




 本文详细介绍了Adaboost算法的基本原理及其改进版本,包括Discrete Adaboost、Real Adaboost、LogitBoost等,并提供了Python实现示例,展示了如何通过组合弱分类器构建强分类器。
本文详细介绍了Adaboost算法的基本原理及其改进版本,包括Discrete Adaboost、Real Adaboost、LogitBoost等,并提供了Python实现示例,展示了如何通过组合弱分类器构建强分类器。
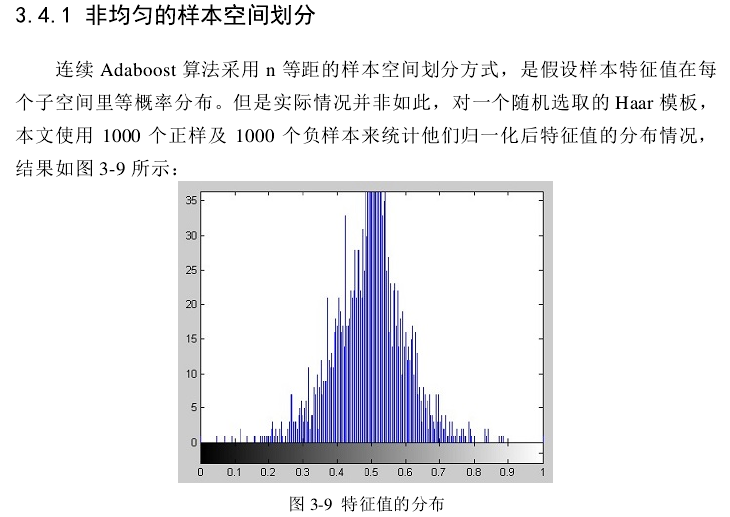
基本adaboost算法
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。AdaBoost是一种具有一般性的分类器提升算法,它使用的分类器并不局限某一特定算法。
其算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。将修改过权值的新数据集送给下层分类器进行训练,最后将每次训练得到的分类器最后融合起来,作为最后的决策分类器。
整个过程如下所示:
1.先通过对N个训练样本的学习得到第一个弱分类器;
2.将分错的样本和其他的新数据一起构成一个新的N个的训练样本,通过对这个样本的学习得到第二个弱分类器;
3.将1和2都分错了的样本加上其他的新样本构成另一个新的N个的训练样本,通过对这个样本的学习得到第三个弱分类器;
4.如此反复,最终得到经过提升的强分类器。


权值更新的公式具体如下:

基本adaboost的改进
以上说的adaboost是通常我们见到的adaboost算法,即discrete adaboost,很像聚类中的硬聚类,很生硬,非此即彼,其实现实中往往不那么分明,所以对应有模糊聚类。自然想到有没有模糊的adaboost呢?有,请看下面:





其实我们最开始介绍的就是这个广义adaboost,也是最常见的。注意,下面的g可以取[-1,1]之间连续的值。






Real Adaboost训练估计大部分人看起来还是挺费解的,举个例子说明一下。在堪称经典的《fast rotation invariant multi-view face detection based on real adaboost》一文中,就用到了real adaboost。首先,论文从滑动窗口中提取了很多haar特征,然后对于每一个haar特征,将其归一化到[0,1],再对其做64等分。也就是说把0-1等分成了64份,这就是划分的若干个互不相交的子空间。接下来在这64个子空间里面计算正负样本的带权和W(+1)、W(-1),再用这两个值计算弱分类器输出和归一化因子Z。最终选择Z最小的那一个haar特征上的弱分类器作为该轮迭代选取出的弱分类器。这个弱分类器,其实就是对于64个子空间有64个对应的实数输出值。在预测时,如果把64个值保存到数组中,我们就可以使用查表的方式来计算任意输入特征对应的分类器输出了。假设输入的haar特征是0.376(已经归一化了),0.376/(1/64)=24.064,那么这个值落在了第24个子空间中,也就是数组中的第24个元素的值。即当前弱分类器的输出值。最后我们再将所有弱分类器的输出求和,并设置好阈值b,就可以得到最终的强分类器输出结果了。


LUT(look-up table)型real adaboost弱分类器训练算法





logitboost




整体效果而言,效果由好到差的顺序为Logit Boost,Gentle AdaBoost, Real AdaBoost, Discrete AdaBoost
浮动搜索是指:在向前搜索同时保留了回溯的机制,在一个新的弱分类器生成时都判断它是否比之前的弱分类器更能提高强分类器的性能,如果答案是肯定的,则删除掉前面的分类器。浮动搜索的引入保证学习算法的单调性。
算法实例
<span style="font-size:14px;">import numpy as np
import matplotlib.pyplot as plt
#train_data
N = 300 # number of points per class
D = 2 # dimensionality
K = 2 # number of classes
X = np.zeros((N*K,D)) # data matrix (each row = single example)
Y = np.zeros(N*K) # class labels
for j in xrange(K):
ix = range(N*j,N*(j+1))
r = np.linspace(0.0,1,N) # radius
t = np.linspace(j*4,(j+1)*4,N) + np.random.randn(N)*0.2 # theta
X[ix] = np.c_[r*np.sin(t), r*np.cos(t)]
Y[ix] = j
if j==0:Y[ix] =-1
#test_data
NN=100
X_test = np.zeros((NN*K,D)) # data matrix (each row = single example)
Y_test = np.zeros(NN*K) # class labels
for j in xrange(K):
ix = range(NN*j,NN*(j+1))
r = np.linspace(0.0,1,NN) # radius
t = np.linspace(j*4,(j+1)*4,NN) + np.random.randn(NN)*0.2 # theta
X_test[ix] = np.c_[r*np.sin(t), r*np.cos(t)]
Y_test[ix] = j
if j==0:Y_test[ix] =-1
# lets visualize the data:
plt.scatter(X[:, 0], X[:, 1], c=Y, s=40, cmap=plt.cm.Spectral)
plt.show()
plt.scatter(X_test[:, 0], X_test[:, 1], c=Y_test, s=40, cmap=plt.cm.Spectral)
plt.show()
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):#just classify the data
retArray = np.ones((np.shape(dataMatrix)[0],1))
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1
return retArray
def buildStump(dataArr,classLabels,D):
dataMatrix = np.mat(dataArr);
labelMat = np.mat(classLabels).T
m,n = np.shape(dataMatrix)
numSteps = 10.0;
bestStump = {};
bestClasEst = np.mat(np.zeros((m,1)))
minError = np.inf #init error sum, to +infinity
for i in range(n):#loop over all dimensions
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max();
stepSize = (rangeMax-rangeMin)/numSteps
for j in range(-1,int(numSteps)+1):#loop over all range in current dimension
for inequal in ['lt', 'gt']: #go over less than and greater than
threshVal = (rangeMin + float(j) * stepSize)
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)#call stump classify with i, j, lessThan
errArr = np.mat(np.ones((m,1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T*errArr #calc total error multiplied by D
#print "split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError)
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEst
def adaBoostTrainDS(dataArr,classLabels,numIt=20):
weakClassArr = []
m = np.shape(dataArr)[0]
D = np.mat(np.ones((m,1))/m) #init D to all equal
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(numIt):
bestStump,error,classEst = buildStump(dataArr,classLabels,D)#build Stump
#print "D:",D.T
alpha = float(0.5*np.log((1.0-error)/max(error,1e-16)))#calc alpha, throw in max(error,eps) to account for error=0
bestStump['alpha'] = alpha
weakClassArr.append(bestStump) #store Stump Params in Array
#print "classEst: ",classEst.T
expon = np.multiply(-1*alpha*np.mat(classLabels).T,classEst) #exponent for D calc, getting messy
D = np.multiply(D,np.exp(expon)) #Calc New D for next iteration
D = D/D.sum()
#calc training error of all classifiers, if this is 0 quit for loop early (use break)
aggClassEst += alpha*classEst
#print "aggClassEst: ",aggClassEst.T
aggErrors = np.multiply(np.sign(aggClassEst) != np.mat(classLabels).T,np.ones((m,1)))
errorRate = aggErrors.sum()/m
print "total error: ",errorRate
if errorRate == 0.0: break
return weakClassArr,aggClassEst
def adaClassify(datToClass,classifierArr):
dataMatrix = np.mat(datToClass)#do stuff similar to last aggClassEst in adaBoostTrainDS
m = np.shape(dataMatrix)[0]
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],classifierArr[i]['thresh'], classifierArr[i]['ineq'])#call stump classify
aggClassEst += classifierArr[i]['alpha']*classEst
print aggClassEst
return np.sign(aggClassEst)
weakClassArr,aggClassEst=adaBoostTrainDS(X,Y)
test_num=np.shape(X_test)[0]
print test_num
aa=adaClassify(X_test,weakClassArr)
aa.reshape(test_num)
cnt=0
for i in range(test_num):
if Y_test[i]==aa[i]:
cnt+=1
print cnt/float(test_num)
</span>
测试数据如上图,先生成600个训练数据,得到20个弱分类器的组合,然后在200个测试数据上可以达到95%的准确率。

















 615
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









