







转载自 http://blog.csdn.net/lastsweetop/article/details/9162031
文件压缩主要有两个好处,一是减少了存储文件所占空间,另一个就是为数据传输提速。在hadoop大数据的背景下,这两点尤为重要,那么我现在就先来了解下hadoop中的文件压缩。
hadoop里支持很多种压缩格式,我们看一个表格:
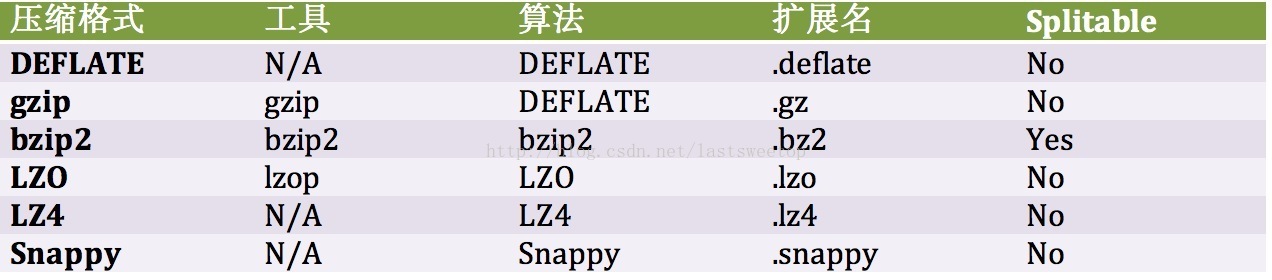
DEFLATE是同时使用了LZ77算法与哈夫曼编码(Huffman Coding)的一个无损数据压缩算法,源代码可以在zlib库中找到。gzip是以DEFLATE算法为基础扩展出来的一种算法。
所有的压缩算法都是空间和时间的转换,更快压缩时间还是更小的压缩比,可以通过参数来指定,-1意味着速度,-9意味着空间。拿gzip做个例子,下面就意味着更快速的压缩:
- gzip -1 file
splittable表示压缩格式是否可以被分割,也就是说是否支持随即读。压缩数据是否能被mapreduce使用,压缩数据是否能被分割就很关键了。
举个例子,一个未压缩的文件有1GB大小,hdfs默认的block大小是64MB,那么这个文件就会被分为16个block作为mapreduce的输入,每一个单独使用一个map任务。如果这个文件是已经使用gzip压缩的呢,如果分成16个块,每个块做成一个输入,显然是不合适的,因为gzip压缩流的随即读是不可能的。实际上,当mapreduce处理压缩格式的文件的时候它会认识到这是一个gzip的压缩文件,而gzip又不支持随即读,它就会把16个块分给一个map去处理,这里就会有很多非本地处理的map任务,整个过程耗费的时间就会相当长。
lzo压缩格式也会是同样的问题,但是通过使用hadoop lzo库的索引工具以后,lzo就可以支持splittable。bzip2也是支持splittable的。
那么如何选择压缩格式呢?这取决于文件的大小,你使用的压缩工具,下面是几条选择建议,效率由高到低排序:
1.用一些包含了压缩并且支持splittable的文件格式,比如Sequence File,RCFile或者Avro文件,这些文件格式我们之后都会讲到。如果为了快速压缩可以使用lzo,lz4或者snappy压缩格式。
2.使用提供splittable的压缩格式,比如,bzip2和索引后可以支持splittable的lzo。
3.提前把文件分成几个块,每个块单独压缩,这样就无需考虑splittable的问题了
4.不要压缩文件
以不支持splittable的压缩格式存储一个很大的数据文件是不合适的,非本地处理效率会非常之低。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









