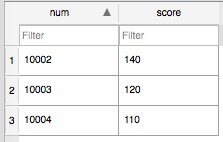
表2:CourseYuwen 语文分数
一、外连接
外连接分:左连接、右连接、完全外连接。
1.左连接 left join 或 left outer join
SQL语句:select * from Student left join CourseYuwen on Student.num = CourseYuwen.num
结果:
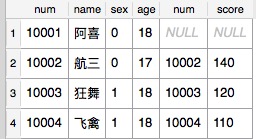
左外连接包含left join左表所有行,如果左表中某行在右表没有匹配,则结果中对应行右表的部分全部为空(NULL).
注:此时我们不能说结果的行数等于左表数据的行数。当然此处查询结果的行数等于左表数据的行数,因为左右两表此时为一对一关系。
2、右连接 right join 或 right outer join
SQL语句:select * from Student right join CourseYuwen on Student.num = CourseYuwen.num
结果:
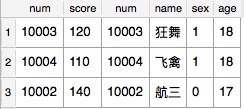
右外连接包含right join右表所有行,如果左表中某行在右表没有匹配,则结果中对应左表的部分全部为空(NULL)。
注:同样此时我们不能说结果的行数等于右表的行数。当然此处查询结果的行数等于左表数据的行数,因为左右两表此时为一对一关系。
3、完全外连接 full join 或 full outer join
SQL语句:select * from Student full join CourseYuwen on Student.num = CourseYuwen.num
二、内连接 join 或 inner join
SQL语句:select * from Student inner join CourseYuwen on Student.num=CourseYuwen.num
结果:
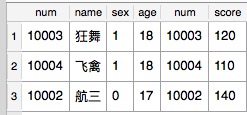
inner join 是比较运算符,只返回符合条件的行。
此时相当于:select * from Student,CourseYuwen where Student.num=CourseYuwen.num
三、交叉连接 cross join
概念:没有 WHERE 子句的交叉联接将产生连接所涉及的表的笛卡尔积。第一个表的行数乘以第二个表的行数等于笛卡尔积结果集的大小。
SQL语句:select * from student cross join courseyuwen
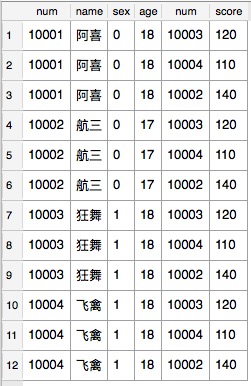
如果我们在此时给这条SQL加上WHERE子句的时候,比如SQL:
select * from student cross join courseyuwen where student.num=courseyuwen.num
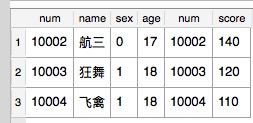
四、两表关系为一对多,多对一或多对多时的连接语句
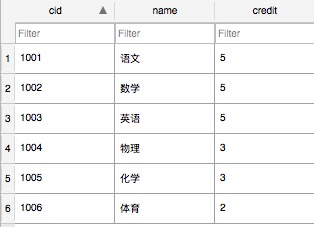
表3:Course 学分
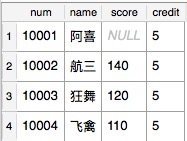
选出语文有分数的学生,并显示语文占有的分数和学分
SQL语句:select s.num,s.name,cy.score,c.credit from Student as s left join CourseYuwen as cy on s.num=cy.num left join Course as c on c.cid=1002
结果:














 1524
1524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









