







5.6.2. 创建解析器上下文
创建了主词法分析器后,是时候创建解析器本身了。首先是其上下文。
cp_parser_new (continue)
2240 parser = ggc_alloc_cleared (sizeof (cp_parser));
2241 parser->lexer = lexer;
2242 parser->context = cp_parser_context_new (NULL);
2243
2244 /* For now, we always accept GNU extensions. */
2245 parser->allow_gnu_extensions_p = 1;
2246
2247 /* The `>' token is a greater-than operator, not the end of a
2248 template-id. */
2249 parser->greater_than_is_operator_p = true;
2250
2251 parser->default_arg_ok_p = true;
2252
2253 /* We are not parsing a constant-expression. */
2254 parser->integral_constant_expression_p = false;
2255 parser->allow_non_integral_constant_expression_p = false;
2256 parser->non_integral_constant_expression_p = false;
2257
2258 /* We are not parsing offsetof. */
2259 parser->in_offsetof_p = false;
2260
2261 /* Local variable names are not forbidden. */
2262 parser->local_variables_forbidden_p = false;
2263
2264 /* We are not processing an `extern "C"' declaration. */
2265 parser->in_unbraced_linkage_specification_p = false;
2266
2267 /* We are not processing a declarator. */
2268 parser->in_declarator_p = false;
2269
2270 /* We are not processing a template-argument-list. */
2271 parser->in_template_argument_list_p = false;
2272
2273 /* We are not in an iteration statement. */
2274 parser->in_iteration_statement_p = false;
2275
2276 /* We are not in a switch statement. */
2277 parser->in_switch_statement_p = false;
2278
2279 /* We are not parsing a type-id inside an expression. */
2280 parser->in_type_id_in_expr_p = false;
2281
2282 /* The unparsed function queue is empty. */
2283 parser->unparsed_functions_queues = build_tree_list (NULL_TREE, NULL_TREE);
2284
2285 /* There are no classes being defined. */
2286 parser->num_classes_being_defined = 0;
2287
2288 /* No template parameters apply. */
2289 parser->num_template_parameter_lists = 0;
2290
2291 return parser;
2292 }
这个上下文具有如下类型。
1107 typedef struct cp_parser_context GTY (()) in parser.c
1108 {
1109 /* If this is a tentative parsing context, the status of the
1110 tentative parse. */
1111 enum cp_parser_status_kind status;
1112 /* If non-NULL, we have just seen a `x->' or `x.' expression. Names
1113 that are looked up in this context must be looked up both in the
1114 scope given by OBJECT_TYPE (the type of `x' or `*x') and also in
1115 the context of the containing expression. */
1116 tree object_type;
1117 /* The next parsing context in the stack. */
1118 struct cp_parser_context *next;
1119 } cp_parser_context;
所有活动的上下文应该形成一个栈,这由cp_parser_context_new来保证。
1137 static cp_parser_context *
1138 cp_parser_context_new (cp_parser_context* next) in parser.c
1139 {
1140 cp_parser_context *context;
1141
1142 /* Allocate the storage. */
1143 if (cp_parser_context_free_list != NULL)
1144 {
1145 /* Pull the first entry from the free list. */
1146 context = cp_parser_context_free_list;
1147 cp_parser_context_free_list = context->next;
1148 memset (context, 0, sizeof (*context));
1149 }
1150 else
1151 context = ggc_alloc_cleared (sizeof (cp_parser_context));
1152 /* No errors have occurred yet in this context. */
1153 context->status = CP_PARSER_STATUS_KIND_NO_ERROR;
1154 /* If this is not the bottomost context, copy information that we
1155 need from the previous context. */
1156 if (next)
1157 {
1158 /* If, in the NEXT context, we are parsing an `x->' or `x.'
1159 expression, then we are parsing one in this context, too. */
1160 context->object_type = next->object_type;
1161 /* Thread the stack. */
1162 context->next = next;
1163 }
1164
1165 return context;
1166 }
5.7. 准备延迟访问列表
在C++里,class或struct或union的成员应用了访问控制。这些访问控制,在解析过程中,即便在出现在不适合访问控制的代码片段中,也应该在合适的地方进行访问控制检查。因而前端使用栈deferred_access_stack来控制这些访问控制。在这个栈里,每个节点都是deferred_access类别,而枚举值deferring_kind表示对该访问控制所应该采用的行为。新节点由push_deferring_access_checks加入,而移除函数则是pop_deferring_access_checks。
3077 typedef enum deferring_kind { in cp-tree.h
3078 dk_no_deferred = 0, /* Check access immediately */
3079 dk_deferred = 1, /* Deferred check */
3080 dk_no_check = 2 /* No access check */
3081 } deferring_kind;
c_parse_file暗示,当开始解析一个新的源文件时,它也是一个新的访问控制域,一个新节点将被插入以表示这一级别上的控制。而如果flag_access_control是非0(对于C/C++,其默认值是1,它可以通过选项–faccess-control改写),参数deferring将是dk_no_deferred,否则为dk_no_check。
139 void
140 push_deferring_access_checks (deferring_kind deferring) in semantics.c
141 {
142 deferred_access *d;
143
144 /* For context like template instantiation, access checking
145 disabling applies to all nested context. */
146 if (deferred_access_stack
147 && deferred_access_stack->deferring_access_checks_kind == dk_no_check)
148 deferring = dk_no_check;
149
150 /* Recycle previously used free store if available. */
151 if (deferred_access_free_list)
152 {
153 d = deferred_access_free_list;
154 deferred_access_free_list = d->next;
155 }
156 else
157 d = ggc_alloc (sizeof (deferred_access));
158
159 d->next = deferred_access_stack;
160 d->deferred_access_checks = NULL_TREE;
161 d->deferring_access_checks_kind = deferring;
162 deferred_access_stack = d;
163 }
在结构体deferred_access中,域deferred_access_checks记录了该级别的延迟访问检查(当域deferring_access_checks_kind是dk_deferred),这表明推迟访问检查,直到在后面显式地提出要求。而域next把其他级别上的访问检查串接起来。
3119 typedef struct deferred_access GTY(()) in cp-tree.h
3120 {
3121 /* A TREE_LIST representing name-lookups for which we have deferred
3122 checking access controls. We cannot check the accessibility of
3123 names used in a decl-specifier-seq until we know what is being
3124 declared because code like:
3125
3126 class A {
3127 class B {};
3128 B* f();
3129 }
3130
3131 A::B* A::f() { return 0; }
3132
3133 is valid, even though `A::B' is not generally accessible.
3134
3135 The TREE_PURPOSE of each node is the scope used to qualify the
3136 name being looked up; the TREE_VALUE is the DECL to which the
3137 name was resolved. */
3138 tree deferred_access_checks;
3139 /* The current mode of access checks. */
3140 enum deferring_kind deferring_access_checks_kind;
3141 /* The next deferred access data in stack or linked-list. */
3142 struct deferred_access *next;
3143 } deferred_access;
5.8. 向解析器传入符号
前面我们已经看到cp_lexer_get_preprocessor_token读入经过预处理的符号,并把符号从cpp_token类型转换至cp_token类型。不过cp_token类型的符号的缓存是由词法分析器维护的,因而对词法分析器而言,其符号读入函数是cp_lexer_read_token。
474 static cp_token *
475 cp_lexer_read_token (cp_lexer * lexer) in parser.c
476 {
477 cp_token *token;
478
479 /* Make sure there is room in the buffer. */
480 cp_lexer_maybe_grow_buffer (lexer);
481
482 /* If there weren't any tokens, then this one will be the first. */
483 if (!lexer->first_token)
484 lexer->first_token = lexer->last_token;
485 /* Similarly, if there were no available tokens, there is one now. */
486 if (!lexer->next_token)
487 lexer->next_token = lexer->last_token;
488
489 /* Figure out where we're going to store the new token. */
490 token = lexer->last_token;
491
492 /* Get a new token from the preprocessor. */
493 cp_lexer_get_preprocessor_token (lexer, token);
494
495 /* Increment LAST_TOKEN. */
496 lexer->last_token = cp_lexer_next_token (lexer, token);
497
498 /* Strings should have type `const char []'. Right now, we will
499 have an ARRAY_TYPE that is constant rather than an array of
500 constant elements.
501 FIXME: Make fix_string_type get this right in the first place. */
502 if ((token->type == CPP_STRING || token->type == CPP_WSTRING)
503 && flag_const_strings)
504 {
505 tree type;
506
507 /* Get the current type. It will be an ARRAY_TYPE. */
508 type = TREE_TYPE (token->value);
509 /* Use build_cplus_array_type to rebuild the array, thereby
510 getting the right type. */
511 type = build_cplus_array_type (TREE_TYPE (type), TYPE_DOMAIN (type));
512 /* Reset the type of the token. */
513 TREE_TYPE (token->value) = type;
514 }
515
516 return token;
517 }
为了有效使用资源,cp_lexer的buffer域是一个环形缓存,而last_token指向紧跟在最后一个可用符号的地址,first_token则指向第一个被缓存的符号,next_token指向第一个尚未被窥视(peek)的符号。
一开始,这个环形缓存的大小是5(CP_TOKEN_BUFFER_SIZE),与用C++所能写出的复杂语句相比,这个缓存非常的小。为了避免缓存不够用,在从预处理器读入符号前,调用cp_lexer_maybe_grow_buffer视需要扩大缓存。
521 static void
522 cp_lexer_maybe_grow_buffer (cp_lexer * lexer) in parser.c
523 {
524 /* If the buffer is full, enlarge it. */
525 if (lexer->last_token == lexer->first_token)
526 {
527 cp_token *new_buffer;
528 cp_token *old_buffer;
529 cp_token *new_first_token;
530 ptrdiff_t buffer_length;
531 size_t num_tokens_to_copy;
532
533 /* Remember the current buffer pointer. It will become invalid,
534 but we will need to do pointer arithmetic involving this
535 value. */
536 old_buffer = lexer->buffer;
537 /* Compute the current buffer size. */
538 buffer_length = lexer->buffer_end - lexer->buffer;
539 /* Allocate a buffer twice as big. */
540 new_buffer = ggc_realloc (lexer->buffer,
541 2 * buffer_length * sizeof (cp_token));
542
543 /* Because the buffer is circular, logically consecutive tokens
544 are not necessarily placed consecutively in memory.
545 Therefore, we must keep move the tokens that were before
546 FIRST_TOKEN to the second half of the newly allocated
547 buffer. */
548 num_tokens_to_copy = (lexer->first_token - old_buffer);
549 memcpy (new_buffer + buffer_length,
550 new_buffer,
551 num_tokens_to_copy * sizeof (cp_token));
552 /* Clear the rest of the buffer. We never look at this storage,
553 but the garbage collector may. */
554 memset (new_buffer + buffer_length + num_tokens_to_copy, 0,
555 (buffer_length - num_tokens_to_copy) * sizeof (cp_token));
556
557 /* Now recompute all of the buffer pointers. */
558 new_first_token
559 = new_buffer + (lexer->first_token - old_buffer);
560 if (lexer->next_token != NULL)
561 {
562 ptrdiff_t next_token_delta;
563
564 if (lexer->next_token > lexer->first_token)
565 next_token_delta = lexer->next_token - lexer->first_token;
566 else
567 next_token_delta =
568 buffer_length - (lexer->first_token - lexer->next_token);
569 lexer->next_token = new_first_token + next_token_delta;
570 }
571 lexer->last_token = new_first_token + buffer_length;
572 lexer->buffer = new_buffer;
573 lexer->buffer_end = new_buffer + buffer_length * 2;
574 lexer->first_token = new_first_token;
575 }
576 }
下面的图形展示了扩大词法分析器缓存的细节,在(b)图中需要将最后一个符号后面的内存清零,以告诉垃圾收集器它们已被使用。
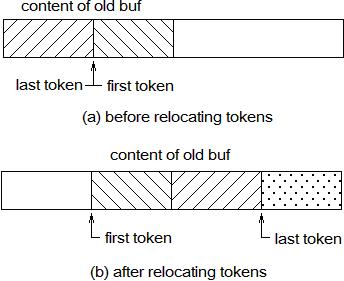
图42:扩展词法分析器缓存
当缓存有足够的资源并且读入了新的符号,在496行,cp_lexer_next_token前推last_token 至刚读入符号的边上。
418 static inline cp_token *
419 cp_lexer_next_token (cp_lexer* lexer, cp_token* token) in parser.c
420 {
421 token++;
422 if (token == lexer->buffer_end)
423 token = lexer->buffer;
424 return token;
425 }
上面在cp_lexer_read_token的503行,flag_const_strings如果非0,表示按标准的规定,把字符串常量声明为`const char *'类型。















 2315
2315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









