







引言
博主希望通过最通俗的语言理解感知机,里面大白话可能比较多,适合刚刚接触感知机的学习者。大牛请绕路
感知机
感知机是由两层神经元组成,其中一层为输入层,另外一层为输出层。输入层用来接收外界的输入信号,而输出层用来将结果输出。感知机一般用来进行二元数据的分类。感知机的思想主要是通过找到一个超平面,使用这个超平面将数据进行分开。
感知机详解

例如有一个数据集T={
(x1,y1),(x2,y2),(x3,y3)...
},将其数据描述在上图中,上图中红色以及蓝色数据为数据集T。我们将其中涉及到的两个类别记作1(表示正类)和-1(表示负类)。我们通过找到一个超平面即上图中黑色的直线将数据分开。由于我们可以找到这条直线,因此数据集T为可分数据集。我们使用的直线为
z=wTx
其中, w=[w1,w2,...,wm]T , x=[x1,x2,...,xm]T ,我们得到这样一条直线用于分类,可输出为一个函数值
那我们怎样将其归为哪一个类奥,因此就需要设置阈值,当输出的函数值y大于设置的阈值,则归为+1类,否则归为-1类。在这里我们使用一个激活函数,将输出的y输入激活函数,激活函数就输出1或者-1.激活函数到底是什么呢,我们看下图,一般使用阶跃函数或者是sigmoid函数。

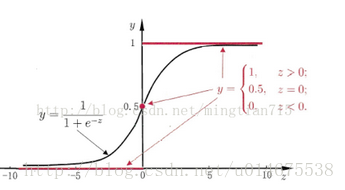
上面的这幅图就是阶跃函数,下面这个就是sigmoid函数,由于阶跃函数不连续,因此求导不方便,因此在实际使用过程中基本上都是sigmoid函数。
因为我们现在找到的这条直线可能不是最优的,这句话什么意思呢,就是对于有些样本是错分类的,这里就不用图表示,接下来就需要根据输出结果来调整权重w了。
wj=wj+Δwj
Δwj=η(y(i)−y(i)⎯⎯⎯⎯⎯)
其中 η 表示学习速率,通常取值为 [0,1]
通过输出就完成了权重的调整。
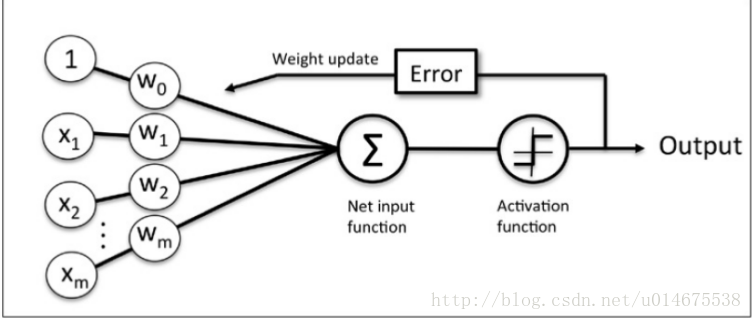
感知机实验部分
接下来我们使用python动手练习一下
import numpy as np
class Perceptron(object):
def __init__(self,eta = 0.1,n_iter = 10):
self.eta = eta
self.n_iter = n_iter
def fit(self,X,y):
self.w_ = np.zeros(1+X.shape[1])
self.errors = []
for _ in range(self.n_iter):
errors = 0
for feature, target in zip(X, y):
update =target - self.predict(feature)
self.w_[1:] += update*feature
self.w_[0] += update
errors += int(update != 0.0)
self.errors.append(errors)
def net_input(self,X):
return np.dot(X,self.w_[1:]+self.w_[0])
def predict(self,X):
return np.where(self.net_input(X)>0.0,1,-1)上面的这一段为算法的核心代码
import pandas as pd
from perceptron.Perceptron import *
from perceptron.plot_decision_region import *
df = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data",header = None)
y = df.iloc[0:100,4].values
y = np.where(y=='Iris-setosa',-1,1)
X = df.iloc[0:100,[0,2]].values
plt.scatter(X[:50,0],X[:50,1],color = 'red',marker='o',label = 'setosa')
plt.scatter(X[50:100,0],X[50:100,1],color = 'blue',marker='x',label = 'versicolor')
plt.xlabel('petal length')
plt.ylabel('sepal length')
plt.legend(loc = 'upper left')
plt.show()
ppn = Perceptron(eta=0.1,n_iter = 10)
ppn.fit(X,y)
plt.plot(range(1,len(ppn.errors)+1),ppn.errors,marker = 'o')
plt.xlabel('iter')
plt.ylabel('mistakes class')
plt.show()
plot_decision_region(X,y,classifier = ppn)
plt.xlabel('sepal length[cm]')
plt.ylabel('petal length[cm]')
plt.legend(loc = 'upper left')
plt.show()from matplotlib.colors import ListedColormap
import numpy as np
import matplotlib.pyplot as plt
def plot_decision_region(X,y,classifier,resolution = 0.02):
markers = ('s','x','o','^','v')
colors = ('red','blue','lightgreen','gray','cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
x1_min,x1_max = X[:,0].min()-1,X[:,0].max()+1
x2_min,x2_max = X[:,1].min()-1,X[:,1].max()+1
xx1,xx2 = np.meshgrid(np.arange(x1_min,x1_max,resolution),
np.arange(x2_min,x2_max,resolution))
Z = classifier.predict(np.array([xx1.ravel(),xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1,xx2,Z,alpha = 0.4,cmap = cmap)
plt.xlim(xx1.min(),xx1.max())
plt.ylim(xx2.min(),xx2.max())
for idx,cl in enumerate(np.unique(y)):
plt.scatter(x = X[y==cl,0],y = X[y==cl,1],
alpha=0.8,c = cmap(idx),
marker=markers[idx],label = cl)
总结
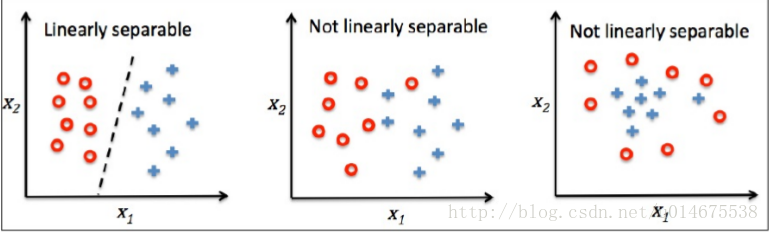
感知机对于先行可分的数据集可以适用,对于那些线性不可分的数据无法工作。第2张图片和第3张就是线性不可分的数据集。对于这些数据的处理,后面会讲解处理办法。














 1610
1610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









