







1. RCFile
RCFile文件格式是FaceBook开源的一种Hive的文件存储格式,首先将表分为几个行组,对每个行组内的数据进行按列存储,每一列的数据都是分开存储,正是先水平划分,再垂直划分的理念。
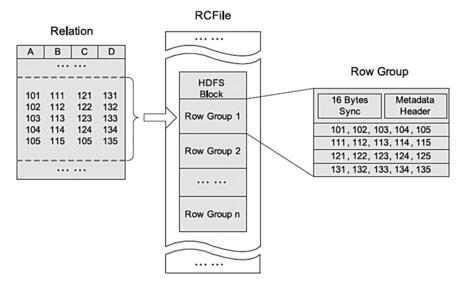
在存储结构上:
如上图是HDFS内RCFile的存储结构,我们可以看到,首先对表进行行划分,分成多个行组。一个行组主要包括:16字节的HDFS同步块信息,主要是为了区分一个HDFS块上的相邻行组;元数据的头部信息主要包括该行组内的存储的行数、列的字段信息等等;数据部分我们可以看出RCFile将每一行,存储为一列,将一列存储为一行,因为当表很大,我们的字段很多的时候,我们往往只需要取出固定的一列就可以。
在一般的行存储中 select a from table,虽然只是取出一个字段的值,但是还是会遍历整个表,所以效果和select * from table 一样,在RCFile中,像前面说的情况,只会读取该行组的一行。
在一般的列存储中,会将不同的列分开存储,这样在查询的时候会跳过某些列,但是有时候存在一个表的有些列不在同一个HDFS块上(如下图),所以在查询的时候,Hive重组列的过程会浪费很多IO开销。
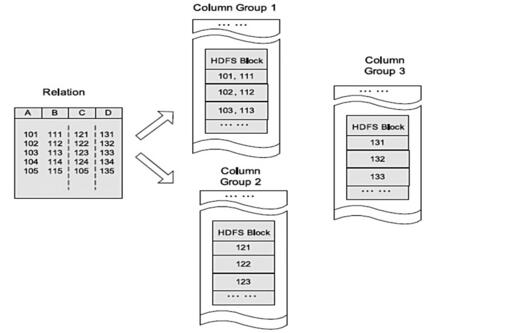
而RCFile由于相同的列都是在一个HDFS块上,所以相对列存储而言会节省很多资源。
在存储空间上:
RCFile采用游程编码,相同的数据不会重复存储,很大程度上节约了存储空间,尤其是字段中包含大量重复数据的时候。
懒加载:
数据存储到表中都是压缩的数据,Hive读取数据的时候会对其进行解压缩,但是会针对特定的查询跳过不需要的列,这样也就省去了无用的列解压缩。
select c from table where a>1针对行组来说,会对一个行组的a列进行解压缩,如果当前列中有a>1的值,然后才去解压缩c。若当前行组中不存在a>1的列,那就不用解压缩c,从而跳过整个行组。
2.ORCFile
ORC是在一定程度上扩展了RCFile,是对RCFile的优化。
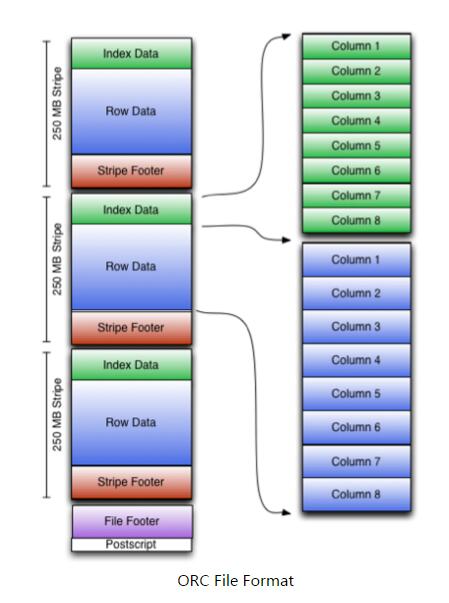
存储结构上
根据结构图,我们可以看到ORCFile在RCFile基础上引申出来Stripe和Footer等。每个ORC文件首先会被横向切分成多个Stripe,而每个Stripe内部以列存储,所有的列存储在一个文件中,而且每个stripe默认的大小是250MB,相对于RCFile默认的行组大小是4MB,所以比RCFile更高效。
Postscripts中存储该表的行数,压缩参数,压缩大小,列等信息
Stripe Footer中包含该stripe的统计结果,包括Max,Min,count等信息
FileFooter中包含该表的统计结果,以及各个Stripe的位置信息
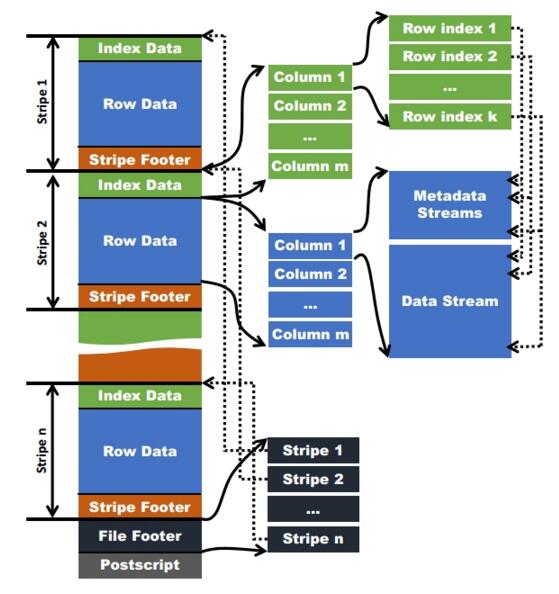
IndexData中保存了该stripe上数据的位置信息,总行数等信息
RowData以stream的形式保存了数据的具体信息Hive读取数据的时候,根据FileFooter读出Stripe的信息,根据IndexData读出数据的偏移量从而读取出数据。
网友有一幅图,形象的说明了这个问题:
存储空间上
ORCFile扩展了RCFile的压缩,除了Run-length(游程编码),引入了字典编码和Bit编码。
采用字典编码,最后存储的数据便是
字典中的值,每个字典值得长度以及字段在字典中的位置
至于Bit编码,对所有字段都可采用Bit编码来判断该列是否为null,
如果为null则Bit值存为0,否则存为1,对于为null的字段在实际编码的时候不需要存储,也就是说字段若为null,是不占用存储空间的。
参考:
http://www.csdn.net/article/2011-04-29/296900
http://blog.csdn.net/dabokele/article/details/51542327
http://blog.csdn.net/dabokele/article/details/51813322
http://www.jdl.ac.cn/user/lyqing/SourceCoding/03_18-Dictionary.pdf















 2877
2877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









