









花一个月不到的时间匆匆学的python现在终于得到了一丢丢的用处,一开始学python的初心就是想弄网络爬虫,感觉爬虫这个东西才是最有意思的部分,后来发现爬取那么多的数据,最后需要的还是要对数据进行分析和探究数据背后的奥秘,这样的进阶路线只是学习python爬虫的其中一个目标,这也是题主学python的一个主要原因,之后就是往人工智能和机器学习方面去进行入门了,题主现在还只是一个小白,正在这条路上慢慢前行。废话不多说了,下面进入正题:
开始的理论解释的都是爬虫的用途和一些作用,这个对于学习爬虫就稍微了解一下就OK啦。
1. 书中对于爬虫的一些基本的原理和知识
实际上我们所用的搜索引擎就是一个爬虫架构,但是搜索引擎呈现给我们的东西是我们能够看到的,而且通过特定的算法来对用户所需要的东西进行呈现。
网络爬虫的组成:网络爬虫由控制节点,爬虫节点,资源库组成。
网络爬虫的类型: 通用网络爬虫,聚焦网络爬虫,增量式网络爬虫。
聚焦网络爬虫:也叫主题爬虫,是按照预先定义好的主题有选择性的进行网页抓取的一种爬虫,这种爬虫也就是我们平时所用的爬虫。
增量式爬虫:这种爬虫只爬取页面更新的地方,而未改变的地方则不更新。所以大多数时候都是新页面
深层网络爬虫:这种爬虫可以爬取深层页面。就是比较深层次的东西。
爬虫技能综总览图:
- 爬取多站新闻,集中阅读
- 爬取金融信息,进行投资分析
- 搜索引擎
- 爬取图片
- 爬取网站用户的公开信息,进行分析
- 爬取用户的联系方式,进行营销
- 自动去除网页广告
- 等等
对于上面的技能,我认为只有少数是我们可能会用到的。
接下来是爬虫根据网页更新的速度来制定相应的更新策略,有三种,主要是用户体验策略,历史数据策略,聚类分析策略
用户体验策略主要是:我们都知道百度搜索关键字进入的时候,都会出现数以万记的url地址,然而对于这些url,百度自身对于它是由一种筛选机制的,因为我们大多数用户都只是关注排名靠前的一些url,因此可以根据这些排名去进行一个抓取顺序的编排
历史数据策略呢,则是需要根据历史更新数据进行分析,从而对下一次更新做出预判,
聚类分析策略我认为是比较好的一种策略,首先这种策略不需要对历史数据进行分析,并且如果一个网站是新网站,则就没有相应的历史数据。我们可以根据聚类的原则,对url进行一种分类,然后对不同类别中进行抽样,检测更新频率,随后就可以对url的爬取频率进行相应的更改了
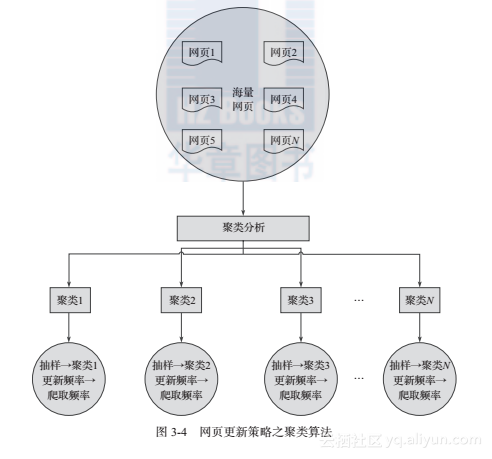
正如上图所示的吧。
当然能做爬虫的语言是非常多的,
- python:爬虫架构非常丰富,并且多线程处理能力较强,简单易学,代码简介,优点很多
- java:适合开发大型爬虫项目
- PHP:后端处理很强,代码很简洁,模块也丰富,但是并发能力较弱,
- C++:运行速度快,也是适合开发大型爬虫项目,但是成本较高















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









