 Tomcat中的Executor任务执行器
Tomcat中的Executor任务执行器









 超级会员免费看
超级会员免费看

 Tomcat使用Executor作为任务执行器,这是一个基于线程池的实现,通过ThreadPoolExecutor类提供最大最小线程数限制等功能。Executor分为外部和内部两种,外部Executor可在server.xml配置,如示例所示,而内部Executor则是默认配置。线程池确保快速处理请求,并在无任务时进行线程管理。
Tomcat使用Executor作为任务执行器,这是一个基于线程池的实现,通过ThreadPoolExecutor类提供最大最小线程数限制等功能。Executor分为外部和内部两种,外部Executor可在server.xml配置,如示例所示,而内部Executor则是默认配置。线程池确保快速处理请求,并在无任务时进行线程管理。
上节说到接收器Acceptor在接收到socket后会有一系列简单的处理,其中将socket扔进线程池是最重要的一步,线程池是一个怎样东西?其原理在前面的“线程池原理”章节已经说明过了,这里重点讲tomcat中用于处理客户端请求的线程池——Executor。
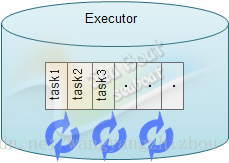
为确保整个web服务器的性能,应该在接到请求后以最快的速度转交到其他线程上去处理。在接收到客户端的请求后tomcat将对这些请求交给任务执行器Executor,它是一个拥有最大最小线程数限制的线程池,之所以称之为“任务执行器”是因为线程池可以看做是启动了若干线程不断检测某个任务队列,一旦发现有需要执行的任务则执行。如下图,每条线程都不断循环检测任务队列,数量不会少于最小线程数也不能大于最大线程数。
任务执行器的具体实现是使用juc工具包的ThreadPoolExecutor类,它提供了拥有多种机制的线程池,例如有最大最小线程数限制、多余线程回收时间限制、超出最大线程数时线程池做出的拒绝动作等等。继承此类并重写一些方法基本就能满足tomcat个性化需求。
Tomcat的Executor分为两种类型:外部Executor和内部Executor。所谓外部Executor则指程序运行时使用server.xml文件配置的Execu

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 415
415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











