







 本文介绍了TinyHttpd,一个仅有502行的轻量级C语言HTTP服务器,详细讲解了如何运行程序以及源码分析。主要内容包括服务器启动、工作流程、CGI脚本执行等,适合对网络协议和Linux编程有一定了解的读者。源码阅读顺序建议为:main -> startup -> accept_request -> execute_cgi。文章提供了修改源码以适应现代Linux环境的方法,并给出了代码仓库链接。
本文介绍了TinyHttpd,一个仅有502行的轻量级C语言HTTP服务器,详细讲解了如何运行程序以及源码分析。主要内容包括服务器启动、工作流程、CGI脚本执行等,适合对网络协议和Linux编程有一定了解的读者。源码阅读顺序建议为:main -> startup -> accept_request -> execute_cgi。文章提供了修改源码以适应现代Linux环境的方法,并给出了代码仓库链接。
tinyhttpd是一个超轻量型Http Server,使用C语言开发,全部代码只有502行(包括注释),附带一个简单的Client,可以通过阅读这段代码理解一个 Http Server 的本质。下载链接:http://sourceforge.net/projects/tinyhttpd/
分析这段源码前,需要对网络协议,Linux编程,以及HTTP有一定的了解,这里假设大家对http有一定的了解,如果有时间,会额外介绍下Http。
运行程序
这里,我先让代码跑起来,再分析源码
注:下载的源码不能直接在Linux下运行,需要改动一些小地方,因为现在Linux以及支持pthread,不需要再按照注释给出的修改方法。
修改1
33行改为 void* accept_request(void *); 相应的该函数的实现也要做出修改。
主要是为了适应pthread_create()函数参数。
void* accept_request(void *pclient)
{
int client = *(int*)pclient;
……
unimplemented(client);
return NULL;//r77
……
close(client);//r128
return NULL;//
} 修改2 438行和483行(源码436行和481行)的变量类型改为 socklen_t
修改3
(源码495行)改为
if (pthread_create(&newthread , NULL, accept_request,(void*)&client_sock) != 0)修改4
修改makefile,
gcc -W -Wall -o httpd httpd.c -lpthread修改5
如果上述修改后,不能运行,那就需要修改5了,
可能是htdocs文件下的index.html可能具有可执行权限了,
修改其权限,chmod 444 index.html
运行程序
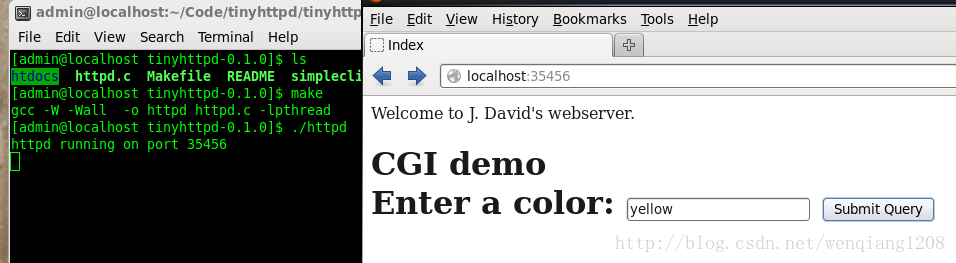
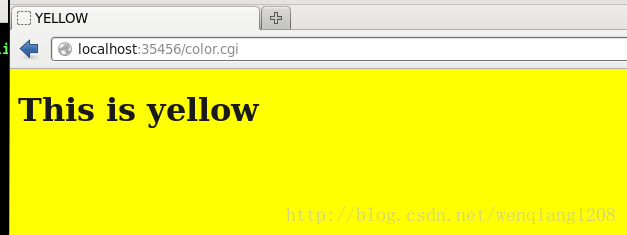
分析源码
tinyhttpd总共包含以下函数:
int startup(u_short *);//开启http服务,包括绑定端口,监听,开启线程处理链接
void* accept_request(void *pclient) ;//处理从套接字上监听到的一个 HTTP 请求
void execute_cgi(int, const char *, const char *, const char *);//运行cgi脚本,这个非常重要,涉及动态解析
//前三个是主要函数,后面的都是辅助函数
void bad_request(int);//返回给客户端这是个错误请求,400响应码
void cat(int, FILE *);//读取服务器上某个文件写到 socket 套接字
void cannot_execute(int);//处理发生在执行 cgi 程序时出现的错误
void error_die(const char *);//把错误信息写到 perror
int get_line(int, char *, int);//读取一行HTTP报文
void headers(int, const char *);//返回HTTP响应头
void not_found(int);//返回找不到请求文件
void serve_file(int, const char *);//调用 cat 把服务器文件内容返回给浏览器。
void unimplemented(int);//返回给浏览器表明收到的 HTTP 请求所用的 method 不被支持。先把整体的思路理清楚,再分析源码。
工作流程:
1>服务器启动,在指定端口或随机选取端口绑定httpd服务。
2>收到一个http请求时(其实就是listen端口accept的时候),派生一个线程运行accept_request函数。
3>取出http请求中method(get或post)和url,对于get方法,如果有携带参数,则query_string指针指向url中?后面的get参数。
4>格式化url到path数组,表示浏览器请求的文件路径,在tinyhttpd中服务器文件是在htdocs文件夹下。当url以/结尾,或者url是个目录,则默认在path中加上index.thml,表示访问主页。
5>如果文件路径合法,对于无参数的get请求,直接输出服务器文件到浏览器,即用http格式写到套接字上,跳到(10)。其他情况(带参数get,post方法,url为科执行文件),则调用execute_cgi函数执行cgi脚本。
6>读取整个http请求并丢弃,如果是post则找出content-length,把http状态码200写到套接字里面。
7>建立两个管道,cgi_input和cgi_output,并fork一个子进程。
8>在子进程中,把stdout重定向到cgi_output的写入端,把stdin重定向到cgi_input的读取端,关闭cgi_input的写入端和cgi_output的读取端,是指request_method的环境变量,get的话设置query_string的环境变量,post的话设置content-length的环境变量,这些环境变量都是为了给cgi脚本调用,接着用execl运行cgi程序。
9>在父进程中,关闭cgi_input的读取端和cgi_output的写入端,如果post的话,把post数据写入到cgo_input,已被重定向到stdin读取cgi_output的管道输出到客户端,等待子进程结束。
10>关闭与浏览器的链接,完成一次http请求与回应,因为http是无连接的。
网上找的一张图,对比着看,
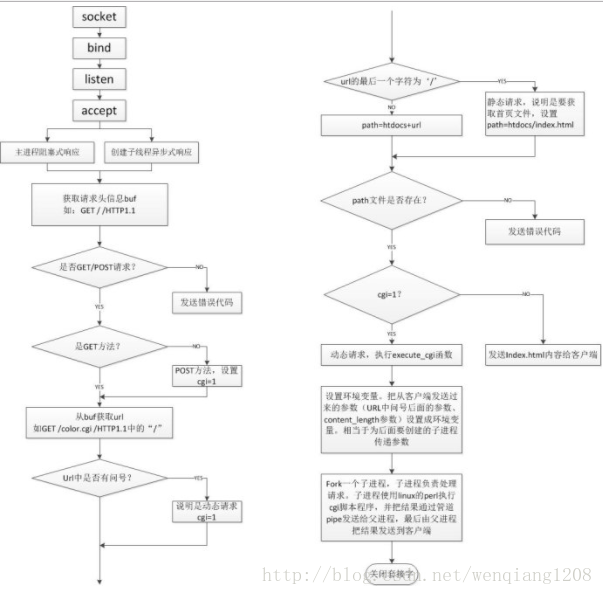
这样心中大概就有一个思路,接下来分下代码
建议源码阅读顺序:main —> startup —> accept_request —> excute_cgi
先介绍几个中间辅助函数:
从文件描述符sock中,读取一行信息:get_line
//读取一行http报文,以\r 或\r\n为行结束符
//注:只是把\r\n之前的内容读取到buf中,最后再加一个\n\0
int get_line(int sock, char *buf, int size)
{
int i = 0;
char c =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









