






近年来,深度学习在人工智能领域取得了重大的突破。在计算机视觉、语音识别等诸多领域,深度神经网络(DNN, Deep Neural Network)均被证明是一种极具成效的问题解决方式。如卷积神经网络(CNN, Convolutional neural network)在计算机视觉诸多传统问题(分类、检测、分割)都超越了传统方法,循环神经网络(RNN, Recurrent Neural Networks)则在时序信号处理,如机器翻译,语音识别等超过传统方法。
在利用深度网络解决问题的时候人们常常倾向于设计更为复杂的网络收集更多的数据以期获得更高的性能。但是,随之而来的是模型的复杂度急剧提升,直观的表现是模型的层数越来越深,参数越来越多。这会给深度学习带来两个严重的问题:
- 随着模型参数的增多,模型的大小越来越大,给嵌入式端模型的存储带来了很大的挑战。
- 随着模型的增大,模型inference的时间越来越长,latency越来越大。
以上两个问题给深度学习在终端智能设备上的推广带来了很大的挑战。比如,经典的深度卷积网络VGG-16的模型大小达到528M,用户很难接受下载一个如此大的模型到手机或者其他终端设备上。同时,在一般的智能手机上,VGG-16识别一张图像的时间高达3000+ms,这个latency对于大多数用户来说也是难以接受的。此外,由于深度网络的计算量很大,运行深度网络的能耗很高,这对于手机等终端设备也是一个巨大的挑战。
基于低比特表示技术的神经网络压缩和加速算法
我有几张阿里云幸运券分享给你,用券购买或者升级阿里云相应产品会有特惠惊喜哦!把想要买的产品的幸运券都领走吧!快下手,马上就要抢光了。
在这个工作中,我们提出一种基于低比特表示技术的神经网络压缩和加速算法。我们将神经网络的权重表示成离散值,并且离散值的形式为2的幂次方的形式,比如{-4,-2,-1,0,1,2,4}。这样原始32比特的浮点型权重可以被压缩成1-3比特的整形权重,同时,原始的浮点数乘法操作可以被定点数的移位操作所替代。在现代处理器中,定点移位操作的速度和能耗是远远优于浮点数乘法操作的。
首先,我们将离散值权重的神经网络训练定义成一个离散约束优化问题。以三值网络为例,其目标函数可以表示为:
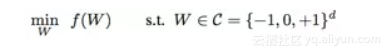
更进一步,我们在约束条件中引入一个scale参数。对于三值网络,我们将约束条件写成{-a, 0, a}, a>0. 这样做并不会增加计算代价,因为在卷积或者全连接层的计算过程中可以先和三值权重{-1, 0, 1}进行矩阵操作,然后对结果进行一个标量scale。从优化的角度看,增加这个scale参数可以大大增加约束空间的大小,这有利于算法的收敛。如下图所示,
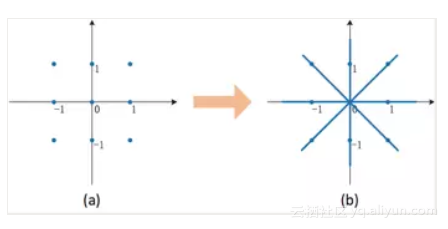
对于三值网络而言,scale参数可以将约束空间从离散的9个点扩增到4条直线。
为了求解上述约束优化问题,我们引入ADMM算法。在此之前,我们需要对目标函数的形式做一个等价变换。














 619
619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









