








概述
本文档介绍了如何获取和运行Solr,将各种数据源收集到多个集合中,以及了解Solr管理和搜索界面。
首先解压缩Solr版本并将工作目录更改为安装Solr的子目录。请注意,基本目录名称可能随Solr下载的版本而有所不同。例如,在UNIX,Cygwin或MacOS中使用shell:
/:$ ls solr *
solr-6.2.0.zip
/:$ unzip -q solr-6.2.0.zip
/:$ cd solr-6.2.0 要启动Solr,请运行:bin / solr start -e cloud -noprompt(Windows系统cmd命令一样执行)
/solr-6.4.2:$ bin/solr start -e cloud -noprompt
Welcome to the SolrCloud example!
为您的示例SolrCloud集群启动2个Solr节点。
Starting up 2 Solr nodes for your example SolrCloud cluster.
...
在端口8983上启动Solr服务器(pid = 8404)
Started Solr server on port 8983 (pid=8404). Happy searching!
...
在端口7574(pid = 8549)上启动Solr服务器
Started Solr server on port 7574 (pid=8549). Happy searching!
...
SolrCloud example running, please visit http://localhost:8983/solr
/solr-6.4.2:$ _通过在Web浏览器中加载Solr Admin UI,可以看到Solr正在运行:http:// localhost:8983 / solr /。这是管理Solr的主要起点。
Solr现在将运行两个“节点”,一个在端口7574上,一个在端口8983上。有一个集合自动创建,开始,两个分片集合,每个集合有两个副本。管理界面中的云标签很好地描绘了集合:
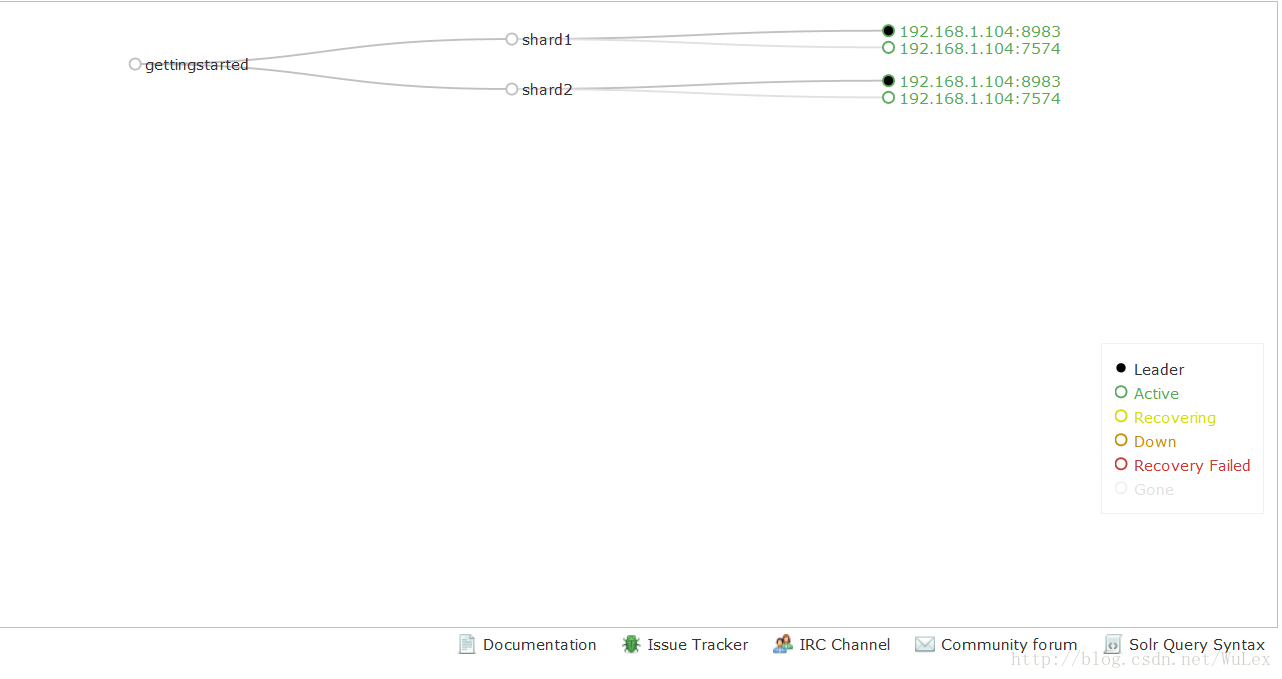
索引数据
您的Solr服务器已启动并正在运行,但它不包含任何数据。 Solr安装包括bin / post工具,以便于从开始方便地将各种类型的文档轻松导入Solr。我们将使用此工具作为下面的索引示例。
您将需要一个命令shell来运行这些示例,这些例程位于Solr安装目录中;你从哪里推出Solr的shell工作正常。
注意:目前bin / post工具没有可比较的Windows脚本,但调用的底层Java程序可用。有关详细信息,请参阅Post Tool, Windows section。
索引“富”文件的目录
让我们首先索引本地“富”文件,包括HTML,PDF,Microsoft Office格式(如MS Word),纯文本和许多其他格式。 bin / post具有爬取文件目录的能力,可选地递归平均,将每个文件的原始内容发送到Solr中进行提取和索引。 Solr安装包括一个docs /子目录,这样就可以创建一个方便的(主要是)内置的HTML文件。
bin/post -c gettingstarted docs/以下是它的结果:
/solr-6.4.2:$ bin/post -c gettingstarted docs/
java -classpath /solr-6.4.2/dist/solr-core-6.4.2.jar -Dauto=yes -Dc=gettingstarted -Ddata=files -Drecursive=yes org.apache.solr.util.SimplePostTool docs/
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/solr/gettingstarted/update...
Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
Entering recursive mode, max depth=999, delay=0s
Indexing directory docs (3 files, depth=0)
POSTing file index.html (text/html) to [base]/extract
POSTing file quickstart.html (text/html) to [base]/extract
POSTing file SYSTEM_REQUIREMENTS.html (text/html) to [base]/extract
Indexing directory docs/changes (1 files, depth=1)
POSTing file Changes.html (text/html) to [base]/extract
...
4329 files indexed.
COMMITting Solr index changes to http://localhost:8983/solr/gettingstarted/update...
Time spent: 0:01:16.252命令行分解如下:
-c gettingstarted:要索引到的集合的名称
docs/:Solr安装docs/目录的相对路径您现在已将数千个文档索引到Solr中gettingstarted 的集合中,并提交了这些更改。您可以通过加载Admin UI查询选项卡,在q param(替换*:*,匹配所有文档)和“Execute Query”中输入“solr”来搜索“solr”。有关详细信息,请参阅下面的搜索部分。要索引自己的数据,请重新运行指向您自己的文档目录的目录索引命令。例如,在Mac而不是docs / try〜/ Documents /或〜/ Desktop /!你可能想从一个干净的,空的系统再次开始,而不是有你的内容除了Solr docs /目录;请参阅下面的清理部分,了解如何恢复到一个干净的起点。
索引Solr XML
Solr支持以各种传入格式索引结构化内容。用于将结构化内容转换为Solr的历史上最主要的格式是Solr XML。许多Solr索引器已经被编码以将域内容处理成Solr XML输出,通常HTTP直接发布到Solr的/更新端点。
Solr的安装包括一些Solr XML格式的文件与示例数据(大多是模拟的技术产品数据)。注意:此技术产品数据具有更多特定于域的配置,包括架构和浏览UI。 bin / solr脚本包括通过运行bin / solr start -e techproducts的内置支持,它不仅启动了Solr,而且还索引了这些数据(在尝试之前一定要bin / solr stop -all)。但是,下面的示例假设Solr是用bin / solr start -e cloud启动的,以保持与此页面上的所有示例一致,因此使用的集合是“gettingstarted”,而不是“techproducts”。
使用bin / post,在example / exampledocs /中索引示例Solr XML文件:
bin/post -c gettingstarted example/exampledocs/*.xml以下是您会看到的内容:
/solr-6.4.2:$ bin/post -c gettingstarted example/exampledocs/*.xml
java -classpath /solr-6.4.2/dist/solr-core-6.4.2.jar -Dauto=yes -Dc=gettingstarted -Ddata=files org.apache.solr.util.SimplePostTool example/exampledocs/gb18030-example.xml ...
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/solr/gettingstarted/update...
Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
POSTing file gb18030-example.xml (application/xml) to [base]
POSTing file hd.xml (application/xml) to [base]
POSTing file ipod_other.xml (application/xml) to [base]
POSTing file ipod_video.xml (application/xml) to [base]
POSTing file manufacturers.xml (application/xml) to [base]
POSTing file mem.xml (application/xml) to [base]
POSTing file money.xml (application/xml) to [base]
POSTing file monitor.xml (application/xml) to [base]
POSTing file monitor2.xml (application/xml) to [base]
POSTing file mp500.xml (application/xml) to [base]
POSTing file sd500.xml (application/xml) to [base]
POSTing file solr.xml (application/xml) to [base]
POSTing file utf8-example.xml (application/xml) to [base]
POSTing file vidcard.xml (application/xml) to [base]
14 files indexed.
COMMITting Solr index changes to http://localhost:8983/solr/gettingstarted/update...
Time spent: 0:00:02.077…现在你可以使用默认的Solr查询语法(Lucene查询语法的超集)搜索所有类型的东西…
注意:您可以浏览在http:// localhost:8983 / solr / gettingstarted / browse处索引的文档。 / browse UI允许了解Solr的技术功能如何在熟悉的,虽然有点粗糙和原型的交互式HTML视图中工作。 (/ browse视图默认为假设获取启动的模式和数据是结构化XML,JSON,CSV示例数据和非结构化丰富文档的全部组合。您自己的数据可能看起来不太理想,但/ browse模板 可自定义。)
索引JSON
Solr支持索引JSON,任意结构化JSON或“Solr JSON”(类似于Solr XML)。
Solr包括一个小样本Solr JSON文件来说明这个功能。 再次使用bin / post,索引样本JSON文件:
bin/post -c gettingstarted example/exampledocs/books.json您会看到以下内容:
/solr-6.4.2:$ bin/post -c gettingstarted example/exampledocs/books.json
java -classpath /solr-6.4.2/dist/solr-core-6.4.2.jar -Dauto=yes -Dc=gettingstarted -Ddata=files org.apache.solr.util.SimplePostTool example/exampledocs/books.json
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/solr/gettingstarted/update...
Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
POSTing file books.json (application/json) to [base]/json/docs
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/solr/gettingstarted/update...
Time spent: 0:00:00.493有关索引Solr JSON的更多信息,请参阅“Solr参考指南”部分Solr-Style JSON
要展平(和/或拆分)和索引任意结构化JSON,本快速入门指南之外的主题,请查看Transforming and Indexing Custom JSON data(转换和索引自定义JSON数据)。
索引CSV(逗号/列分隔值)
到Solr的一个很大的数据通过CSV,特别是当文件是同类的所有具有相同的字段集。 CSV可以方便地从电子表格(如Excel)导出,或从数据库(如MySQL)导出。 当开始使用Solr时,通常最容易将结构化数据转换为CSV格式,然后将其索引到Solr,而不是更复杂的单步操作。
使用bin / post索引包含的示例CSV文件:
bin/post -c gettingstarted example/exampledocs/books.csv你会看到:
/solr-6.4.2:$ bin/post -c gettingstarted example/exampledocs/books.csv
java -classpath /solr-6.4.2/dist/solr-core-6.4.2.jar -Dauto=yes -Dc=gettingstarted -Ddata=files org.apache.solr.util.SimplePostTool example/exampledocs/books.csv
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/solr/gettingstarted/update...
Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
POSTing file books.csv (text/csv) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/solr/gettingstarted/update...
Time spent: 0:00:00.109有关详细信息,请参阅“Solr参考指南”一节“CSV格式化索引更新”
其他索引技术
使用数据导入处理程序(DIH)从数据库导入记录。
使用基于JVM的语言或其他Solr客户端的SolrJ以编程方式创建要发送到Solr的文档。
使用“管理UI文档”选项卡粘贴要编制索引的文档,或者从“文档类型”下拉列表中选择“文档生成器”,以便一次创建一个字段。 单击表单下方的提交文档按钮以索引文档。
更新数据
您可能会注意到,即使您不止一次将本指南中的内容编入索引,也不会重复找到的结果。这是因为示例schema.xml指定了一个名为“id”的“uniqueKey”字段。每当您向Solr发出命令以添加具有与现有文档uniqueKey相同的值的文档时,它会自动替换它。您可以通过查看Solr Admin UI的核心特定概述部分中numDocs和maxDoc的值来了解这一点。
numDocs表示索引中可搜索的文档数(并且将大于XML,JSON或CSV文件的数量,因为一些文件包含多个文档)。 maxDoc值可能较大,因为maxDoc计数包括尚未从索引中物理删除的逻辑删除的文档。你可以一次又多次重新发布样例文件,numDocs将永远不会增加,因为新文档将不断地替换旧的。
继续编辑任何现有的示例数据文件,更改一些数据,然后重新运行SimplePostTool命令。您将看到您的更改反映在后续搜索中。
删除数据
您可以通过向更新URL发出删除命令并指定文档的唯一键字段的值或匹配多个文档的查询(请小心使用该值)来删除数据。由于这些命令较小,我们直接在命令行上指定它们,而不是引用JSON或XML文件。
执行以下命令删除特定文档:
bin/post -c gettingstarted -d "<delete><id>SP2514N</id></delete>"搜索
Solr可以通过REST客户端,cURL,wget,Chrome POSTMAN等,以及通过可用于许多编程语言的本地客户端查询。
Solr管理UI包括查询构建器界面 - 请参阅http:// localhost:8983 / solr /#/ gettingstarted / query下的启动查询选项卡。
如果单击执行查询按钮而不更改窗体中的任何内容,您将获得10个JSON格式的文档(*:*在q param中匹配所有文档):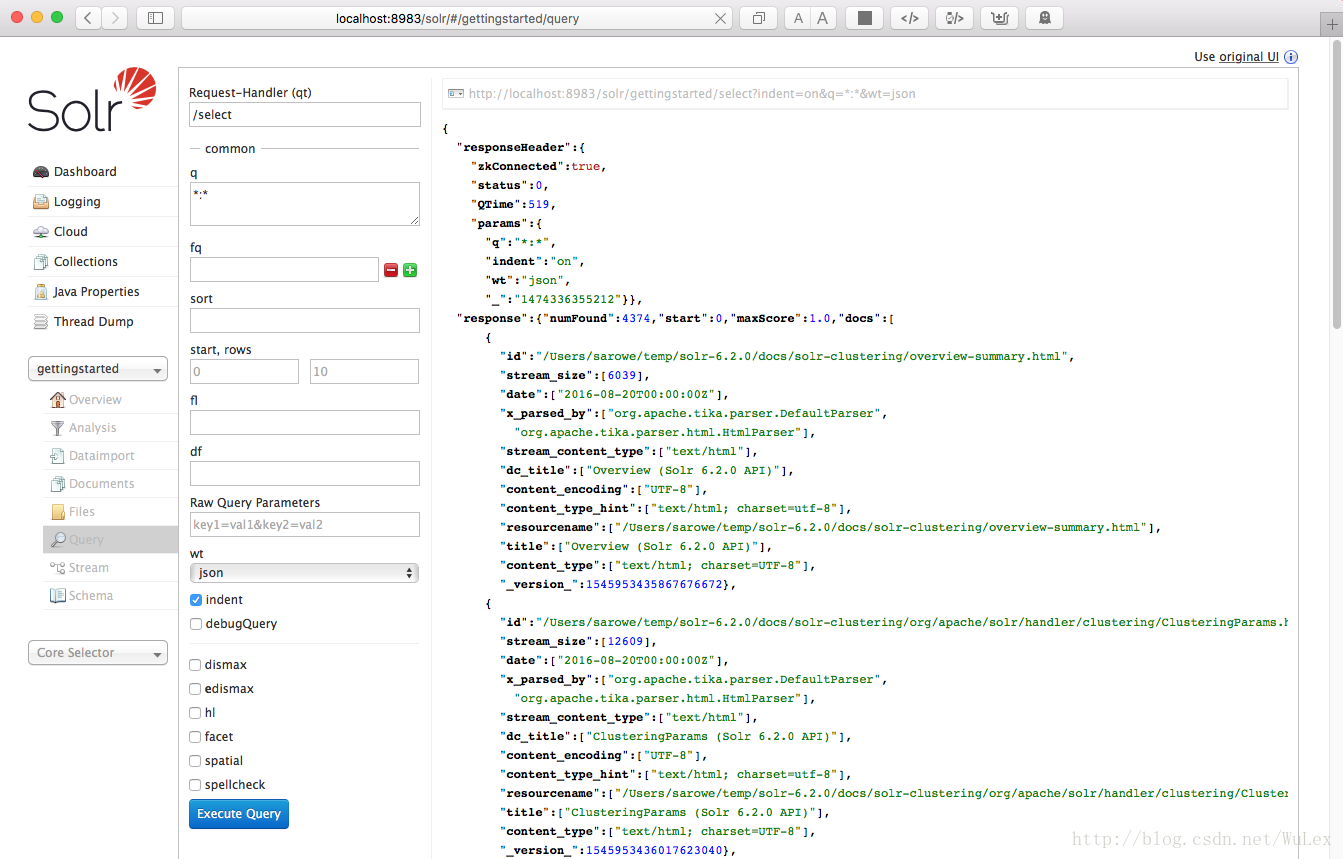
管理UI发送到Solr的URL在上面屏幕截图的右上角以浅灰色显示 - 如果您点击它,您的浏览器将显示原始响应。 要使用cURL,请在curl命令行上使用引号将相同的URL:
curl "http://localhost:8983/solr/gettingstarted/select?indent=on&q=*:*&wt=json"基本
搜索单个字词
要搜索一个术语,请在核心特定的Solr Admin UI查询部分中将其作为q param值,将:替换为您要查找的术语。 搜索“foundation”:
curl "http://localhost:8983/solr/gettingstarted/select?wt=json&indent=true&q=foundation"你会得到:
/solr-6.4.2$ curl "http://localhost:8983/solr/gettingstarted/select?wt=json&indent=true&q=foundation"
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":527,
"params":{
"q":"foundation",
"indent":"true",
"wt":"json"}},
"response":{"numFound":4156,"start":0,"maxScore":0.10203234,"docs":[
{
"id":"0553293354",
"cat":["book"],
"name":["Foundation"],
...响应指示有4,156次命中(“numFound”:4156),其中返回前10个,因为默认情况下start = 0和rows = 10。 您可以指定这些参数以遍历结果,其中start是要返回的第一个结果的(从零开始)位置,rows是页面大小。
要限制响应中返回的字段,请使用fl param,它使用逗号分隔的字段名称列表。 例如。 只返回id字段:
curl "http://localhost:8983/solr/gettingstarted/select?wt=json&indent=true&q=foundation&fl=id"q = foundation匹配几乎所有我们索引的文档,因为docs /下的大多数文件都包含“Apache软件基金会”。 要限制搜索到特定字段,请使用语法“q = field:value”,例如。 仅在名称字段中搜索Foundation:
curl "http://localhost:8983/solr/gettingstarted/select?wt=json&indent=true&q=name:Foundation"上述请求只从响应中返回一个文档 (“numFound”:1)
...
"response":{"numFound":1,"start":0,"maxScore":2.5902672,"docs":[
{
"id":"0553293354",
"cat":["book"],
"name":["Foundation"],
...短语搜索
要搜索多术语短语,请将其括在双引号中:q =“这里的多个术语”。 例如。 以搜索“CAS延迟” - 请注意,字词之间的空格必须在网址中转换为“+”(管理界面会自动处理网址编码):
curl "http://localhost:8983/solr/gettingstarted/select?wt=json&indent=true&q=\"CAS+latency\""响应:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":391,
"params":{
"q":"\"CAS latency\"",
"indent":"true",
"wt":"json"}},
"response":{"numFound":3,"start":0,"maxScore":22.027056,"docs":[
{
"id":"TWINX2048-3200PRO",
"name":["CORSAIR XMS 2GB (2 x 1GB) 184-Pin DDR SDRAM Unbuffered DDR 400 (PC 3200) Dual Channel Kit System Memory - Retail"],
"manu":["Corsair Microsystems Inc."],
"manu_id_s":"corsair",
"cat":["electronics", "memory"],
"features":["CAS latency 2, 2-3-3-6 timing, 2.75v, unbuffered, heat-spreader"],
...组合搜索
默认情况下,当您在单个查询中搜索多个术语和/或短语时,Solr只需要存在其中一个以便文档匹配。 包含更多术语的文档将在结果列表中排序较高。
您可以要求一个术语或短语的前缀为“+”; 相反,为了不允许存在术语或短语,以“ - ”作为前缀。
要查找包含“one”和“three”两个术语的文档,请在Admin UI Query选项卡的q param中输入+ one + three。 因为“+”字符在URL中具有保留用途(编码空格字符),所以必须将其针对curl的URL编码为“%2B”:
curl "http://localhost:8983/solr/gettingstarted/select?wt=json&indent=true&q=%2Bone+%2Bthree"搜索包含术语“two”但不包含术语“one”的文档,请在管理UI中的q param中输入+ two -one。 同样,网址将“+”编码为“%2B”:
curl "http://localhost:8983/solr/gettingstarted/select?wt=json&indent=true&q=%2Btwo+-one"深入
有关更多Solr搜索选项,请参阅“Solr参考指南”的“搜索”部分。
面部
Solr最受欢迎的功能之一是刻面。 Faceting允许将搜索结果排列成子集(或桶或类别),为每个子集提供计数。 有几种类型的faceting:字段值,数字和日期范围,枢轴(决策树)和任意查询分面。
场分面
除了提供搜索结果,Solr查询可以返回包含整个结果集中的每个唯一值的文档数。
从核心特定的管理界面查询选项卡,如果您选中“构面”复选框,您将看到一些与构面相关的选项:
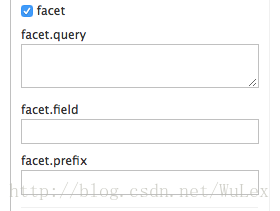
要查看所有文档中的构面计数(q = :):打开构面(facet = true),并通过facet.field参数指定要构面的字段。 如果只需要面,且没有文档内容,请指定rows = 0。 下面的curl命令将返回manu_id_s字段的构面计数:
curl 'http://localhost:8983/solr/gettingstarted/select?wt=json&indent=true&q=*:*&rows=0'\
'&facet=true&facet.field=manu_id_s'你将看到:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":201,
"params":{
"q":"*:*",
"facet.field":"manu_id_s",
"indent":"true",
"rows":"0",
"wt":"json",
"facet":"true"}},
"response":{"numFound":4374,"start":0,"maxScore":1.0,"docs":[]
},
"facet_counts":{
"facet_queries":{},
"facet_fields":{
"manu_id_s":[
"corsair",3,
"belkin",2,
"canon",2,
"apple",1,
"asus",1,
"ati",1,
"boa",1,
"dell",1,
"eu",1,
"maxtor",1,
"nor",1,
"uk",1,
"viewsonic",1,
"samsung",0]},
"facet_ranges":{},
"facet_intervals":{},
"facet_heatmaps":{}}}范围分面
对于数字或日期,通常希望将构面计数分割为范围而不是离散值。 使用示例产品数据的数值范围分面的主要例子是价格。 在/ browse UI中,它如下所示:

这些价格范围构面的数据可以使用此命令以JSON格式显示:
curl 'http://localhost:8983/solr/gettingstarted/select?q=*:*&wt=json&indent=on&rows=0'\
'&facet=true'\
'&facet.range=price'\
'&f.price.facet.range.start=0'\
'&f.price.facet.range.end=600'\
'&f.price.facet.range.gap=50'\
'&facet.range.other=after'你会得到:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":248,
"params":{
"facet.range":"price",
"q":"*:*",
"f.price.facet.range.start":"0",
"facet.range.other":"after",
"indent":"on",
"f.price.facet.range.gap":"50",
"rows":"0",
"wt":"json",
"facet":"true",
"f.price.facet.range.end":"600"}},
"response":{"numFound":4374,"start":0,"maxScore":1.0,"docs":[]
},
"facet_counts":{
"facet_queries":{},
"facet_fields":{},
"facet_ranges":{
"price":{
"counts":[
"0.0",19,
"50.0",1,
"100.0",0,
"150.0",2,
"200.0",0,
"250.0",1,
"300.0",1,
"350.0",2,
"400.0",0,
"450.0",1,
"500.0",0,
"550.0",0],
"gap":50.0,
"after":2,
"start":0.0,
"end":600.0}},
"facet_intervals":{},
"facet_heatmaps":{}}}数据透视面
另一种faceting类型是枢轴面,也称为“决策树”,允许为所有各种可能的组合嵌套两个或多个字段。 使用示例技术产品数据,枢轴面可以用于查看“书”类别(猫字段)中有多少产品库存或库存。 以下是获取此场景的原始数据的方法:
curl 'http://localhost:8983/solr/gettingstarted/select?q=*:*&rows=0&wt=json&indent=on'\
'&facet=on&facet.pivot=cat,inStock'这导致以下响应(仅修剪为书类别输出),其中说“书”类别中的14个项目,有12个库存和2个不存在:
...
"facet_pivot":{
"cat,inStock":[{
"field":"cat",
"value":"book",
"count":14,
"pivot":[{
"field":"inStock",
"value":true,
"count":12},
{
"field":"inStock",
"value":false,
"count":2}]},
...更多分面选项
有关Solr faceting的完整报告,请访问Solr Reference Guide的Faceting部分。
空间
Solr具有复杂的地理空间支持,包括在给定位置(或边界框内)的指定距离范围内进行搜索,按距离排序,或甚至通过距离提升结果。 example / exampledocs / *。xml中的一些示例tech产品文档具有与其相关联的位置,以说明空间能力。 要运行tech产品示例,请参阅techproducts示例部分。 空间查询可以与任何其他类型的查询相结合,例如在距离旧金山10公里内查询“ipod”的示例中:
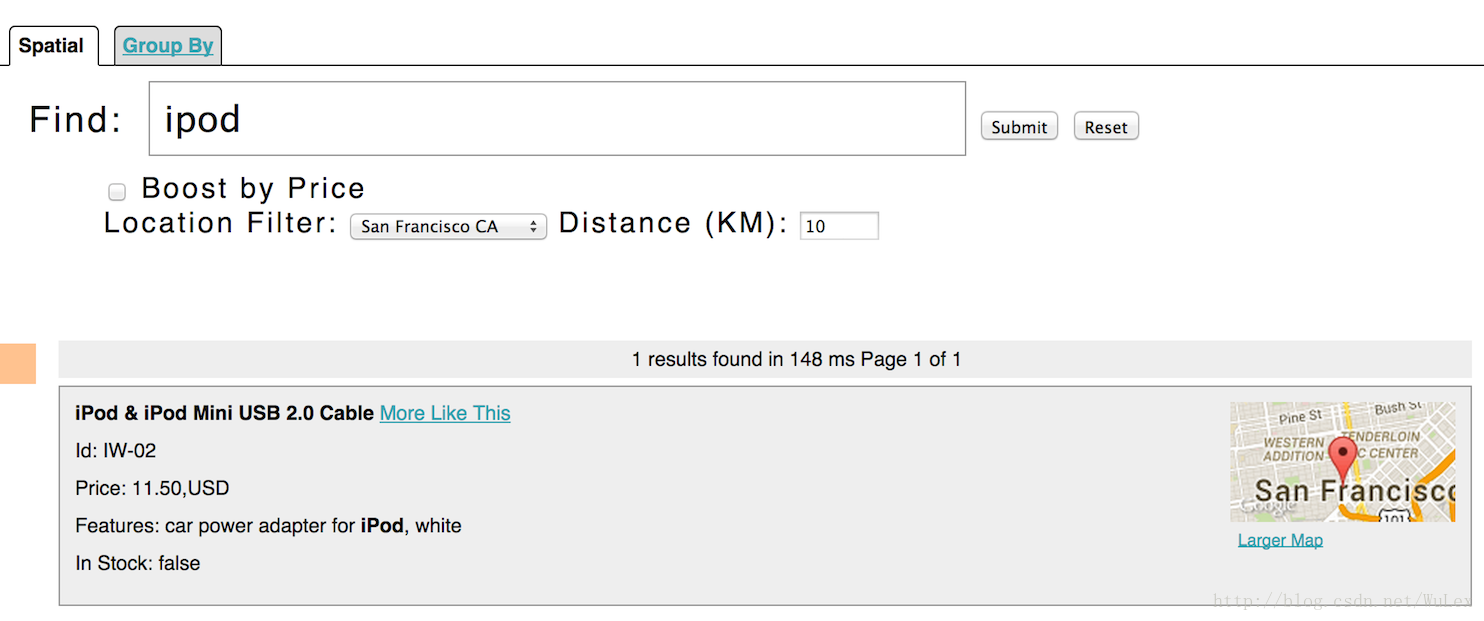
此示例的URL是
http://localhost:8983/solr/techproducts/browse?q=ipod&pt=37.7752%2C-122.4232&d=10&sfield=store&fq=%7B%21bbox%7D&queryOpts=spatial&queryOpts=spatial利用/ browse UI显示每个项目的地图,并允许轻松选择要在附近进行搜索的位置。
要了解有关Solr空间功能的更多信息,请参阅Solr参考指南的空间搜索部分。
包起来
如果您在本快速入门指南中运行完整的命令集,您已经完成以下操作:
将Solr启动为SolrCloud模式,两个节点,两个集合,包括碎片和副本
索引一个富文本文件的目录
索引的Solr XML文件
索引的Solr JSON文件
已索引的CSV内容
打开管理控制台,使用其查询界面获取JSON格式的结果
打开/浏览界面,在更友好和熟悉的界面中探索Solr的功能
尼斯工作!脚本(见下文)运行所有这些项目花了两分钟! (您的运行时间可能会有所不同,具体取决于您计算机的电源和可用资源。)
这里是一个Unix脚本,方便复制和粘贴,以运行本快速入门指南的关键命令:
date
bin/solr start -e cloud -noprompt
open http://localhost:8983/solr
bin/post -c gettingstarted docs/
open http://localhost:8983/solr/gettingstarted/browse
bin/post -c gettingstarted example/exampledocs/*.xml
bin/post -c gettingstarted example/exampledocs/books.json
bin/post -c gettingstarted example/exampledocs/books.csv
bin/post -c gettingstarted -d "<delete><id>SP2514N</id></delete>"
bin/solr healthcheck -c gettingstarted
date清理
在您完成本指南时,您可能希望停止Solr并将环境重置回起点。 以下命令行将停止Solr并删除启动脚本创建的两个节点中的每个节点的目录:
bin/solr stop -all ; rm -Rf example/cloud/













 486
486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









