







tinyhttpd是一个超轻量型Http Server,使用C语言开发,全部代码只有502行(包括注释),附带一个简单的Client,可以通过阅读这段代码理解一个 Http Server 的本质。下载链接:http://sourceforge.net/projects/tinyhttpd/
分析这段源码前,需要对网络协议,Linux编程,以及HTTP有一定的了解,这里假设大家对http有一定的了解,如果有时间,会额外介绍下Http。
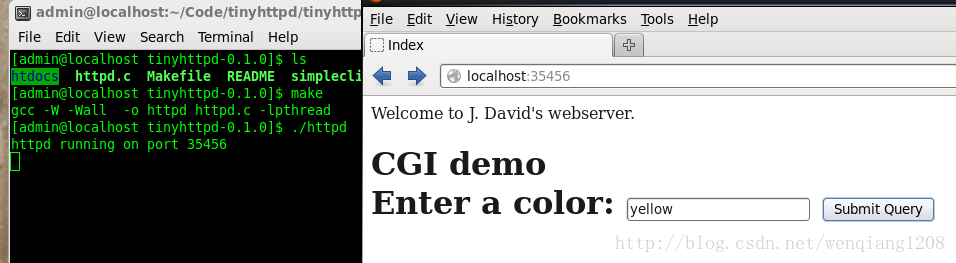
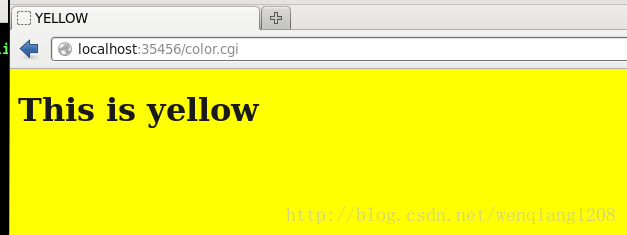
运行程序
这里,我先让代码跑起来,再分析源码
注:下载的源码不能直接在Linux下运行,需要改动一些小地方,因为现在Linux以及支持pthread,不需要再按照注释给出的修改方法。
修改1
33行改为 void* accept_request(void *); 相应的该函数的实现也要做出修改。
主要是为了适应pthread_create()函数参数。
void* accept_request(void *pclient)
{
int client = *(int*)pclient;
……
unimplemented(client);
return NULL;//r77
……
close(client);//r128
return NULL;//
} 修改2 438行和483行(源码436行和481行)的变量类型改为 socklen_t
修改3
(源码495行)改为
if (pthread_create(&newthread , NULL, accept_request,(void*)&client_sock) != 0)修改4
修改makefile,
gcc -W -Wall -o httpd httpd.c -lpthread修改5
如果上述修改后,不能运行,那就需要修改5了,
可能是htdocs文件下的index.html可能具有可执行权限了,
修改其权限,chmod 444 index.html
运行程序
分析源码
tinyhttpd总共包含以下函数:
int startup(u_short *);//开启http服务,包括绑定端口,监听,开启线程处理链接
void* accept_request(void *pclient) ;//处理从套接字上监听到的一个 HTTP 请求
void execute_cgi(int, const char *, const char *, const char *);//运行cgi脚本,这个非常重要,涉及动态解析
//前三个是主要函数,后面的都是辅助函数
void bad_request(int);//返回给客户端这是个错误请求,400响应码
void cat(int, FILE *);//读取服务器上某个文件写到 socket 套接字
void cannot_execute(int);//处理发生在执行 cgi 程序时出现的错误
void error_die(const char *);//把错误信息写到 perror
int get_line(int, char *, int);//读取一行HTTP报文
void headers(int, const char *);//返回HTTP响应头
void not_found(int);//返回找不到请求文件
void serve_file(int, const char *);//调用 cat 把服务器文件内容返回给浏览器。
void unimplemented(int);//返回给浏览器表明收到的 HTTP 请求所用的 method 不被支持。先把整体的思路理清楚,再分析源码。
工作流程:
1>服务器启动,在指定端口或随机选取端口绑定httpd服务。
2>收到一个http请求时(其实就是listen端口accept的时候),派生一个线程运行accept_request函数。
3>取出http请求中method(get或post)和url,对于get方法,如果有携带参数,则query_string指针指向url中?后面的get参数。
4>格式化url到path数组,表示浏览器请求的文件路径,在tinyhttpd中服务器文件是在htdocs文件夹下。当url以/结尾,或者url是个目录,则默认在path中加上index.thml,表示访问主页。
5>如果文件路径合法,对于无参数的get请求,直接输出服务器文件到浏览器,即用http格式写到套接字上,跳到(10)。其他情况(带参数get,post方法,url为科执行文件),则调用execute_cgi函数执行cgi脚本。
6>读取整个http请求并丢弃,如果是post则找出content-length,把http状态码200写到套接字里面。
7>建立两个管道,cgi_input和cgi_output,并fork一个子进程。
8>在子进程中,把stdout重定向到cgi_output的写入端,把stdin重定向到cgi_input的读取端,关闭cgi_input的写入端和cgi_output的读取端,是指request_method的环境变量,get的话设置query_string的环境变量,post的话设置content-length的环境变量,这些环境变量都是为了给cgi脚本调用,接着用execl运行cgi程序。
9>在父进程中,关闭cgi_input的读取端和cgi_output的写入端,如果post的话,把post数据写入到cgo_input,已被重定向到stdin读取cgi_output的管道输出到客户端,等待子进程结束。
10>关闭与浏览器的链接,完成一次http请求与回应,因为http是无连接的。
网上找的一张图,对比着看,
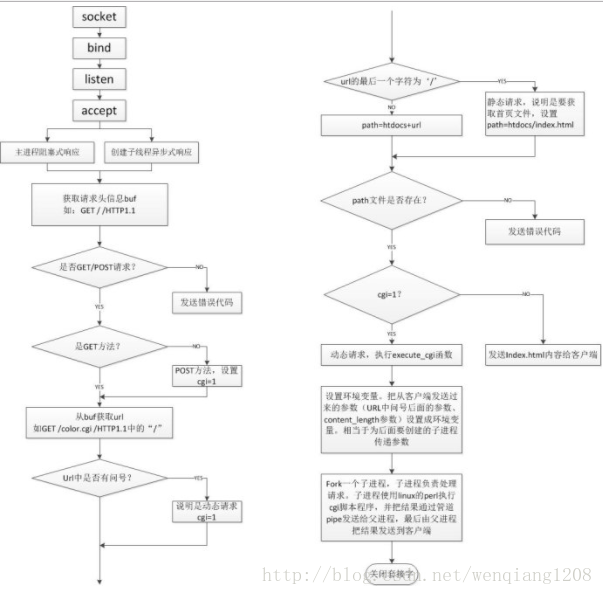
这样心中大概就有一个思路,接下来分下代码
建议源码阅读顺序:main —> startup —> accept_request —> excute_cgi
先介绍几个中间辅助函数:
从文件描述符sock中,读取一行信息:get_line
//读取一行http报文,以\r 或\r\n为行结束符
//注:只是把\r\n之前的内容读取到buf中,最后再加一个\n\0
int get_line(int sock, char *buf, int size)
{
int i = 0;
char c = '\0';
int n;
//读取到的字符个数大于size或者读到\n结束循环
while ((i < size - 1) && (c != '\n'))
{
n = recv(sock, &c, 1, 0); //接收一个字符
/* DEBUG printf("%02X\n", c); */
if (n > 0)
{
if (c == '\r')//回车字符
{
/*使用 MSG_PEEK 标志使下一次读取依然可以得到这次读取的内容,可认为接收窗口不滑动*/
n = recv(sock, &c, 1, MSG_PEEK);
/* DEBUG printf("%02X\n", c); */
//读取到回车换行
if ((n > 0) && (c == '\n'))
recv(sock, &c, 1, 0);//还需要读取,因为之前一次的读取,相当于没有读取
else
c = '\n';//如果只读取到\r,也要终止读取
}
//没有读取到\r,则把读取到内容放在buf中
buf[i] = c;
i++;
}
else
c = '\n';
}
buf[i] = '\0'
return(i);//返回读取到的字符个数,不包括\0
}请求出错处理函数 :
bad_requeset , cannot_execute ,error_dieerror_die, not_found
//告知客户端该请求有错误400
void bad_request(int client)
{
char buf[1024];
/*将字符串存入缓冲区,再通过send函数发送给客户端*/
sprintf(buf, "HTTP/1.0 400 BAD REQUEST\r\n");
send(client, buf, sizeof(buf), 0);
sprintf(buf, "Content-type: text/html\r\n");
send(client, buf, sizeof(buf), 0);
sprintf(buf, "\r\n");
send(client, buf, sizeof(buf), 0);
sprintf(buf, "<P>Your browser sent a bad request, ");
send(client, buf, sizeof(buf), 0);
sprintf(buf, "such as a POST without a Content-Length.\r\n");
send(client, buf, sizeof(buf), 0);
}
//告知客户端CGI脚本不能被执行,错误代码500
void cannot_execute(int client)
{
char buf[1024];
sprintf(buf, "HTTP/1.0 500 Internal Server Error\r\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "Content-type: text/html\r\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "\r\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "<P>Error prohibited CGI execution.\r\n");
send(client, buf, strlen(buf), 0);
}
//打印出错误信息并结束程序。
void error_die(const char *sc)
{
perror(sc);
exit(1);
}
/告知客户端404错误(没有找到)
void not_found(int client)
{
char buf[1024];
sprintf(buf, "HTTP/1.0 404 NOT FOUND\r\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, SERVER_STRING);
send(client, buf, strlen(buf), 0);
sprintf(buf, "Content-Type: text/html\r\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "\r\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "<HTML><TITLE>Not Found</TITLE>\r\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "<BODY><P>The server could not fulfill\r\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "your request because the resource specified\r\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "is unavailable or nonexistent.\r\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "</BODY></HTML>\r\n");
send(client, buf, strlen(buf), 0);
}
读取文件中数据发送到client:cat函数
//把文件resource中的数据读取到client中
void cat(int client, FILE *resource)
{
char buf[1024];
/从文件结构指针resource中读取数据,保存至buf中
fgets(buf, sizeof(buf), resource);
//处理文件流中剩下的字符
//检测流上的文件结束符,文件结束返回非0值,结束返回0
while (!feof(resource))
{
send(client, buf, strlen(buf), 0);
fgets(buf, sizeof(buf), resource);
}
}将信息传送个client:headers, serve_file
/服务器向client发送响应头部信息
void headers(int client, const char *filename)
{
char buf[1024];
(void)filename; /* could use filename to determine file type */
strcpy(buf, "HTTP/1.0 200 OK\r\n");
send(client, buf, strlen(buf), 0);
strcpy(buf, SERVER_STRING);
send(client, buf, strlen(buf), 0);
sprintf(buf, "Content-Type: text/html\r\n");
send(client, buf, strlen(buf), 0);
strcpy(buf, "\r\n");
send(client, buf, strlen(buf), 0);
}
//调用 cat 把服务器文件内容返回给浏览器
void serve_file(int client, const char *filename)
{
FILE *resource = NULL;
int numchars = 1;
char buf[1024];
//读取,丢弃头部
buf[0] = 'A'; buf[1] = '\0';
while ((numchars > 0) && strcmp("\n", buf)) /* read & discard headers */
numchars = get_line(client, buf, sizeof(buf));
resource = fopen(filename, "r");
if (resource == NULL)
not_found(client);//文件不存在,返回404错误
else
{
headers(client, filename);//服务器向client发送响应头部信息,200
cat(client, resource);//将文件中的信息发送到client
}
fclose(resource);
}tinyhttpd服务器端的核心函数
main函数
int main(void)
{
int server_sock = -1;
u_short port = 0; //监听端口号
int client_sock = -1;
struct sockaddr_in client_name;
socklen_t client_name_len = sizeof(client_name);
pthread_t newthread;
server_sock = startup(&port);//服务器端监听套接字设置
printf("httpd running on port %d\n", port);
/*多线程并发服务器模型*/
while (1)
{
//主线程 ,阻塞等待客户端连接请求
client_sock = accept(server_sock,
(struct sockaddr *)&client_name,
&client_name_len);
if (client_sock == -1)
error_die("accept");
//创建工作线程,执行回调函数accept_request,参数client_sock
if (pthread_create(&newthread , NULL, accept_request,(void *)&client_sock) != 0)
perror("pthread_create");
}
//关闭套接字,就协议栈而言,即关闭TCP连接
close(server_sock);
return(0);
}服务器端套接字初始化设置:start_up
/*服务器端套接字初始化设置*/
int startup(u_short *port)
{
int httpd = 0;
struct sockaddr_in name;
httpd = socket(PF_INET, SOCK_STREAM, 0);//创建服务器端套接字
if (httpd == -1)
error_die("socket");
memset(&name, 0, sizeof(name));
name.sin_family = AF_INET;//地址簇
name.sin_port = htons(*port);//指定端口
name.sin_addr.s_addr = htonl(INADDR_ANY);//通配地址
if (bind(httpd, (struct sockaddr *)&name, sizeof(name)) < 0)//绑定到指定地址和端口
error_die("bind");
if (*port == 0) /* if dynamically allocating a port *///动态分配一个端口
{
int namelen = sizeof(name);
/*在以端口号0调用bind后,getsockname用于返回由内核赋予的本地端口号*/
if (getsockname(httpd, (struct sockaddr *)&name, &namelen) == -1)
error_die("getsockname");
*port = ntohs(name.sin_port);//网络字节顺序转换为主机字节顺序,返回主机字节顺序表达的数
}
if (listen(httpd, 5) < 0)//服务器监听客户端请求。套接字排队的最大连接个数5
error_die("listen");
return(httpd);
} 接收客户端的请求报文:accept_request
该函数结合上面的图片看,更容易理解
/* HTTP协议规定,请求从客户端发出,最后服务器端响应该请求并返回。
* 这是目前HTTP协议的规定,服务器不支持主动响应,所以目前的HTTP
* 协议版本都是基于客户端请求,然后响应的这种模型。 */
/*accept_request函数解析客户端请求,判断是请求静态文件还是cgi代码
(通过请求类型以及参数来判定),如果是静态文件则将文件输出给前端,
如果是cgi则进入cgi处理函数*/
void* accept_request(void* pclient)
{
char buf[1024];
int numchars;
char method[255];
char url[255];
char path[512];
size_t i, j;
struct stat st;
int cgi = 0; /* becomes true if server decides this is a CGI
* program */
char *query_string = NULL;
int client = *(int*)pclient;
//获取一行HTTP请求报文
numchars = get_line(client, buf, sizeof(buf));
i = 0; j = 0;
//提取其中的方法post或get到method
while (!ISspace(buf[j]) && (i < sizeof(method) - 1))
{
method[i] = buf[j];
i++; j++;
}
method[i] = '\0';
//tinyhttpd只实现了get post 方法
if (strcasecmp(method, "GET") 0&& strcasecmp(method, "POST"))
{
unimplemented(client);
return NULL;
}
//cgi为标志位,1表示开启CGI解析(POST方法)
if (strcasecmp(method, "POST") == 0)
cgi = 1;
i = 0;
//跳过method后面的空白字符
while (ISspace(buf[j]) && (j < sizeof(buf)))
j++;
//获取url
while (!ISspace(buf[j]) && (i < sizeof(url) - 1) && (j < sizeof(buf)))
{
url[i] = buf[j];
i++; j++;
}
url[i] = '\0';
//如果是get方法,url可能带?参数
if (strcasecmp(method, "GET") == 0)
{
query_string = url;
while ((*query_string != '?') && (*query_string != '\0'))
query_string++;
if (*query_string == '?')
{
//带参数需要执行cgi,解析参数
cgi = 1;
*query_string = '\0';
query_string++;
}
}
//以上 将起始行 解析完毕
sprintf(path, "htdocs%s", url);
//如果path是一个目录,默认设置首页为index.html
if (path[strlen(path) - 1] == '/')
strcat(path, "index.html");
//函数定义: int stat(const char *file_name, struct stat *buf);
//函数说明: 通过文件名filename获取文件信息,并保存在buf所指的结构体stat中
//返回值: 执行成功则返回0,失败返回-1,错误代码存于errno(需要include <errno.h>)
if (stat(path, &st) == -1) {
//访问的网页不存在,则不断的读取剩余的请求头部信息,并丢弃
while ((numchars > 0) && strcmp("\n", buf)) /* read & discard headers */
numchars = get_line(client, buf, sizeof(buf));
not_found(client);
}
else
{
//访问你的网页存在则进行处理
//S_IFDIR 判断是否为目录
if ((st.st_mode & S_IFMT) == S_IFDIR)
strcat(path, "/index.html");
、
//S_IXUSR:文件所有者具有可执行权限,
//S_IXGRP:用户组具有可执行权限
if ((st.st_mode & S_IXUSR) ||
(st.st_mode & S_IXGRP) ||
(st.st_mode & S_IXOTH) )
cgi = 1;
if (!cgi)
//将静态文件返回
serve_file(client, path);
else
execute_cgi(client, path, method, query_string);
}
//THHP协议是面向无连接的,所以要关闭
close(client);
return NULL;
}执行CGI脚本,动态页面申请:execute_cgi
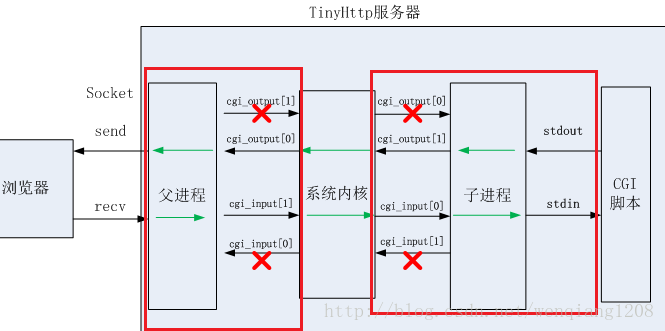
GET 方法用来请求访问已被 URI 识别的资源。指定的资源进服务器端解析后返回响应内容。换言之,如果请求的资源是文本(静态页面请求),那就保持原样返回;如果是像CGI 那样的程序(动态页面请求),则返回经过执行后的输出结果。
结合程序工作流程看以下代码,更容易理解
/*execute_cgi函数负责将请求传递给cgi程序处理,
服务器与cgi之间通过管道pipe通信,首先初始化两个管道,并创建子进程去执行cgi函数
子进程执行cgi程序,获取cgi的标准输出通过管道传给父进程,由父进程发送给客户端
*/
//参数path指向执行的CGI脚本路径 ,method指向http的请求方法
void execute_cgi(int client, const char *path,
const char *method, const char *query_string)
{
char buf[1024];
int cgi_output[2];
int cgi_input[2];
//cgi_out 是指CGI脚本输出数据的管道
//cgi_input是指向CGI脚本输入数据的管道
pid_t pid;
int status;
int i;
char c;
int numchars = 1;
int content_length = -1;
buf[0] = 'A'; buf[1] = '\0';
//如果是get请求,读取并丢弃头部
if (strcasecmp(method, "GET") == 0)//
while ((numchars > 0) && strcmp("\n", buf)) /* read & discard headers */
numchars = get_line(client, buf, sizeof(buf));
else /* POST */
{
//如果是post请求
numchars = get_line(client, buf, sizeof(buf));
while ((numchars > 0) && strcmp("\n", buf))
{
buf[15] = '\0';
//读取头信息找到Content-Length字段的值
if (strcasecmp(buf, "Content-Length:") == 0)
//Content-Length:15
content_length = atoi(&(buf[16]));
numchars = get_line(client, buf, sizeof(buf));
}
if (content_length == -1) {
bad_request(client);
return;
}
}
//正确返回200
sprintf(buf, "HTTP/1.0 200 OK\r\n");
send(client, buf, strlen(buf), 0);
//pipe(int filep[2]) 管道函数,f[0]读,f[1]写
//必须在fork()中调用pipe(),否则子进程不会继承文件描述符。
//两个进程必须有血缘关系才能使用pipe。但是可以使用命名管道。
if (pipe(cgi_output) < 0) {
cannot_execute(client);
return;
}
if (pipe(cgi_input) < 0) {
cannot_execute(client);
return;
}
if ( (pid = fork()) < 0 ) {
cannot_execute(client);
return;
}
/*子进程继承了父进程的pipe,然后通过关闭子进程output管道的输出端,input管道的写入端;
关闭父进程output管道的写入端,input管道的输出端*/
if (pid == 0) /* child: CGI script */
{
char meth_env[255];
char query_env[255];
char length_env[255];
//把stdout 重定向到cgi_output[1]
dup2(cgi_output[1], 1);
dup2(cgi_input[0], 0);
close(cgi_output[0]);//关闭cgi_output读端
close(cgi_input[1]); //关闭cgi_input 写端
sprintf(meth_env, "REQUEST_METHOD=%s", method);
putenv(meth_env);
if (strcasecmp(method, "GET") == 0) {
/*设置 query_string 的环境变量*/
sprintf(query_env, "QUERY_STRING=%s", query_string);
putenv(query_env);
}
else { /* POST */
/*设置 content_length 的环境变量*/
sprintf(length_env, "CONTENT_LENGTH=%d", content_length);
putenv(length_env);
}
//exec函数簇,执行CGI脚本,获取cgi的标准输出作为相应内容发送给客户端
execl(path, path, NULL);
exit(0);
}
else
{ /* parent */
close(cgi_output[1]);
close(cgi_input[0]);
/*通过关闭对应管道的通道,然后重定向子进程的管道某端,这样就在父子进程之间构建一条单双工通道
如果不重定向,将是一条典型的全双工管道通信机制
*/
if (strcasecmp(method, "POST") == 0)
for (i = 0; i < content_length; i++) {
recv(client, &c, 1, 0);//从客户端接收单个字符
write(cgi_input[1], &c, 1);
//数据传送过程:input[1](父进程) ——> input[0](子进程)[执行cgi函数] ——> STDIN ——> STDOUT
// ——> output[1](子进程) ——> output[0](父进程)[将结果发送给客户端]
}
while (read(cgi_output[0], &c, 1) > 0)//读取output的管道输出到客户端,output输出端为cgi脚本执行后的内容
send(client, &c, 1, 0);//即将cgi执行结果发送给客户端,即send到浏览器,如果不是POST则只有这一处理
close(cgi_output[0]);//关闭剩下的管道端,子进程在执行dup2之后,就已经关闭了管道一端通道
close(cgi_input[1]);
waitpid(pid, &status, 0);//等待子进程终止
}
}整体代码在GitHub上面:
https://github.com/WenQiangW/TinyHttpd
如果错误,欢迎指出,交流进步,谢谢














 922
922











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









