







特征工程
1 前言
在机器学习界,有这么一种说法:数据和特征决定了机器学习的上限,而算法和模型只是逼近这个上限。
所谓特征工程,是指使用专业的知识处理数据,使得特征能在算法上发挥更好的作用。特征工程关键是贴近业务找出高效的特征。
特征工程包括特征使用方案、特征获取方案、特征处理、特征监控,框架如下图:
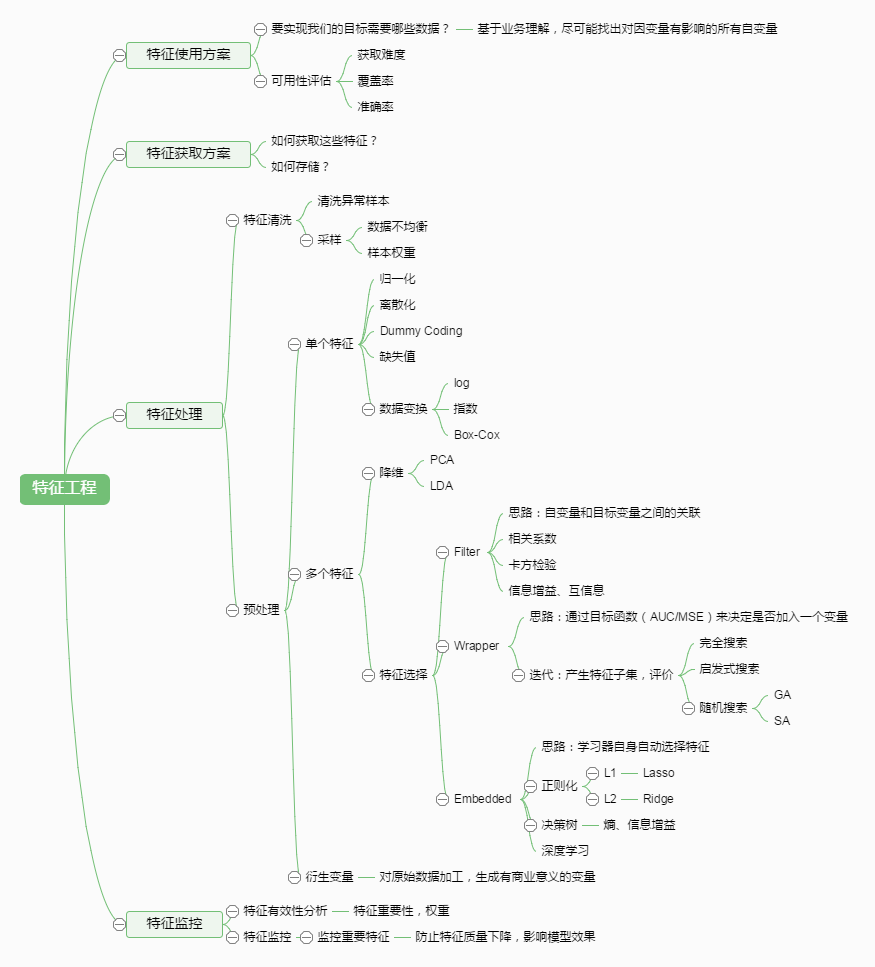
特征处理是特征工程中的核心部分, Scikit-Learn是python的机器学习库,包括Classification(分类)、Clustering(聚类)、Regression(回归)、Dimensionalityreduction(降维)、
Model selection(模型选择)、Preprocessing(预处理)六个部分,预处理对特征处理提供了很好的支持。
2 特征工程
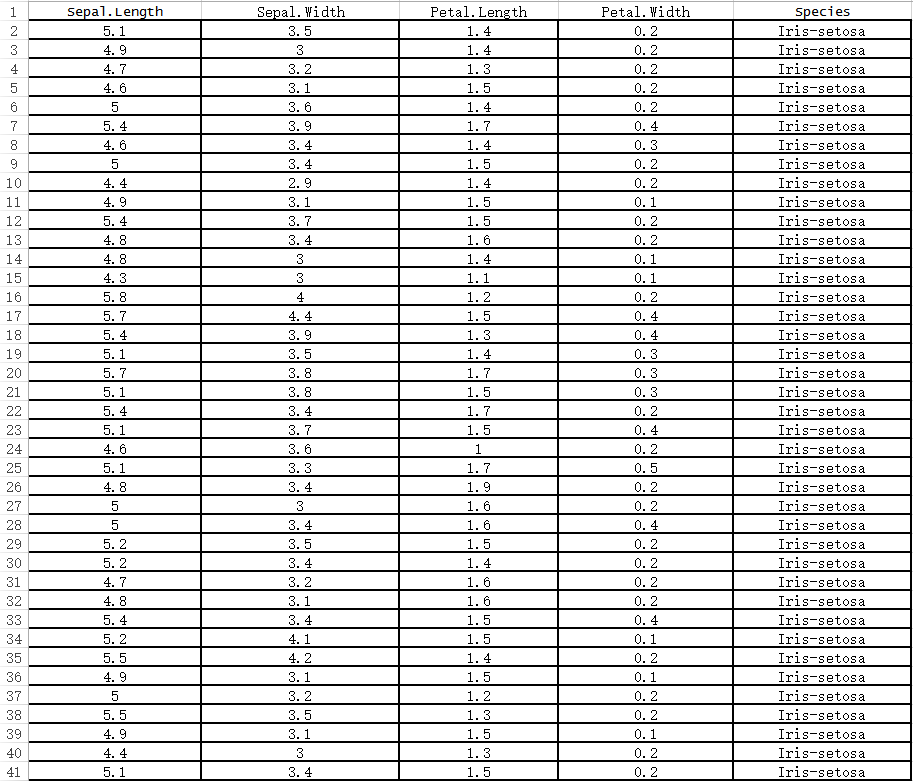
以sklearn中的Iris(鸢尾花)数据集为例对特征处理进行说明。Iris(鸢尾花)数据集每条数据包含4个特征(Sepal.Length(花萼长度)、Sepal.Width(花萼宽度)、Petal.Length(花
瓣长度)、Petal.Width(花瓣宽度)),特征值都为正浮点数,单位为厘米。目标是把该数据集分成3类Iris-setosa(山鸢尾)、Iris-versicolor (杂色鸢尾),Iris-virginica (维吉尼亚鸢
尾)。数据集如图:
2.1 查看iris 数据集
#encoding=utf-8
from sklearn.datasets import load_iris
#iris数据集是一个类字典对象
# 数据存在.data成员中,标签存在.target成员中
#导入iris数据集
iris=load_iris()
# the full description of the dataset
print iris.DESCR
# the data to learn
# type ndarray
print iris.data
# the meaning of the features
print iris.feature_names
# the classification labels
print iris.target
# the meaning of the labels
print iris.target_names
2.2 最大值 最小值 中位数均值方差
import numpy as np
#所有数据 最大值、最小值、中位数、均值、方差
print np.max(iris.data)
print np.min(iris.data)
print np.median(iris.data)
print np.mean(iris.data)
print np.std(iris.data)
# 5行3列 最大值、最小值、中位数、均值、方差
print np.max(iris.data[:5,:3])
print np.min(iris.data[:5,:3])
print np.median(iris.data[:5,:3])
print np.mean(iris.data[:5,:3])
print np.std(iris.data[:5,:3])
2.3 处理缺失值(missing value)
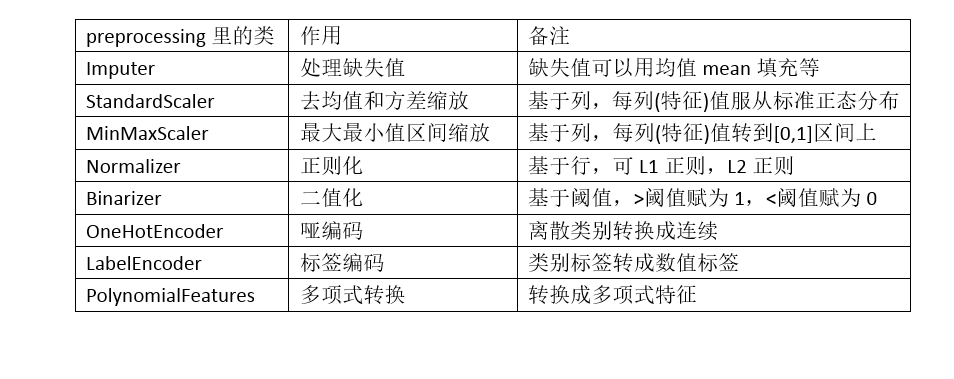
在sklearn的preprocessing预处理包中包含了对缺失值的处理,主要是用Imputer类进行处理。
# 添加一条空数据
missing=np.append(iris.data,[["Nan","Nan","Nan","Nan"]],axis=0)
from sklearn.preprocessing import Imputer
# Nan空值用每一列的均值代替。生产中也可用其他方式。
imp = Imputer(missing_values='NaN', strategy='mean', axis=0)
imp.fit(missing)
print imp.transform(missing)
或者
print Imputer().fit_transform(missing)
2.4 去均值和方差缩放(Z-Score)
每个数据减去其列均值,除以其方差。得到的结果:对于每个属性(每列)来说所有数据都聚集在0附近,方差为1,也就是说标准化后,每列都转换成标准正态分布。主要是用
StandardScaler类进行处理。
公式:
#iris.data第一列数据
print iris.data[:,:1]
#iris.data第一列均值
print np.mean(iris.data[:,:1])
#iris.data第一列方差
print np.std(iris.data[:,:1])
# Z-Score
from sklearn.preprocessing import StandardScaler
print StandardScaler().fit_transform(iris.data)
或者
# 定义类StandardScaler
scaler=StandardScaler(copy=True, with_mean=True, with_std=True)
#fit函数计算the mean and std
scaler.fit(iris.data)
# 每列均值
print scaler.mean_
# 每列方差
print scaler.std_
#转换
print scaler.transform(iris.data)
2.5 用最大最小值区间缩放
每个数据减去其列最小值,除以其列最大值与最小值之差。主要是用MinMaxScaler类进行处理。返回值为缩放到[0, 1]区间的数据。
公式:
from sklearn.preprocessing import MinMaxScaler
print MinMaxScaler().fit_transform(iris.data)
2.6 正则化(Normalization)
去均值和方差缩放与区间缩放都是对特征矩阵的列进行处理,而正则化则是按照特征矩阵的行进行处理。主要是用Normalizer类进行处理。
L1正则化公式:
L2正则化公式:
from sklearn.preprocessing import Normalizer
# L1正则化
print Normalizer(norm='l1', copy=True).fit_transform(iris.data)
# L2正则化
print Normalizer(norm='l2', copy=True).fit_transform(iris.data)
2.7 数值特征二值化(Binarization)
设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0。用Binarizer类进行处理。
公式:
from sklearn.preprocessing import Binarizer
# threshold阈值、门槛
print Binarizer(threshold=1.1).fit_transform(iris.data)
2.8 类别特征哑编码(One-Hot 编码)
每一个特征,如果它有m种情况,那么经过One-Hot编码后,每个特征值就变成了m个状态的特征值,且只有一个是1,其余是0。用OneHotEncoder类进行处理。IRIS数据集的特
征都是数值特征。以以下数据为例。
#每个特征是类别特征
X=[[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]]
from sklearn import preprocessing
#one hot编码
enc = preprocessing.OneHotEncoder()
enc.fit(X)
print enc.transform(X).toarray()
2.9 类别型标签转化成数值型(Label encoding)
用LabelEncoder类进行处理。
#类别型标签转换成数值型
lae = preprocessing.LabelEncoder()
lae.fit(iris.target_names)
print lae.transform(iris.target_names)
2.10产生多项式特征
如:一个输入样本是2维的。形式如[a,b] ,则二阶多项式的特征集如下[1,a,b,a^2,ab,b^2]。用PolynomialFeatures类进行处理,也有基于指数的。
#产生多项式特征
poly = preprocessing.PolynomialFeatures(2)
print poly.fit_transform([[1,2]])
3.总结
参考文章:
http://scikit-learn.org/stable/
http://www.cnblogs.com/chaosimple/p/4153167.html
http://www.cnblogs.com/jasonfreak/p/5448385.html
http://blog.csdn.net/u012102306/article/details/51940147
http://blog.csdn.net/dulingtingzi/article/details/51374487
http://www.cnblogs.com/haobang008/p/5911466.html














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









