







我们经常需要把两张表进行join操作。
在join时,我们对数据集是如何分区的一无所知。
默认情况下,会把两个数据集中所有键的哈希值都求出来,将该哈希值相同的记录通过网络传到同一台机器上,然后在那台机器上对所有键相同的记录进行连接。
当出现特殊情况时,比如两张表里某张表非常大,并且这张表里的数据又没有变化过。那么每一次join都会去求所有哈希值,浪费了不少时间,每一次求出的哈希值都是一样的。如下图。
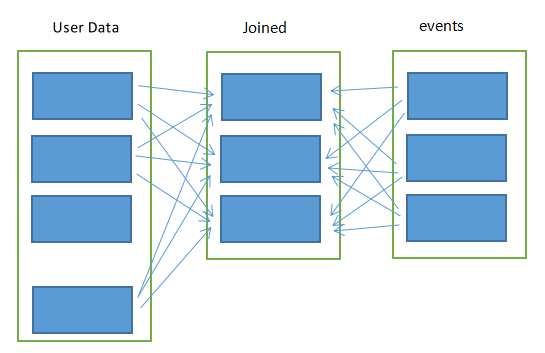
partitionBy()方法就是避免这种情况的。
可以在程序起始时就对userData表使用partitionBy()转化操作,将这张表转为哈希分区。
可以通过向partitionBy传递一个spark.HashPartitioner对象来实现该操作。
userData = sc.sequenceFile[UserID,UserInfo]("hdfs://...")
.partitionBy(new HashPartitioner(100)) //构造100个分区
.persist()将userData分区后,spark会自动利用这一点。
当调用userData.join(events)时,spark就只会对events数据进行混洗操作,将events中特定的userID的记录发送到userData的对应分区所在的那台机器上,这样可以大大减少网络传输以及计算量。
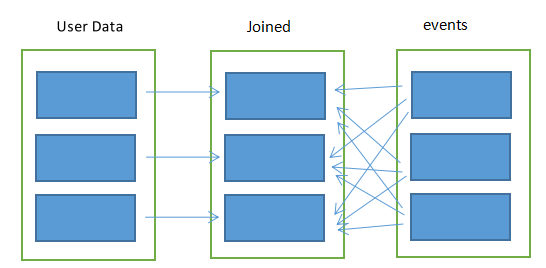
要注意的是,partitionBy()是一个转化操作。因此它的返回值总是一个新的RDD,但它不会改变原来的RDD。所以一定要对partitionBy的结果进行持久化。不然每一次jion它都会重新分区,得不偿失。















 7999
7999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









