







最近有个任务是分析实时日志中出现error信息的统计,包括错误数量,报错的时间等。
想了下决定采用spark + flume。
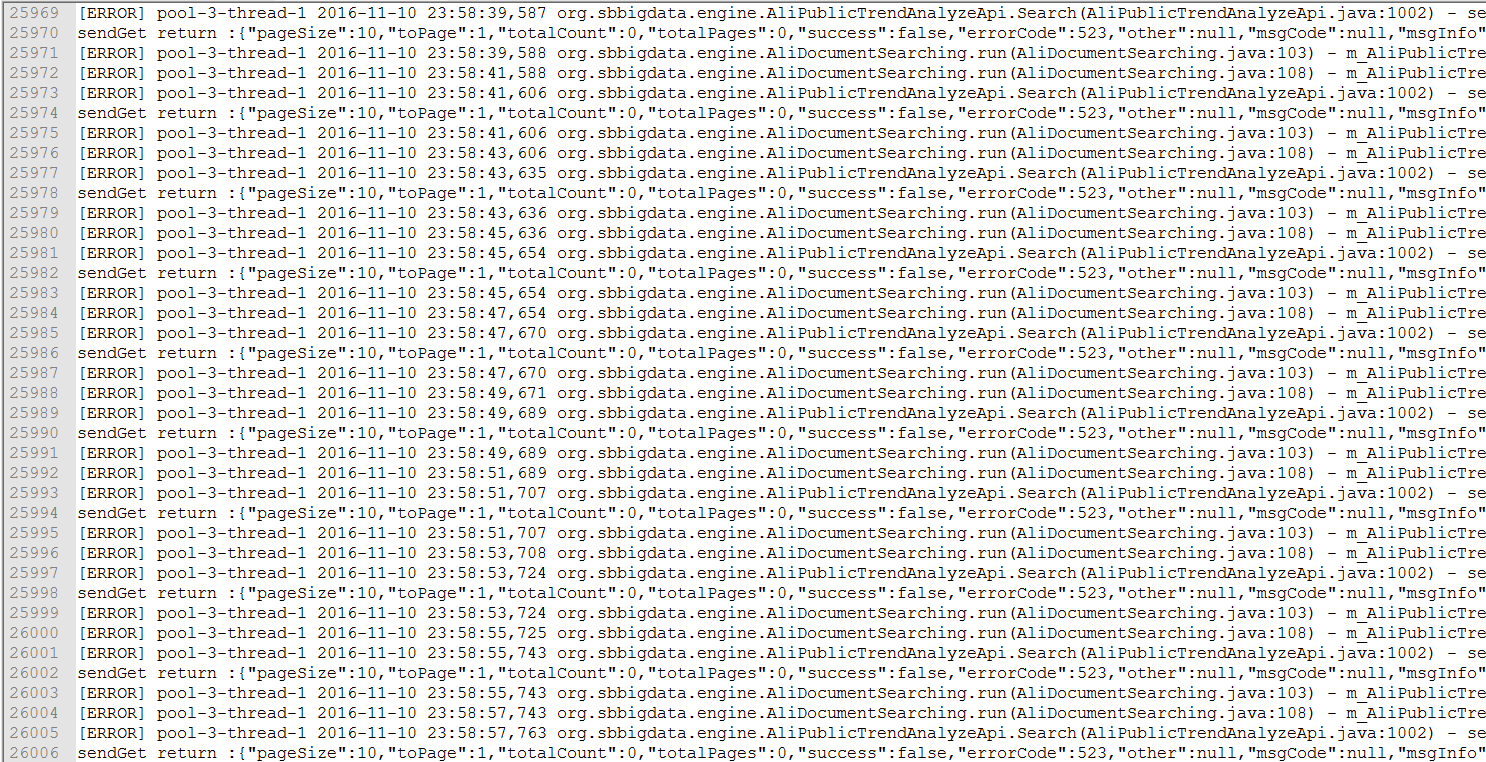
日志格式如下:
环境如下:
scala:2.10.4
spark:1.6.0
flume:apache-flume-1.7.0-bin
flume插件:spark-streaming-flume-assembly_2.11-1.6.0.jar
首先启动spark业务逻辑程序(即处理日志,对日志进行统计)
./bin/spark-submit --jars /home/liudingyi/spark-streaming-flume-assembly_2.11-1.6.0.jar /home/liudingyi/spark-1.6.0-bin-hadoop1/examples/src/main/python/streaming/flume_wordcount.py localhost 3333地址默认为:localhost
端口为:3333
配置flume的配置文件:
复制模板:
flume-conf.properties,内容为:
a1.channels = c1
a1.sinks = k1
a1.sources = r1
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = localhost
a1.sinks.k1.port = 3333
a1.sources.r1.type = avro
a1.sources.r1.bind = localhost
a1.sources.r1.port = 4444
a1.sources.r1.channels = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100启动服务端:
./bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties --name a1 -Dflume.root.logger=INFO,console这里的a1与配置文件中的名字对应。
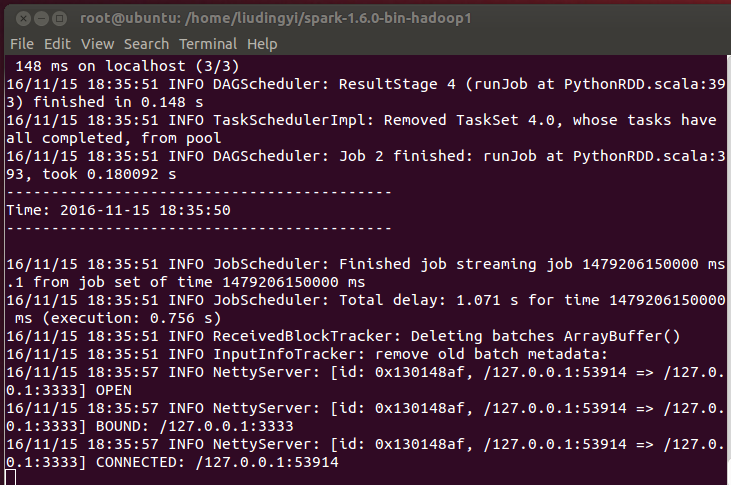
启动客户端发送数据:
./bin/flume-ng avro-client conf conf -H localhost -p 4444 -F /home/liudingyi/apache-flume-1.7.0-bin/1.txt -Dflume.root.logger=DEBUG,console将日志文件1.txt数据流stream发送。
注意这里一共开了三个命令行程序来模拟。
spark运行的程序会将结果显示出来:
结果如下:
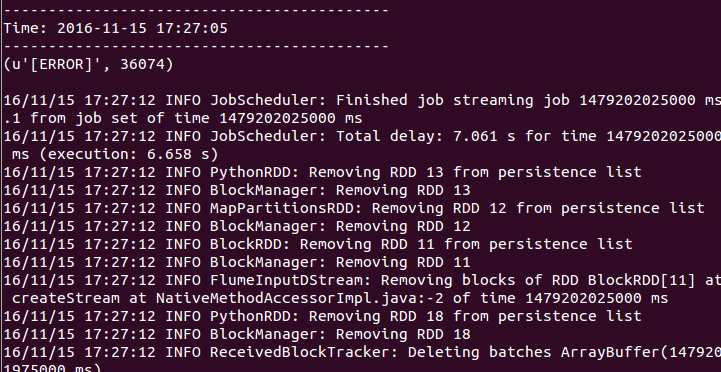
错误数为36074。
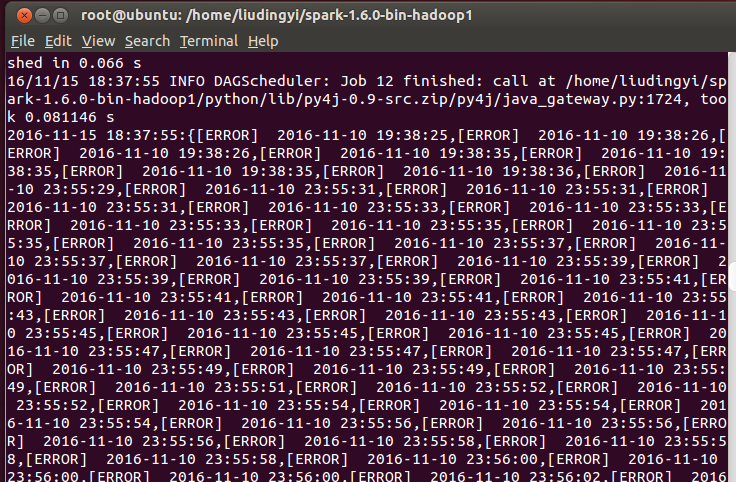
可以看到错误和时间打了出来。
spark程序如下:
#coding:utf-8
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.flume import FlumeUtils
import re
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
# 解析日志
def parse(logstring):
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
regex ='(\[ERROR\].*\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2})'
pattern = re.compile(regex)
replace_reg = re.compile(r'pool-\d{1}-thread-\d{1}')
m1 = pattern.search(logstring)
if m1 is not None:
m = m1.groups(0)[0]
m = replace_reg.sub('', m)
else:
m = None
return m
if __name__ == "__main__":
sc = SparkContext(appName="PythonStreamingFlumeWordCount")
ssc = StreamingContext(sc, 25)
hostname, port = sys.argv[1:]
kvs = FlumeUtils.createStream(ssc, hostname, int(port))
lines = kvs.map(lambda x: x[1])
words = lines.flatMap(lambda line: line.split(" "))
Ecounts = lines.flatMap(lambda line: line.split("\n")) \
.map(lambda word : parse(word)) \
.filter(lambda word:True if word is not None else False)
counts = lines.flatMap(lambda line: line.split(" ")) \
.filter(lambda word : word == '[ERROR]') \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a+b)
def echo(time,rdd):
if rdd.isEmpty() is False:
rddstr = "{"+','.join(rdd.collect())+"}"
print (str(time)+":"+rddstr)
Ecounts.foreachRDD(echo)
counts.pprint()
#counts.pprint()
#lines.pprint()
#l = len(re.findall("[ERROR]", lines))
ssc.start()
ssc.awaitTermination()














 2241
2241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









