









进入lab1,使用git下载lab文件。然后略过Introduction,从Part 1开始看。本文参考自JasonLeaster,在此感谢他!
Part 1:PC Bootstrap
按照介绍一步一步来,make qemu后会出现 QEMU window。(记得先安装qemu)。
若此处使用make qemu-nox,则不会跳出QEMU 窗口,只在你的终端里显示。
1、这里牵扯到8086的一些基本知识。
1)
8086地址总线(AB)有20位,也即寻址空间 2^20 B = 1MB, 从0x00000 到 0xFFFFF 。
8086数据总线(DB)只有16位。
2)
那么如何用16位寻址20位空间呢?就是分段寻址。即segment:offset,计算结果:(segment << 4) + offset
8086在为程序分配内存空间的时候,将其分成 代码段CS,数据段DS,堆栈段SS和附加段ES,这些信息都存储在一些寄存器上(16位),如下图。
通用寄存器:
AX,BX,CX,DX 称作为数据寄存器:
AX (Accumulator):累加寄存器,也称之为累加器;
BX (Base):基地址寄存器;
CX (Count):计数器寄存器;
DX (Data):数据寄存器;
SP 和 BP 又称作为指针寄存器:
SP (Stack Pointer):堆栈指针寄存器;
BP (Base Pointer):基指针寄存器;
SI 和 DI 又称作为变址寄存器:
SI (Source Index):源变址寄存器;
DI (Destination Index):目的变址寄存器;
控制寄存器:
IP (Instruction Pointer):指令指针寄存器;
FLAG:标志寄存器;
段寄存器:
CS (Code Segment):代码段寄存器;
DS (Data Segment):数据段寄存器;
SS (Stack Segment):堆栈段寄存器;
ES (Extra Segment):附加段寄存器;
更详细的介绍参见:
8086寄存器:小宝马的爸爸
x86寄存器:http://www.eecg.toronto.edu/~amza/www.mindsec.com/files/x86regs.html
2、8086上电过程(实模式):
每次按下电源键,CPU都会复位, 一切从新开始。而对于8086来说,复位后,所有寄存器的值都是0,除了CS = 0xFFFF。
于是进行段寻址,
CS:IP = 0xFFFF0
于是计算机就开始启动啦~ 每次都从0xFFFF0开始。CS = 0xFFFF IP = 0x0000的时候 CPU在自己初始化,CPU初始化完成之后,系统马上进入实模式,CS变成 0xF000 IP=0xFFF0(此处一个疑惑,系统的第一条指令地址为0xffff0,但不知道是由上电后的[ffff:0000]还是之后的初始化的[f000:fff0]得到的,不过看下图感觉应该是后者)
如下图
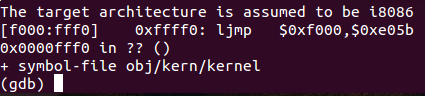
From this output you can conclude a few things:
The IBM PC starts executing at physical address 0x000ffff0, which is at the very top of the 64KB area reserved for the ROM BIOS.
The PC starts executing with CS = 0xf000 and IP = 0xfff0.
The first instruction to be executed is a jmp instruction, which jumps to the segmented address CS = 0xf000 and IP = 0xe05b.
关于虚拟地址,线性地址,物理地址的详细探讨参见JasonLeaster
如果看不懂,可看这篇: 我理解的逻辑地址、线性地址、物理地址和虚拟地址
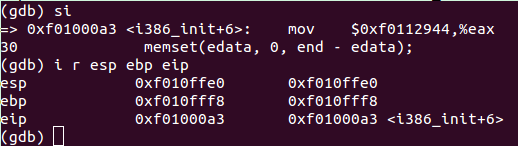
3、熟悉gdb的si指令
进入gdb环节后,si指令类似于C代码里的s指令。我们可以通过“i r”指令查看各寄存器值,通过x指令查看内存。如下图:
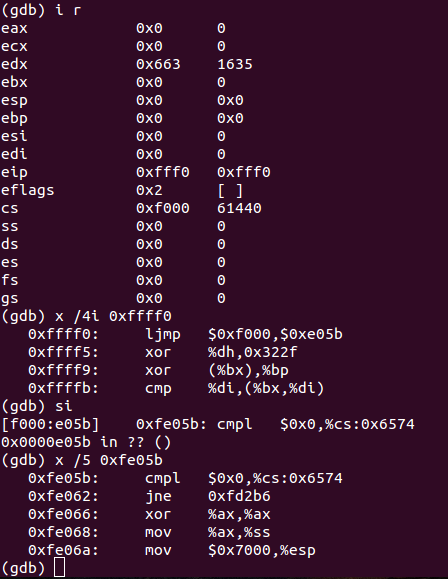
还可以用“i r ax”查看指定的寄存器。关于x指令的用法,可以参考http://m.oschina.net/blog/33839,按照其指令格式操作。
Part 2: The Boot Loader
首先提出了扇区(sector)概念:
Floppy(软盘) and hard disks for PCs are divided into 512 byte regions called sectors. A sector is the disk's minimum transfer granularity: each read or write operation must be one or more sectors in size and aligned on a sector boundary. If the disk is bootable, the first sector is called the boot sector, since this is where the boot loader code resides.When the BIOS finds a bootable floppy or hard disk, it loads the 512-byte boot sector into memory at physical addresses 0x7c00 through 0x7dff, and then uses a jmp instruction to set the CS:IP to 0000:7c00, passing control to the boot loader.Like the BIOS load address, these addresses are fairly arbitrary - but they are fixed and standardized for PCs.
The ability to boot from a CD-ROM came much later during the evolution of the PC, and as a result the PC architects took the opportunity to rethink the boot process slightly. As a result, the way a modern BIOS boots from a CD-ROM is a bit more complicated (and more powerful). CD-ROMs use a sector size of 2048 bytes instead of 512, and the BIOS can load a much larger boot image from the disk into memory (not just one sector) before transferring control to it.
在我们的课程中,采用的是传统的512byte扇区。
boot/文件夹里有相关代码。
首先是boot.S,汇编代码,真是要哭了。。慢慢啃吧
boot.S中的汇编代码,是进行实模式进入保护模式的转换。
相关参考可见:
http://blog.csdn.net/misskissc/article/details/16349249
http://www.cnblogs.com/MSRA_SE_TEAM/archive/2010/11/29/1891270.html
知道个大概,可细节很多还不明白,留着以后在细看。
接着是main.c函数:真要哭了。。
Bootmain函数位于boot/main.c中,执行从硬盘扇区读取内核的操作。
用gdb查看代码执行过程如下:
boot代码从0x7c00开始执行。
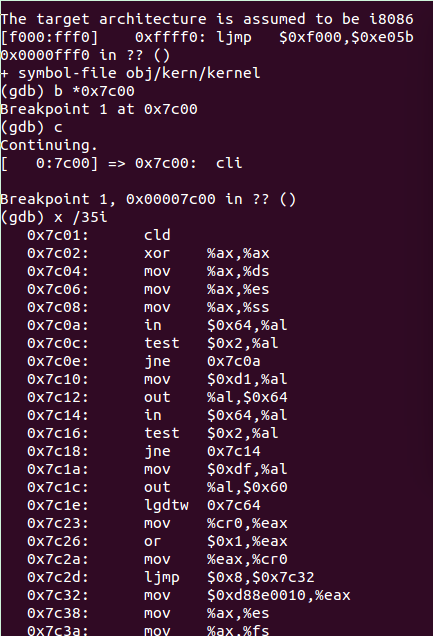
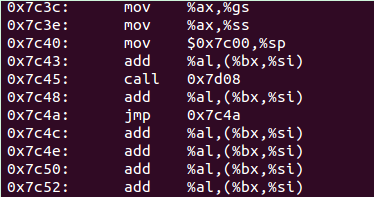
代码当前执行在16bit i8086模式下,在执行完0x7c2d这行代码后,进入32bit i386保护模式 。
/boot/main.c以及/obj/boot.asm里面的代码目前是真的看不下去了。。留个坑以后看
现在尝试解决4个小问题:
1)At what point does the processor start executing 32-bit code? What exactly causes the switch from 16- to 32-bit mode?
程序在boot.S 里55执行一个跳转,进入32bit保护模式。

对应的gdb瞬间如下:
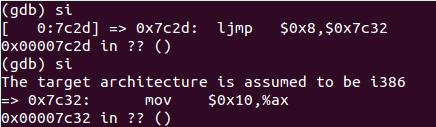
2)What is the last instruction of the boot loader executed, and what is the first instruction of the kernel it just loaded?
/boot/main.c 里,下图为boot loader里执行的最后一条指令。

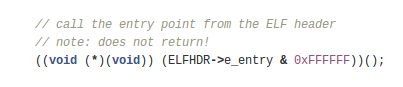
关键字ELFHDR -> e_entry,其中ELFHDR是指向0x10000(被强制类型转换成struct Elf*)的指针。
这里通过readseg()函数使得ELFHDR得以初始化。这个初始化的数据来源就是硬盘上的内核镜像。

于是我们从那里去找这个ELFHDR->e_entry指向的位置呢?反汇编kernel镜像!
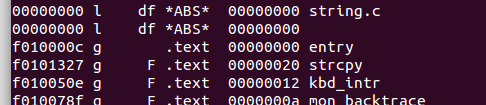
objdump -x ./obj/kern/kernel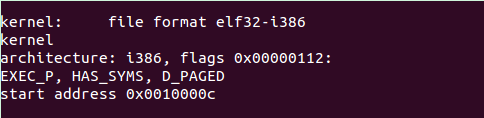
可见起始位置是0x10000c,设定断点运行到此处:
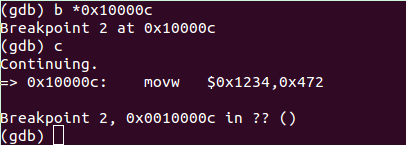
得到进入内核后的第一条指令。
因为跳转到JOS内核后,执行的第一个文件是kern/entry.S,我们能够在 kern/entry.S中得到印证,能够找到这句代码:
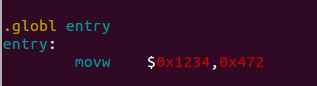
而kernel镜像中的entry 符号就是指向entry.S 这个文件的代码起始地址的
反汇编你会看到一个entry的符号!value是0xf010000c 这就是我们镜像上内核的入口地址了,和上面的0x10000c并不冲突,前者0x10000c是后者0xF010000C转换而来的 。
这种转换一开始是手动的,对比09\10年同样的代码(左)与14年的代码:

发现这里是有手动的&转换的,而2014年的代码是没有这种强制转换的。
Operating system kernels often like to be linked and run at very high virtual address, such as 0xf0100000, in order to leave the lower part of the processor's virtual address space for user programs to use. The reason for this arrangement will become clearer in the lab 2.
Many machines don't have any physical memory at address 0xf0100000, so we can't count on being able to store the kernel there. Instead, we will use the processor's memory management hardware to map virtual address 0xf0100000 (the link address at which the kernel code expects to run) to physical address 0x00100000 (where the boot loader loaded the kernel into physical memory). This way, although the kernel's virtual address is high enough to leave plenty of address space for user processes, it will be loaded in physical memory at the 1MB point in the PC's RAM, just above the BIOS ROM. This approach requires that the PC have at least a few megabytes of physical memory (so that physical address 0x00100000 works), but this is likely to be true of any PC built after about 1990.
因为硬件已经把0xf0100000 映射到0x100000 ,同理将0xf010000c映射到0x10000c,实质上就是手动转换变成硬件直接转换。
我们可以通过反汇编的结果看出,如下:
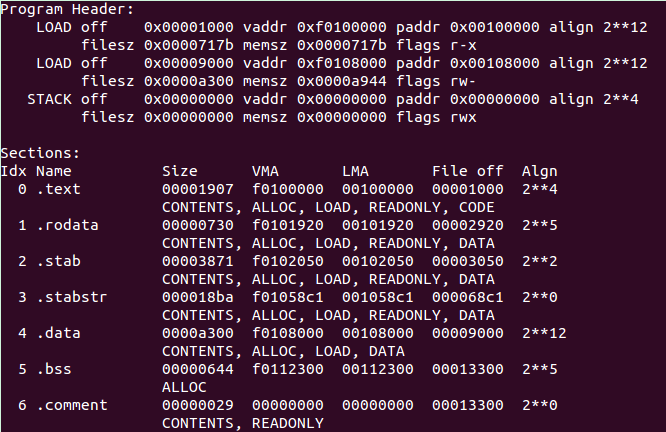
其中的VMA表示的是virtual memory address,而LMA是指load memory address。
更早的,从启动信息我们也可以知道这点:
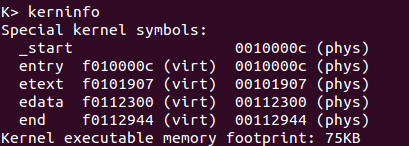
3)Where is the first instruction of the kernel?
从上面的分析已知kernel的第一条指令的物理地址为0x10000c。
4)How does the boot loader decide how many sectors it must read in order to fetch the entire kernel from disk? Where does it find this information?
根据elf格式文件储存的信息确定并读取,见上上图的ELF Header。
Exercise 4.
阅读point.c里面的代码,要能看懂。
lab1的比较后面的地方有提示如下:
Here are a few specific points you read about in K&R Chapter 5 that are worth remembering for the following exercise and for future labs.
1)If int *p = (int*)100, then (int)p + 1 and (int)(p + 1) are different numbers: the first is 101 but the second is 104. When adding an integer to a pointer, as in the second case, the integer is implicitly multiplied by the size of the object the pointer points to.
2)p[i] is defined to be the same as *(p+i), referring to the i'th object in the memory pointed to by p. The above rule for addition helps this definition work when the objects are larger than one byte.
3)&p[i] is the same as (p+i), yielding the address of the i'th object in the memory pointed to by p.
主要有两点需要主要(当时自己的总结):
1)当c为数组名时,3[c] = c[3],因为两者其实都是指 *(3+c), 不过这种表示方法还真是拉风啊。。
2)
c = (int *) ((char *) c + 1);
*c = 500;这句话会影响a[1]和a[2]的值。
开始a[1]、a[2]数据为(用二进制表示):
00000000000000000000000110010000 00000000000000000000000100101101
本以为会变成:
00000000000000000000000000000001 11110100000000000000000100101101
结果却是:
00000000000000011111010010010000 00000000000000000000000100000000
不能理解啊。找灵哥探讨了下,原来是存储顺序的原因。
易知数组的存储是从低地址向高地址存。低——>高,同理,int的4个字节是低位存在低地址,高位存在高地址,存储的基本单位是字节。(字节内我们这里认为是便于理解的左高右低存储方式)
开始:
| Add | 0xbfffe5f4 | 0xbfffe5f5 | 0xbfffe5f6 | 0xbfffe5f7 |
| a[1] | 0x90 | 0x01 | 0x00 | 0x00 |
| Add | 0xbfffe5f8 | 0xbfffe5f9 | 0xbfffe5fa | 0xbfffe5fb |
| a[2] | 0x2d | 0x01 | 0x00 | 0x00 |
| Add | 0xbfffe5f4 | 0xbfffe5f5 | 0xbfffe5f6 | 0xbfffe5f7 |
| a[1] | 0x90 | 0xf4 | 0x01 | 0x00 |
| Add | 0xbfffe5f8 | 0xbfffe5f9 | 0xbfffe5fa | 0xbfffe5fb |
| a[2] | 0x00 | 0x01 | 0x00 | 0x00 |

我修改了 boot/Makefrag 里面link address,将 0x7c00 改为 0x7c01,重新运行出错,如果就在0x7c01设置断点,那么会卡在读取boot sector那部分,qemu界面就不断得闪啊闪,不断读取boot sector。如果将断点设在0x7c00,程序虽然能够继续执行,但是执行的是错误的代码,后来也陷入无限的循环里面。

我们知道boot loader的地址是0x7c00,而kernel的地址为0x10000c。
gdb内容如下:
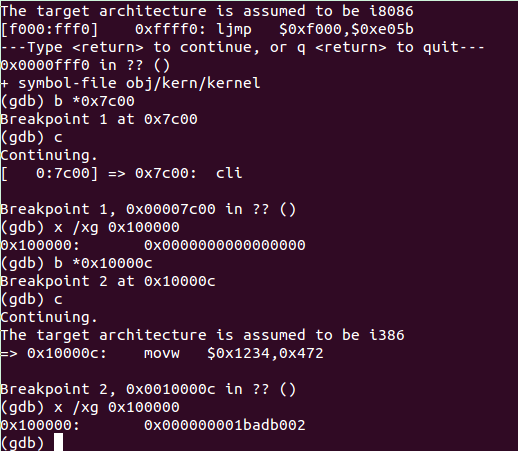
对比可以看出,执行到0x7c00时,0x100000里面存的全是0,而执行到0x10000c时,里面有数据了,不过看不懂。。
暂且认为是汇编指令,对比下obj/kernel/kernel.asm
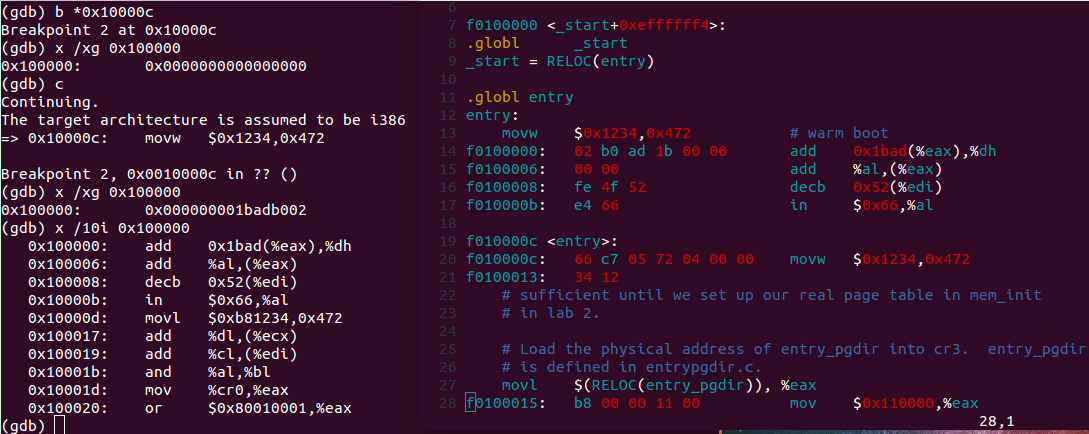
验证了内核代码从0x100000开始,和链接脚本 kern/kernel.ld描述的一致。注意内核代码执行的第一条指令是在0x10000c处,暂不清楚之前存储的是什么,有什么用。
Part 3: The Kernel

调试结果如下:
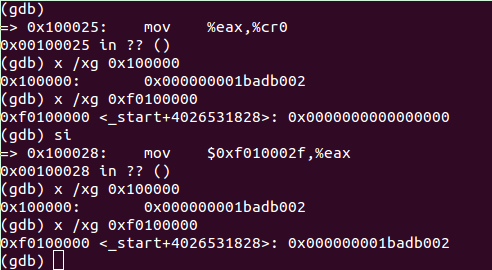
在这条指令之前,两个地址的内容是不一样的,之后就变成一样。原因就是之前还没有建立分页机制,高地址内核区域还没有映射到内核的物理地址,而只有低地址有效的。开启分页之后,在静态映射表的作用下(kern/enterpgdir.c),两块虚拟地址都指向同一块物理地址区域。

图中的 mov $relocated, %eax 是打开分页之后的第一条指令。可见虽然右图显示指令执行地址为高地址0xf0100028,但实际执行地址为低地址0x00100028 。
Read through kern/printf.c, lib/printfmt.c, and kern/console.c, and make sure you understand their relationship. It will become clear in later labs why printfmt.c is located in the separate lib directory.
首先遇到的问题是关于va_start(va, last), va_arg(va, type), 以及va_end(va)这三个函数的作用。见slvher的专栏

问题是要补全/lib/printfmt.c 里“%o”部分的代码,照葫芦画瓢,如下:
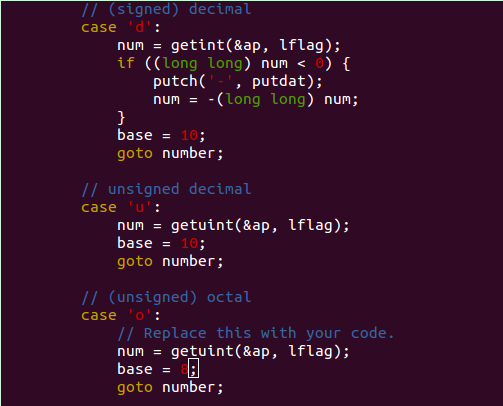
然后再解决以下几个问题:
1)Explain the interface between printf.c and console.c. Specifically, what function does console.c export? How is this function used by printf.c?
通过观察可以发现 kernel/printf.c 文件里包含一些字符的输出函数,其中调用的 cputchar() 函数定义在 kernel/console.c 文件里。cputchar() 函数用于将一个字符输出到 console。
2)Explain the following from console.c :
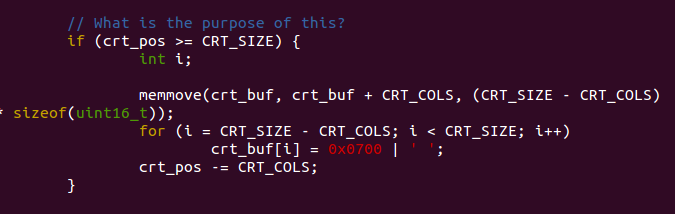
这里注意memmove其实就是把第二个参数指向的地址移动n byte到第一个参数指向的地址,这里n byte由第三个参数指定。这段代码主要是检测当前屏幕的输出buffer是否满了。如果buffer满了,把屏幕第一行覆盖掉逐行上移,空出最后一行,并由for循环填充以‘ ’(空格),最后把crt_pos减去CRT_COLS。
3)For the following questions you might wish to consult the notes for Lecture 2. These notes cover GCC's calling convention on the x86.
Trace the execution of the following code step by step(特别注意我对该题测试代码稍作了修改):
int x = 11, y = 13, z = 4;
cprintf("x %o, y %x, z %d\n", x, y, z);fmt 指向cprinft()函数的第一个参数的首地址,即字符串 "x %d, y %x, z %d\n" 的首地址。ap是一个va_list变量,va_start(ap, fmt)函数执行后ap指向第一个可变参数,也即x,进入 vcprintf() 函数后会按顺序指向 y,z。不过注意此处的这3个参数存储在函数栈里,与之前定义地址不同。vcprintf() 函数返回后在执行va_end(ap)后, ap 变为 NULL。
ii. List (in order of execution) each call to cons_putc, va_arg, and vcprintf. For cons_putc, list its argument as well. For va_arg, list what ap points to before and after the call. For vcprintf list the values of its two arguments.
本来是打算脑中模拟一下就好,但为了深入了解,还是要step by step 一下。
开始连代码如何检验都不知道,后来发现qemu窗口是有输出的,然后用grep 搜索了"Welcome to the JOS kernel monitor!",在 kernel/monitor里发现了源代码,紧随其后,我添加测试代码。然后去 obj/kernel.asm里查找生成的汇编代码,查找合适的入口地址进入,由于自己太弱,找了半天。。好多个人觉得合适的地方设置断点后(不知道为何,估计以后能懂),执行却发现已经执行完毕,无奈,一点一点将断点往前挪,反正找了半天,被自己蠢哭。
现在开始trace:
进入我们想要的位置,一切就绪
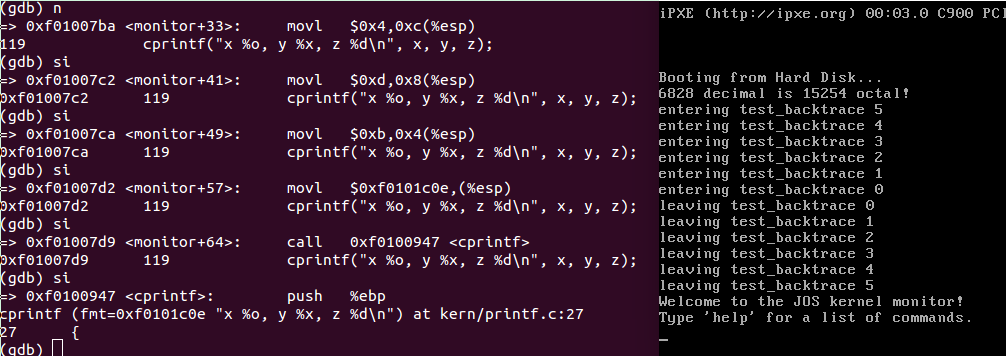
调试过程要联合使用si,s,n指令。
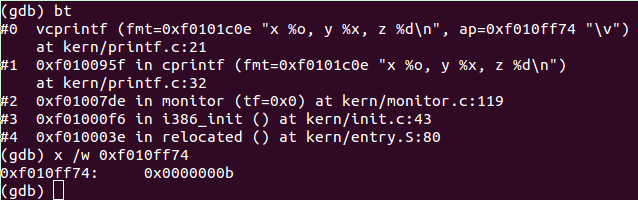
使用bt(backtrace) 指令打印当前的函数调用栈的所有信息。
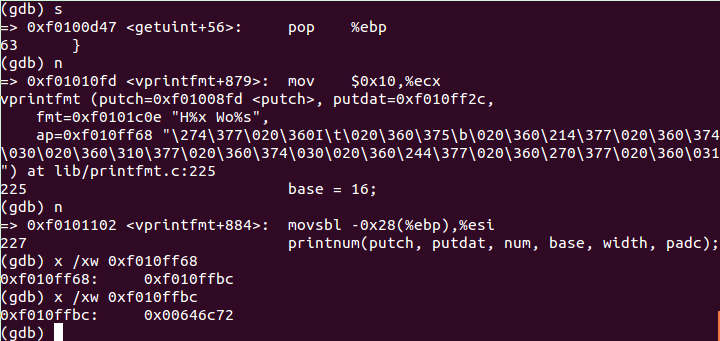
通过上图可知va_start(ap, fmt)后,ap=0xf010ff74,用x指令查询可得,ap当前指向一个int型,值为0xb,即11,就是cprintf("x %d, y %x, z %d\n", x, y, z)函数第一个可变参数x的值。进入cons_putc():

这里入口参数为120,是因为所有vprintfmt()函数读取字符全是以ASCII码存储的,而x的ASCII码为120。
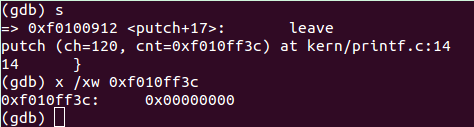
此处为执行完一次putch() 函数,可以看到ch = 120,cnt的地址为0xf010ff3c,其具体值为0,因为这是第一个要输出的字符。
代码继续执行,输出至下图时:
此时执行到第一个"%"
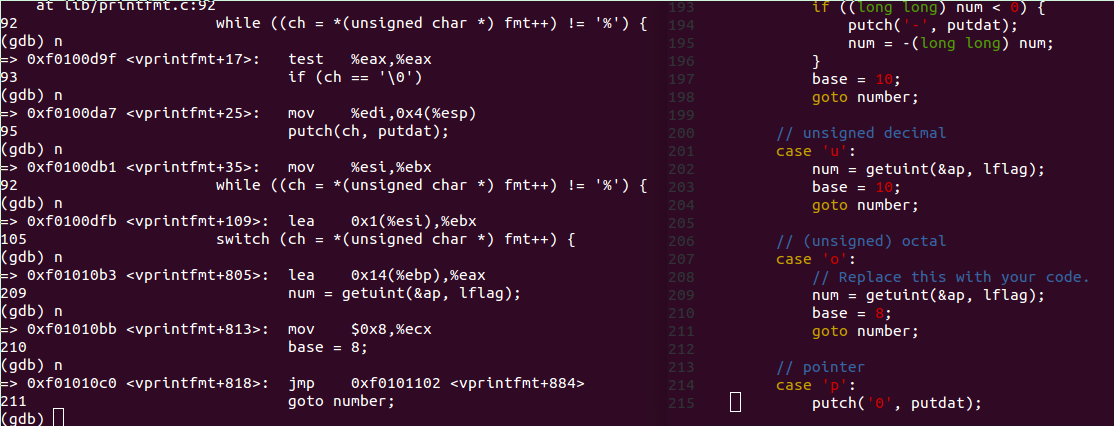
由于随后为"o",代码进入case "o"部分,随后将11以八进制输出: 13。

此处有个细节差点忘了,很重要的va_arg()函数在getuint()函数里执行,将ap指向0xf010ff78(此处忘记截图了),不过我们可以通过上次的ap = 0xf010ff74 加上int型的4字节得到。查看 0xf010ff78 处内存:
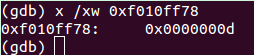
可见此时ap指向的就是 y 的值13.
printnum()里面有一句话开始没看懂,google后恍然大悟,其实就是整数到字符的转化。

拿num=11,base=8为例,num%base的结果是3,也即"0123456789abcdef"[3](从字符串选取字符,将其ascii码当做是putch()函数的第一个参数),就是字符'3'的acsii码,通过putch()函数输出字符'3'。
输出完毕后查看cnt = 14,说明输出14个字符。

这里有有个小插曲。一开始cnt 被初始化为0后就一直没有改变。打开 obj/kern/kernal.asm 发现代码 *cnt++ 貌似就没有生成汇编代码。以为是编译器的问题,后来自己重写了一个简单代码,运行后才发现是代码就有问题。由于++运算符的优先级高于 * 解引用,所以 *cnt++ 代码其实是 *(cnt++) 的意思。。。当然不会改变 cnt 指向的值了。。哎,源代码啊,也会有错,以后一定小心。
将代码改为 (*cnt)++ 后再次查看汇编代码:
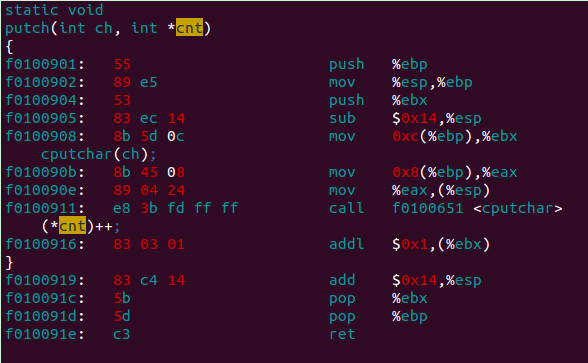
剩下的部分一样,就不分析了。好累。
4)Run the following code.
unsigned int i = 0x00646c72;
cprintf("H%x Wo%s", 57616, &i);
The output depends on that fact that the x86 is little-endian. If the x86 were instead big-endian what would you set i to in order to yield the same output? Would you need to change 57616 to a different value?
进入 cprintf() 函数后,57616 存储可见:

完成第一个输出后,ap 跳到第二个可变参数地址:此处一定注意第二个参数并不是变量本身,而是变量地址,地址占4字节。
输出时将把每个字节的数据当做一个字符输出,由于x86是little-endian,所以输出顺序是从低到高。
72对应 ' r ',6c对应 ' l ',64对应 ' d ',00为 ' \0 '。因此最后的输出为:

如果是big-endian,i = 0x726c6400即可,因为57616是按一个整体读取的,不需要修改。
5)In the following code, what is going to be printed after 'y='? (note: the answer is not a specific value.) Why does this happen?
cprintf("x=%d y=%d", 3);
6)Let's say that GCC changed its calling convention so that it pushed arguments on the stack in declaration order, so that the last argument is pushed last. How would you have to change cprintf or its interface so that it would still be possible to pass it a variable number of arguments?
这里涉及到变长参数,见头文件如下:
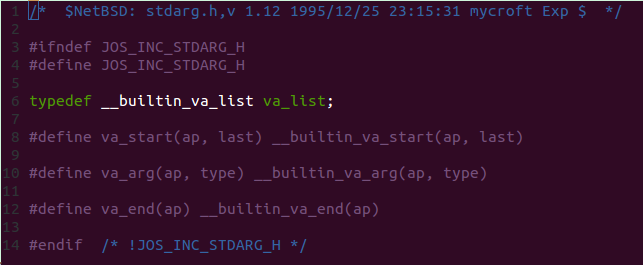
说明函数调用gcc里的函数,无奈没找到几个__builtin_函数的实现,只能参考以前的 inc/stdarg.h(来自北大张弛)
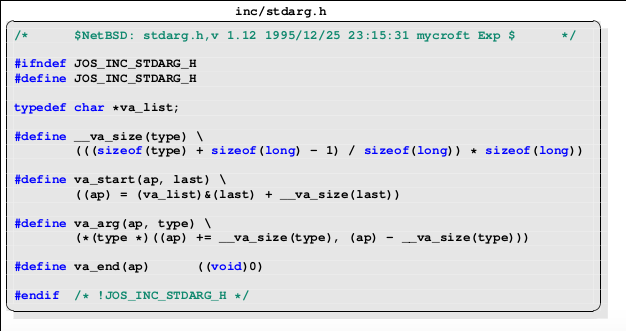
va_arg 每次是以地址往后增长取出下一参数变量的地址的,而这个实现方式是默认编译器是以从右往左的顺序将参数入栈的,且栈是以从高往低的方向增长的。后压栈的参数放在了内存地址的低位置,所以如果要以从左到右的顺序依次取出每个变量,那么编译器必须以相反的顺序即从右往左将参数压栈。如果编译器更改了压栈的顺序,那么为了仍然能正确取出所有的参数,那么需要修改上面代码中的 va_start 和 va_arg 两个宏,即
#define va_start(ap, last) ((ap) = (va_list)&(last) - __va_size(last))
#define va_arg(ap, type) (*(type *)((ap) -= __va_size(type), (ap) + __va_size(type)))

JOS提供了不同颜色的打印功能。
通过上面的熟悉,我们知道cprintf()函数的调用过程如下:
cprintf() → vcprintf() → vprintfmt() → putch() → cputchar()→ cons_putc()
cons_putc()函数调用了3个函数:serial_putc() lpt_putc() cga_putc() 其中前两个函数无关颜色打印。我们重点分析cga_putc()函数。
回顾 kern/printfmt.c 我们可以发现
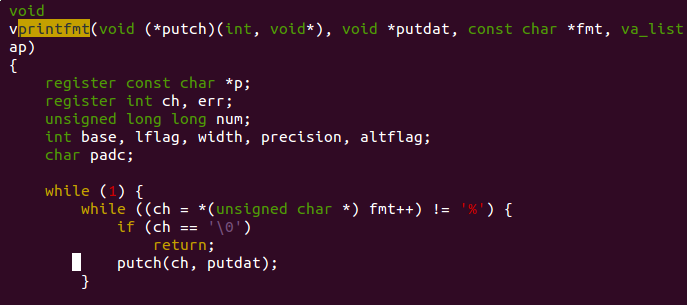
虽然我们在读取 fmt 时是按字符读取的,但我们却是用 int 型来存储(其实只用了16bit),再用 putch()函数打印,这样做的一个原因是可以为每个要打印的字符添加其他属性,比如颜色。kern/console.c 里 cga_putc() 函数证明了这个观点。
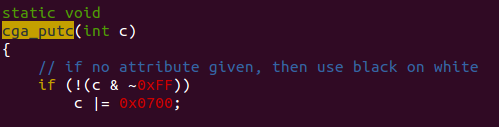
可知 c 的低八位用来存放字符ASCII码,高八位用来存放颜色属性。属性位描述如下:
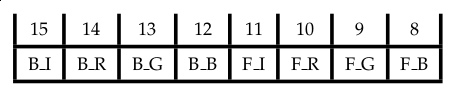
c 的15到12位用于指定字符的背景颜色,字符颜色由11 - 9位RGB颜色代码+ 8位是否高亮指定。0x07 即代表黑底白字。
作为简单练习,在 cprintf() 的格式字符串中增加格式化参数%C,用来指定下一个即将打印字符的颜色(当前做的比较简易,相当于在%c的基础上加上颜色,且只有字体颜色,无背景色)。为了可读性,特别添加颜色宏定义。如下图,见 kern/printfmt.c
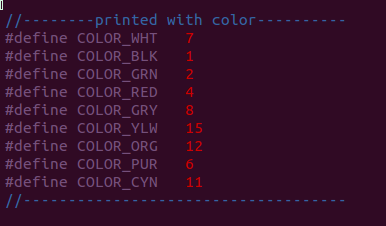
代码实现:
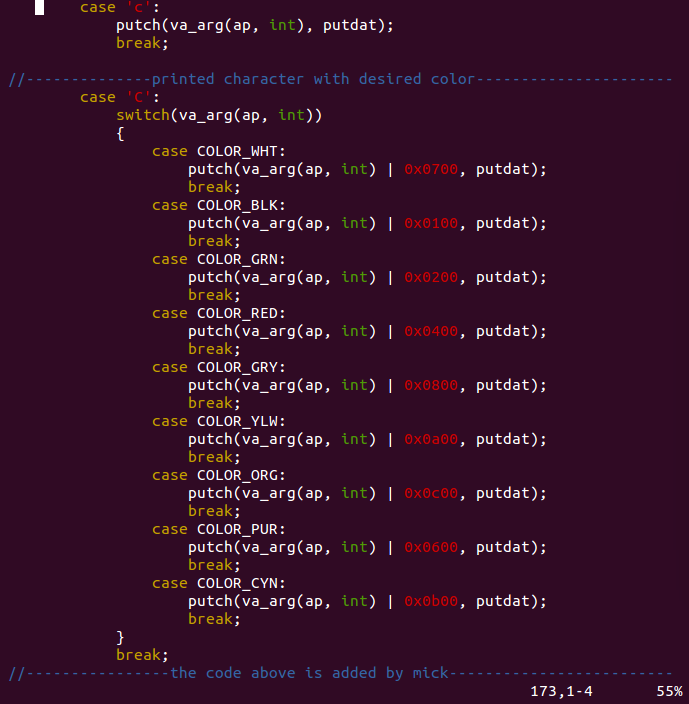
并在 kern/monitor.c 修改打印内容:
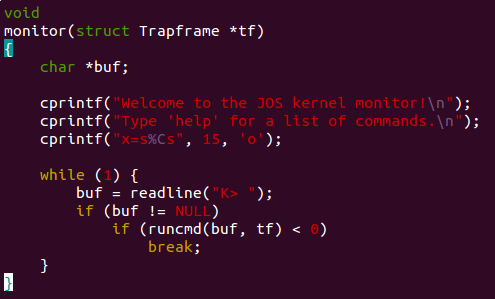
打印结果如下:

想设成黄色的,结果颜色有点不太对啊,再说吧~
The Stack
以下三篇参考让栈的原理简单易懂:
同时还参考AT&T汇编语言与GCC内嵌汇编

打开 kern/entry.S :可以发现内核的栈初始化就在这部分。
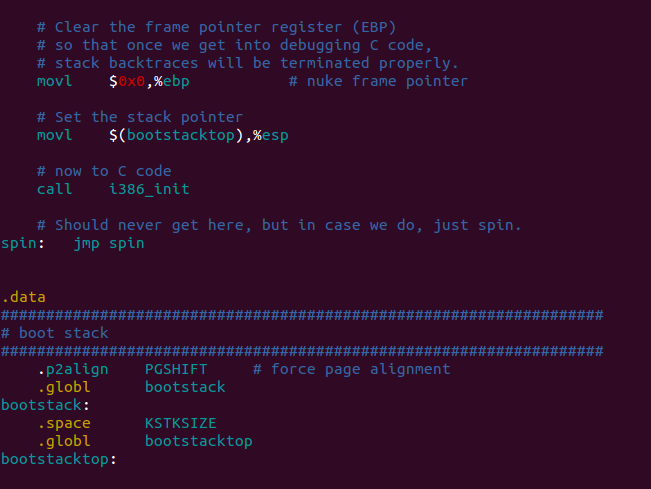
内核初始作的工作主要是将寄存器%ebp初始为0,%esp初始化为bootstacktop。
我们发现栈有两部分,第一部分是实际栈空间,一共KSTKSIZE,其大小定义在inc/memlayout.h中,KSTKSIZE = 8 × PGSIZE = 8 × 4096B = 32KB,另一部分是栈底指针bootstacktop,因为它指向栈空间定义完以后的高地址位置。前面我们说过栈是向低地址增长的,所以最高位置就是栈底,这个位置会作为初值传递给%esp。

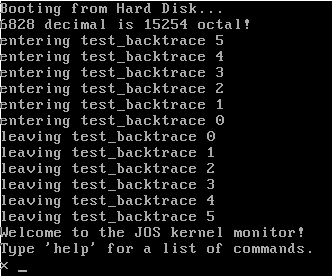
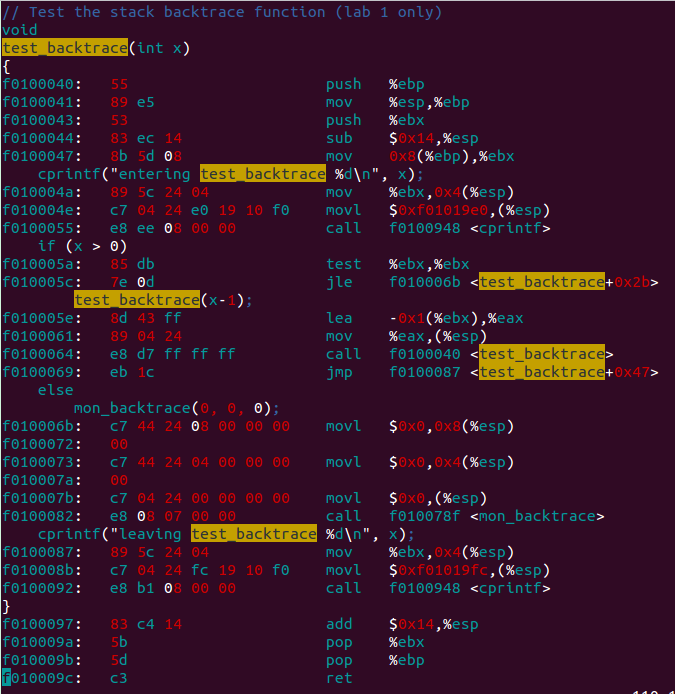
这个练习要求我们要熟悉一下栈。打开 obj/kern/kernal.asm 主要分析函数 test_backtrace(),首先找该函数的调用入口:

在跳转到 test_backtrace() 之前,先将参数 5 替换存入函数i386_init()的栈顶,然后跳转。
再来看test_backtrace() 函数:
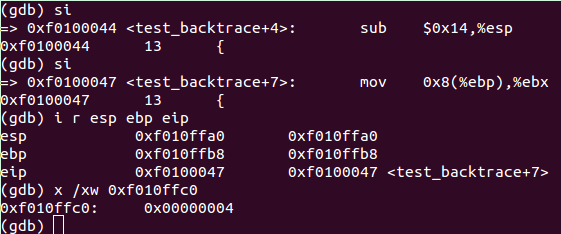
为了更清楚的理解,我们逐步trace一下,首先将代码运行到0xf01000de处,并查看当前相关信息:
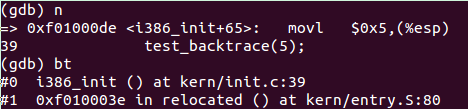
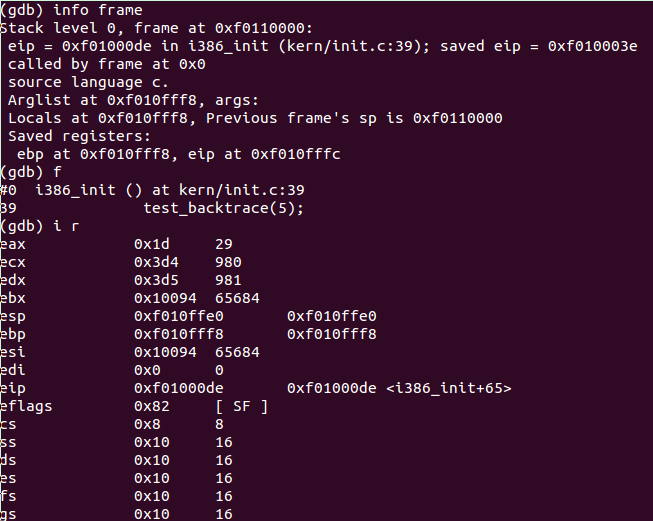
当前寄存器
| EBP | ESP | EIP |
| 0xf010fff8 | 0xf010ffe0 | 0xf01000e5 |
si单步执行后查看栈顶内存:
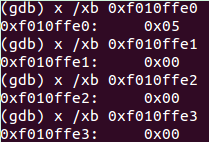
si单步执行 call() 函数后,eip会指向0xf0100040,ebp不变,esp由于call函数压栈 0xf01000ea 。如下:
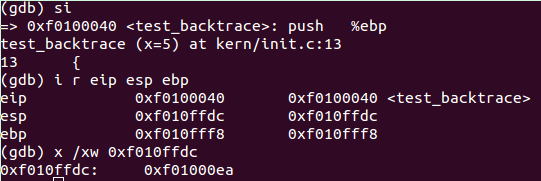
执行到 0xf0100047 后查看寄存器及内存:
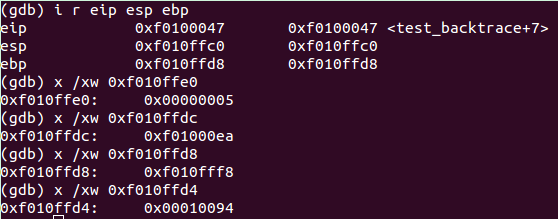
下面20字节用于存储临时空间。(说明test_backtrace(5)的函数栈从0xf0100xf010ffd8到0xf010ffc0,这之上的0xf010ffdc存储的是eip,0x0xf010ffbc 将会存的也是 eip,也即由于函数调用的关系函数栈与栈之间会有存储的 eip,当前我们没用将其算入某个函数栈里,但其确实要占用4字节的空间)
出于好奇,我又从最开始trace了一下,发现代码运行到i386_init()后的函数栈如下:
也即该函数的函数栈从0xf010fff8开始到0xf010ffe0,刚好与上面的联系了起来。
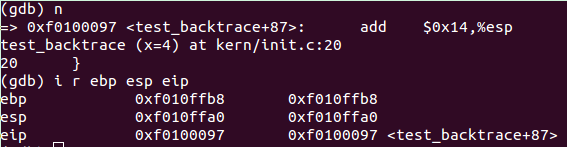
好了,言归正题,当代码运行到test_backtrace(4),我们可以观察寄存器可知:说明test_backtrace(4)的函数栈从0xf0100xf010ffb8到0xf010ffa0。
剩下的可以依次类推。我们可以发现每个 test_backtrace() 函数一共有4类栈空间使用:
1)入口处%ebp压栈。
2)将%ebx压栈,保存函数参数。
3)保留0x14个即20个byte的空间作为临时变量储存。
4)在call时,将%eip压栈。
一共4+4+20+4=32(byte),也即每次调用 test_backtrace() 函数,会压栈32字节的空间。
查看代码的结尾处,与压栈的过程刚好相反:
add $0x14,%esp
pop %ebxpop %ebpret我们可以trace验证如下,将代码运行到 test_backtrace(4) :
当前栈底 0xf010ffb8,栈顶 0xf010ffa0。
执行以上4句后:
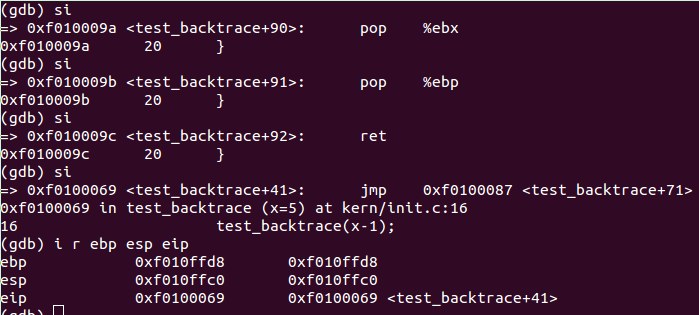
可见,代码返回到 test_backtrace(5) 部分。
这就是整个函数栈的使用过程,注意压栈与出栈过程成对相符。
这里我们穿插一部分只读数据的存储,由:


可以看出只读数据的存储位置在 0xf01019e0 ,这与 obj/kern/kernal 的反汇编结果相符,存储在 .rodata 段。

查看内存可以验证如下:


补全 kern/monitor.c 里的 mon_backtrace() 函数。
通过上面的栈练习,我们已经清楚栈的结构,如下,注意每个框表示4个字节,高处为高地址,arg1是最左边的函数参数,%ebp指向最上面地址,在未调用函数时 %esp 指向arg1,即栈顶,出现函数调用后 eip 寄存器被压栈,esp - 1,指向最下面的地址。
| ebp(上一个函数栈底) |
| ebx |
| arg5 |
| arg4 |
| arg3 |
| arg2 |
| arg1 |
| eip |
根据题意,kern/monitor.c 代码如下:
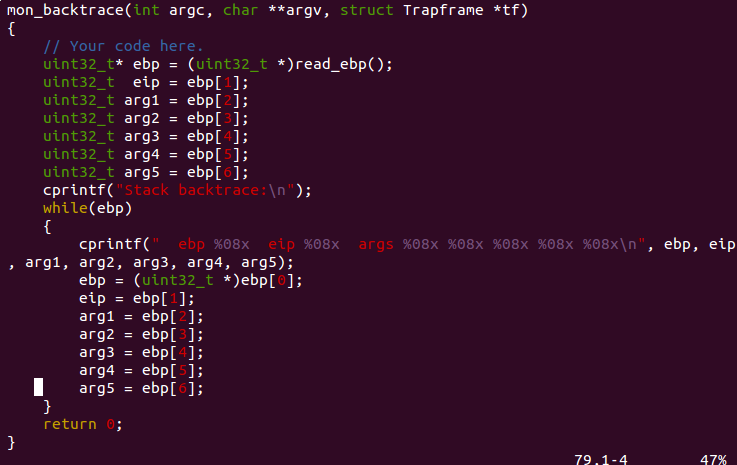
我们通过read_ebp()函数读取当前 %ebp 的值,我们要将其以地址的方式存储起来,这时0x0[%ebp]可以读出上个函数的栈指针,0x4[%ebp]可以读出返回地址%eip,0x8[%ebp]可以读出第一个参数. . .
make qemu后结果:
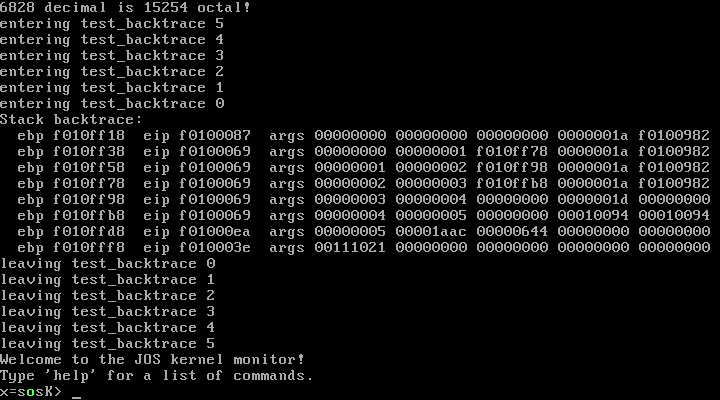
好的消息是我们代码运行并未出现Exerise 11所说的read_ebp()函数在mon_backtrace()函数之前执行。
注意此处的函数栈 0xf010fff8对应于i386_init(),接着6个对应于 test_backtrace() ,0xf010ff18 则对应于 mon_backtrace(),可以从args 看出。例如当前栈 0xf010ff18 ,对应于函数 mon_backtrace() ,其输入参数为三个0,与 args 前三个参数为 0 相符。
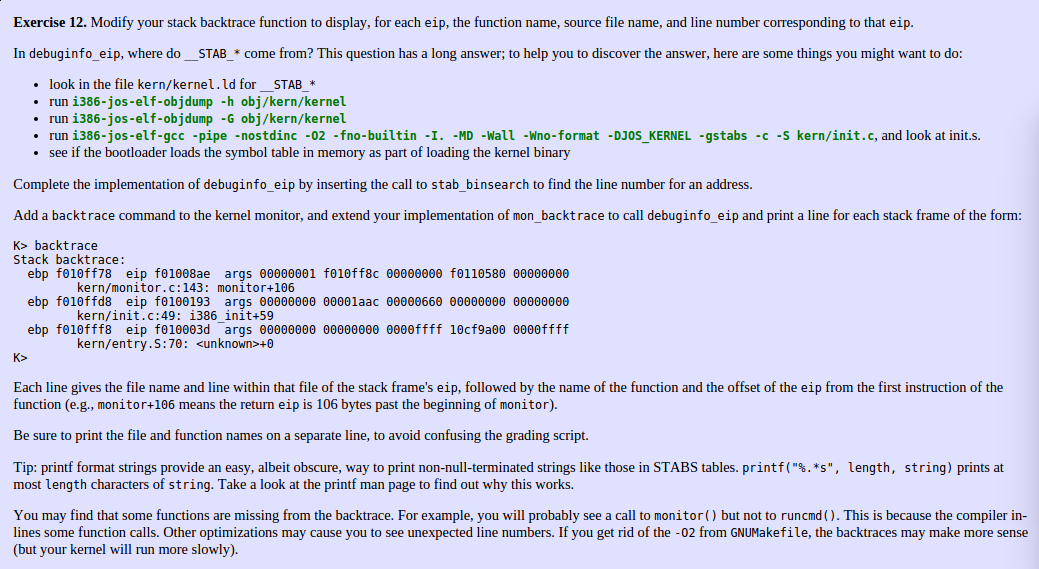
Exerise12 参考自北大陈驰
这一部分还没做完,以后有时间再细看。
先插一个小例子:
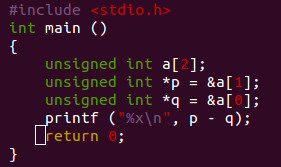
开始我觉得结果会是a[1]与a[0]地址的差4,可结果却是1,主要是因为同类型的指针相减是会自动除以所指类型的size的。这点对于我们理解后面的代码有关键的作用。
stab节在ELF文件结构为符号表部分,这一部分的功能是程序报错时可以提供报错和调试信息。还有一节stabstr,为符号表的字符串部分,这个是和stab配合打印使用的。
我们可以使用objdump -G 命令查看一个ELF文件的stab节信息,比如我们objdump -G obj/kern/kernel后得到了下面的输出:
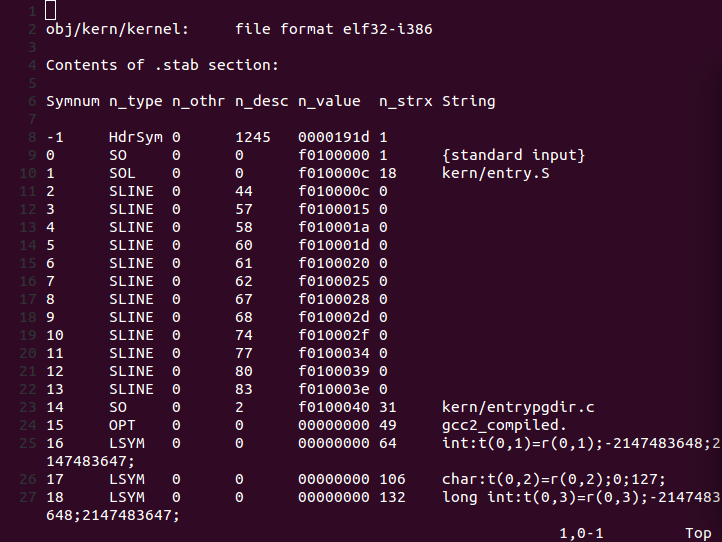
内容太长,这里我只截取了最前面的一部分。n_type表示类型,SO表示主函数的文件名,SOL表示被包含的文件名,SLINE表示代码段的行号,FUN表示函数名称。
为了能把结构看的更清楚,我们按符号类型将输出项归类一下,比如运行objdump -G obj/kern/kernel | grep ’SO\b’观察一下kernel中编译的所有文件名,得到:
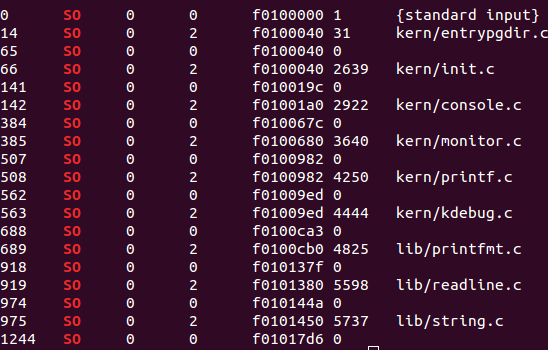
对比 obj/kern/kernal.asm 可以发现上图第五列正是每个文件在编译后在ELF文件中的链接地址,从小到大依次排列。
再观察一下所有的函数名:运行objdump -G obj/kern/kernel | grep ‘FUN’,可以看到前几行的结果:
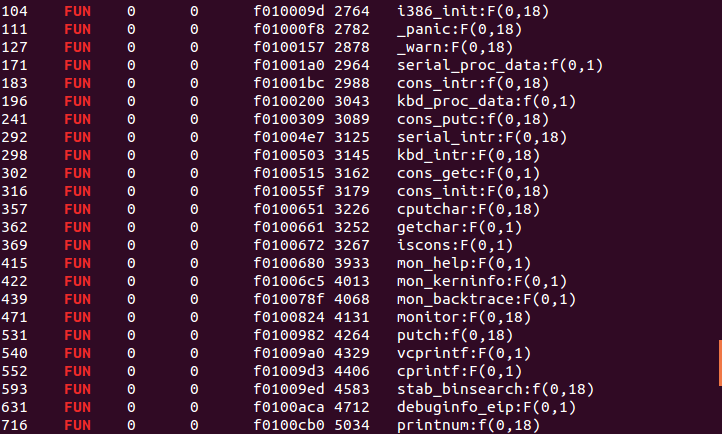
稍加观察可以发现, warn , panic , test_backtrace 和 i386_init 4个函数都是属于kern/init.c,从 delay 到 kbd_proc_data 都是属于kern/console.c,可以看到这些函数也是按照他们属于各自文件的顺序,依次排列在链接地址空间里的。
所以我们查找一个符号的文件信息、所在函数以及所在行数的思路就很清楚了,如果要查找所在文件,根据该符号所在的虚拟地址,只要查找两个相邻的SO符号表项里前者地址和后者地址一起包含了该符号的地址就可以了。所在函数类似。
但是这个做法在找行号的时候出现了问题,当我们查看SLINE时,输出了这样的结果:
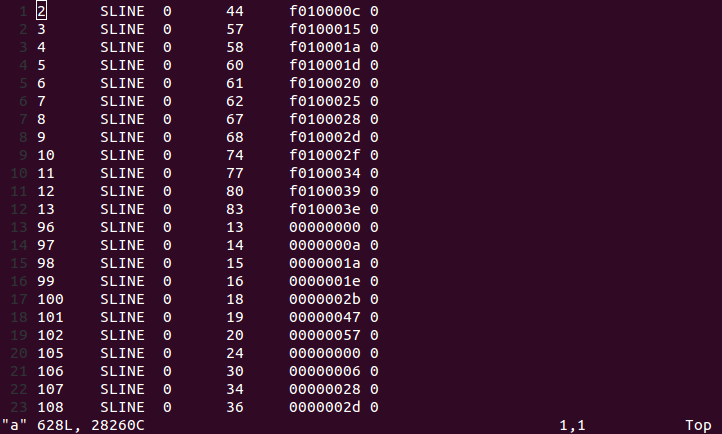
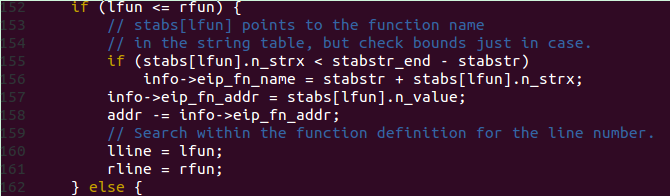
可以看到有的符号地址变成了很小的数,这样我们在以 eip 这样的指针进来查询时肯定是对不上号的。不过好在有前面提到的那种包含关系,我们可以通过一次地址转换以后做到。对stab进行操作的代码定义在了kern/kdebug.c中,读懂 stab_binsearch() 函数与 debuginfo_eip() 函数的作用。
其中第158行即是SLINE很小的原因。














 1094
1094











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









