







 本文深入探讨了Scrapy在处理大文件下载时遇到MemoryError的问题,分析了其内部机制,并提出了解决方案,包括调整并发度及改进下载机制。
本文深入探讨了Scrapy在处理大文件下载时遇到MemoryError的问题,分析了其内部机制,并提出了解决方案,包括调整并发度及改进下载机制。
scrapy的MemoryError(后续)
问题
之前写过一篇关于scrapy的MemoryError的博客,主要是介绍了MemoryError这个异常出现的原因和解决方案,但是对于其原因的探讨似乎还是不太明了,这次我们来深入探讨一下这个问题。
“`
分析
这个问题真正的原因是因为scrapy在大文件下载时出现的一个bug所致,深入分析其源代码可以发现,其在进行大文件下载的时候,是把所有的数据全部保存在内存中,之后再一次性的写入文件。
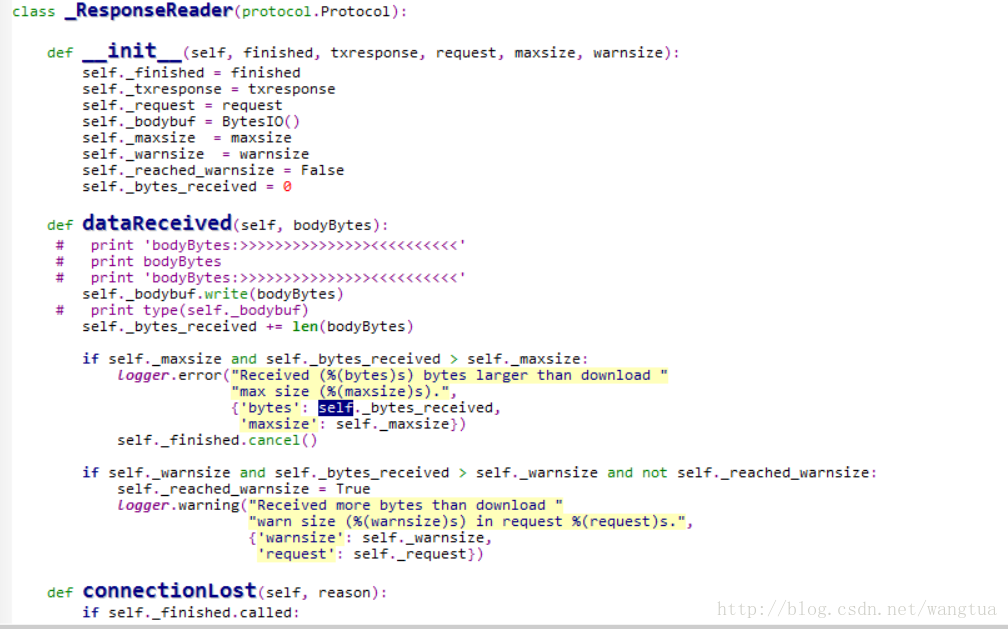
其中dataReceived 方法是twisted定义的可继承方法,用于处理下载下来的数据内容。
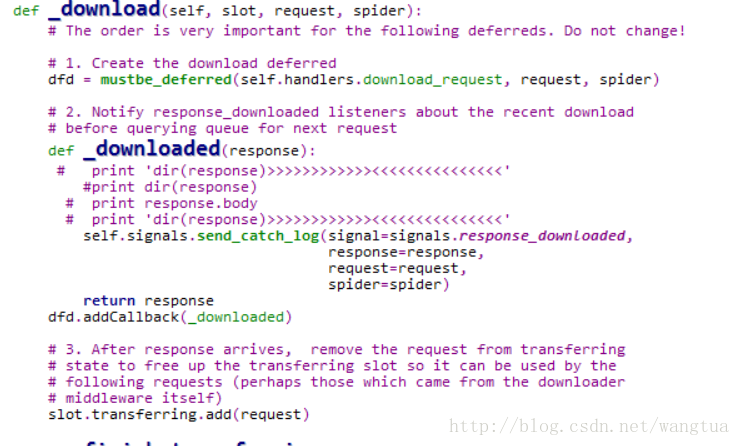
这里的部分是下载完成之后的处理部分,通过添加一些输出我们可以看到其下载的内容会全部写入内存。这对大文件来说十分的不利。
这是一个会在2G内存,ubuntu12的机器上重现该问题的脚本
有一个“治标不治本”的办法就是降低爬虫的并发度,让其每次只进行一个大文件的下载,但是这样的话如果大文件本身大于机器内存大小的话就会出现问题。
更加根本的办法是修改这一机制,可以让大文件下载的过程中下载一部分就写入一部分。
(关于这点,本人已经fork了scrapy的代码库,如果有开发进展会第一时间报告给大家)

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









