







1. 压缩成为必须
对数据的3个关键特征描述 3V:volume、variety和value。
volume,数据量与日俱增,在于智能手机、Internet和感知器等的使用。
variety,大数据的数据格式,音频、视频、图像等。
value,数据近乎实时的产生以使得有用信息能够服务需要。
大数据不仅仅带来了新的数据类型和存储机制,也带来了新种类的数据分析。现在数据增长太快了,数据的处理和管理成为一种挑战,传统的数据存储和分析是低效的。在传统数据和大数据之间存在不同,大数据面临的挑战包括数据的隐私和安全、数据存储、从大数据中创造商业价值等。
伴随大数据的增长,压缩成为必然。压缩的优势在于:
压缩的数据使用较少的带宽。
压缩的数据使用较少的磁盘。
加速数据在磁盘和网络上的传输。
降低成本。
2. hadoop中的压缩类型
大数据包含复杂的、非结构化的数据,因此数据压缩很重要,codec表示数据压缩和解压缩算法的实现。一些压缩格式是可分割的,这样的压缩对大文件在性能上是较好的。hadoop支持的一般压缩算法如下:
LZO
Gzip
Bzip2
LZ4
Snappy
2.1 LZO
压缩格式由大量小块压缩数据组成,块大小对压缩和解压数据是一样的。它的压缩和解压缩速度是很快的而且是可分割的,LZO是一个用ANSI C编写的很少丢失数据的压缩库。它的源码和压缩数据格式使得它在平台之间迁移是非常便携的。LZO的特征如下:
数据压缩类似于其他普遍的压缩技术,比如gzip、bzip
能够非常快速的解压缩
除去源和目的buffer外,解压缩不需要额外的内存
对产生的预压缩数据有多种压缩level,因此带来了有竞争力的压缩比
还有一种压缩level仅仅为8KB数据压缩
算法是线程安全的
算法是数据无损的
LZO是便携的
Lzop是使用LZO作为压缩服务的文件压缩器,它是最快的压缩和加压缩器。
2.2 GZIP
GUN zip,基于DEFLATE算法,LZ77和Huffman编码的结合。它比LZO压缩性能好但是慢。如果原生hadoop lib在CLASSPATH中不可用,那么java将使用java自身的GZIP。
它在文件中寻找相似的字符串,临时的替换这些字符串以使得文件变小,第二个字符串用前一个字符串的指针替换,形为(distance,length)。文本和匹配长度以Huffman树压缩,而匹配距离以另一棵树压缩,这些树在每一块的块首以紧凑的格式存储。
deflate是压缩算法而inflate是解压缩算法,Gzip文件的后缀为.gz,各种可用的格式如下:
tar
shar
zip
tar.gz
tar.z
2.3 Bzip2
一种自由、可用的、高质量数据压缩器。压缩率一般在10%~15%,压缩的数据块大小在100~900KB。Bzip2的性能是不对称的,解压快。它支持存储媒介错误有限恢复,如果你试图从备份的磁带或者磁盘中修复数据且数据存在错误,bzip2依然能够解压文件的这些部分如果硬件没有收到损害。它也是便携的,以块来压缩大文件,块的大小影响压缩率和压缩、解压缩需要的内存。
2.4 LZ4
无丢失数据的压缩算法,强调压缩解压缩速度,压缩速度为每core 400MB/S~GB/s
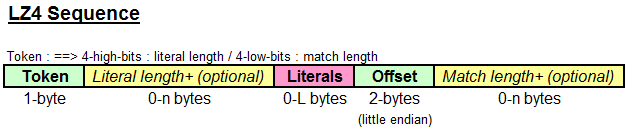
Token为1字节的值,Field为Literal长度,其值为0 则没有后面的Literal,其值为15则更多地Byte被添加,每一额外字段代表0~255之间的一个数字以计算总长。Literals为未压缩的文本,Offset代表匹配副本的位置,1 意味着当前位置-1 字段,最大值为65535 。
2.5 Snappy
非常高速、合理的压缩器。
3 总结
gzip是普通的压缩器,bzip压缩性能好于gzip但速度慢,LZO由很多小块组成。
LZO和Snappy的压缩速度好但压缩效率低,解压是gzip的两倍。Snappy解压缩好于LZO
| Compresssion format | Tool | Algorithm | File extention | Splitable |
| Gzip | gzip | DEFLATE | .gz | No |
| bzip2 | bzip2 | bzip2 | .bz2 | Yes |
| LZO | lzop | LZO | .lzo | Yes if indexed |
| Snappy | N/A | Snappy | .snappy | No |















 287
287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









