







使用IDE调试一条简单的SQL
画出AST
画出Operator Tree
已有表结构:
hive> desc src;
OK
key int
value string 执行计划:
hive> explain select * from src a join src b on a.key=b.key where a.key<100;
OK
STAGE DEPENDENCIES:
Stage-4 is a root stage
Stage-3 depends on stages: Stage-4
Stage-0 depends on stages: Stage-3
STAGE PLANS:
Stage: Stage-4
Map Reduce Local Work
Alias -> Map Local Tables:
a
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
a
TableScan
alias: a
Statistics: Num rows: 55 Data size: 5812 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (key < 100) (type: boolean)
Statistics: Num rows: 18 Data size: 1902 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
keys:
0 key (type: int)
1 key (type: int)
Stage: Stage-3
Map Reduce
Map Operator Tree:
TableScan
alias: b
Statistics: Num rows: 55 Data size: 5812 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (key < 100) (type: boolean)
Statistics: Num rows: 18 Data size: 1902 Basic stats: COMPLETE Column stats: NONE
Map Join Operator
condition map:
Inner Join 0 to 1
keys:
0 key (type: int)
1 key (type: int)
outputColumnNames: _col0, _col1, _col5, _col6
Statistics: Num rows: 19 Data size: 2092 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), _col1 (type: string), _col5 (type: int), _col6 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3
Statistics: Num rows: 19 Data size: 2092 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 19 Data size: 2092 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Local Work:
Map Reduce Local Work
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSinkStage-4:是小表序列化
Stage-3:mr任务
Stage-0:对mr输出文件的输出
逻辑执行计划Stage-3
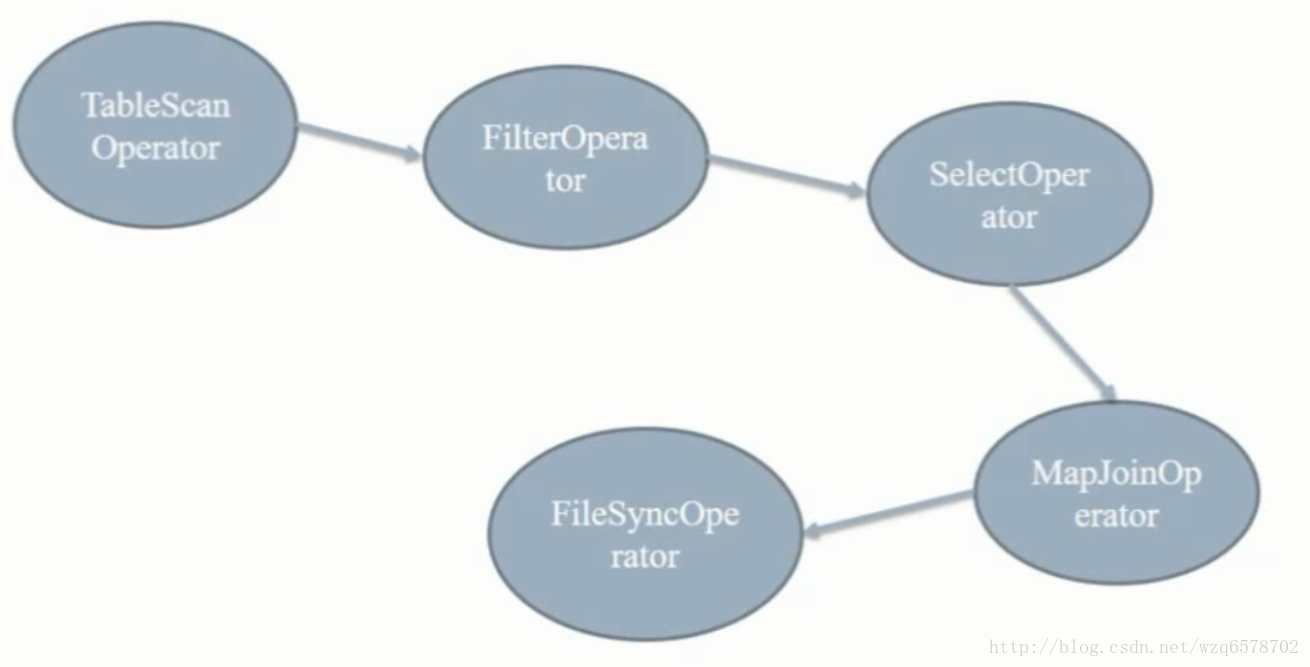
TableScanOperator: from src a /from src b 【a表加载进入内存,b在磁盘上边】
FilterOperator: where a.key<100
SelectOperator : select *
MapJoinOperator : on a.key = b.key
FileSyncOperator:输出
整个流程:从b表加载一条数据 FilterOperator一下,SelectOperator 选择出记录,用MapJoinOperator 和内存中的ajoin一下,然后输出
SerDe简介
SerDe是Serializer和Deserializer的缩写
序列化器与反序列化器
Hive使用SerDe接口去完成IO操作
接口三个主要功能:
序列化(Serialization),从Hive写FS
反序列化(Deserialization),从FS读入Hive
解释读写字段,加起文件到字段结构的桥梁
Hive核心三大组件
Hive有三大核心组件:
Query Processor:查询处理工具,源码ql包
SerDe:序列化与反序列化器,源码serde包
MetaStore:元数据存储及服务,源码metastore包
请注意:
HiveServer2、MR和Tez引擎并不是Hive的三大核心组件,只是周边,后续我们会做分析
关于MR和Tez的性能比较点这:http://www.cnblogs.com/linn/p/5325147.html
SerDe所处的位置
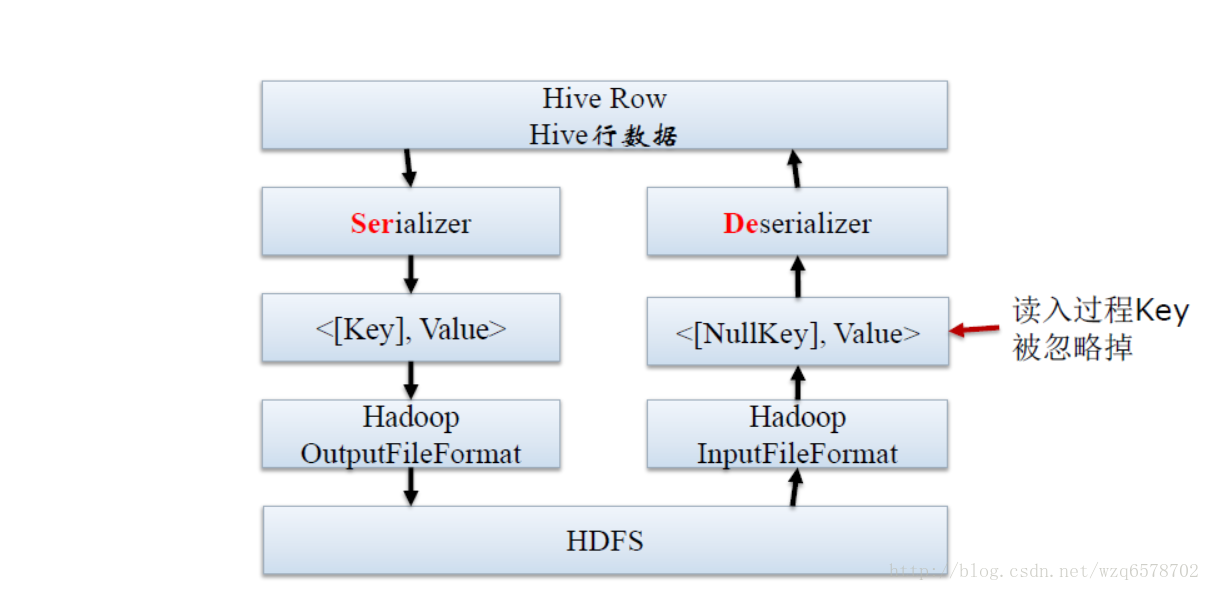
序列化和反序列化的目的
Serde是用于序列化和反序列化。
序列化的目的是Hive格式输出成为特定格式,包括:
分隔符(tab、逗号、CTRL-A)
Thrift 协议
反序列化的目的是HDFS格式读入Hive内存中,包括:
Java Integer/String/ArrayList/HashMap
Hadoop Writable 类
用户自定义类
内置SerDe与外置SerDe
内置SerDe
LazySimpleSerde
ColumnarSerde
AvroSerde
ORC
RegexSerde
Thrift
Parquet
CSV
JSONSerde
自定义Serde,读写自定义格式的数据
例子:使用RegexSerDe
分析http请求日志。
CREATE TABLE apache_log(
host STRING, identity STRING, user STRING,
time STRING, request STRING, status STRING,
size STRING, referer STRING, agent STRING)
ROW FORMAT SERDE ‘org.apache.hadoop.hive.contrib.serde2.RegexSerDe’
WITH SERDEPROPERTIES
( “input.regex” = “([^ ]) ([^ ]) ([^ ]) (-|\^\\]) ([^ \”]|\”[^\”]\”) (-|[0-9]) (-|[0-9])(?: ([^ \”]|\”[^\”]\”) ([^ \”]|\”[^\”]\”))?”,
“output.format.string” = “%1
s
s %3
s
s %5
s
s %7
s
s %9$s”
) STORED AS TEXTFILE;
( “input.regex” = “([^ ]) ([^ ]) ([^ ]) (-|\^\\]) ([^ \”]|\”[^\”]\”) (-|[0-9]) (-|[0-9])(?: ([^ \”]|\”[^\”]\”) ([^ \”]|\”[^\”]\”))?”
这个正则表达式是Serializer的过程,
( “input.regex” = “([^ ]) ([^ ]) ([^ ]) (-|\^\\]) ([^ \”]|\”[^\”]\”) (-|[0-9]) (-|[0-9])(?: ([^ \”]|\”[^\”]\”) ([^ \”]|\”[^\”]\”))?”
这条正则表达式是DeSerializer的过程。
SerDe的源码分析
相对于SemanticAnalyzer,Serde的编写较为规范,也较为好懂
https://www.codatlas.com/github.com/apache/hive/master/serde/src/java/org/apache/hadoop/hive/serde2/
AbstractSerde
https://www.codatlas.com/github.com/apache/hive/master/serde/src/java/org/apache/hadoop/hive/serde2/AbstractSerDe.java
AbstractSerde
serialize() 接口:Object -> Writable
deserialize()接口:Writable -> Object
/**
* Abstract class for implementing SerDe. The abstract class has been created, so that
* new methods can be added in the underlying interface, SerDe, and only implementations
* that need those methods overwrite it.
*/
public abstract class AbstractSerDe implements Deserializer, Serializer {
。。。。。。。。。。略
/**
* Initialize the HiveSerializer.
* @param conf System properties. Can be null in compile time
* @param tbl table properties
* @throws SerDeException
*/
//初始化
@Deprecated
public abstract void initialize(@Nullable Configuration conf, Properties tbl)
throws SerDeException;
。。。。。。略
/**
* Serialize an object by navigating inside the Object with the
* ObjectInspector. In most cases, the return value of this function will be
* constant since the function will reuse the Writable object. If the client
* wants to keep a copy of the Writable, the client needs to clone the
* returned value.
*/
//序列化操作,参数obj是hive中的对象,Writable 是hadoop中的数据格式描述抽象
public abstract Writable serialize(Object obj, ObjectInspector objInspector)
throws SerDeException;
。。。。。。。。。。略
/**
* Deserialize an object out of a Writable blob. In most cases, the return
* value of this function will be constant since the function will reuse the
* returned object. If the client wants to keep a copy of the object, the
* client needs to clone the returned value by calling
* ObjectInspectorUtils.getStandardObject().
*
* @param blob The Writable object containing a serialized object
* @return A Java object representing the contents in the blob.
*/
//反序列化 blob是hadoop中的数据抽象格式,返回的是Object是hive中的对象
public abstract Object deserialize(Writable blob) throws SerDeException;
..........略。。。。。。。@Public
@Stable
@SerDeSpec(schemaProps = {
serdeConstants.LIST_COLUMNS, serdeConstants.LIST_COLUMN_TYPES,
serdeConstants.FIELD_DELIM, serdeConstants.COLLECTION_DELIM, serdeConstants.MAPKEY_DELIM,
serdeConstants.SERIALIZATION_FORMAT, serdeConstants.SERIALIZATION_NULL_FORMAT,
serdeConstants.SERIALIZATION_ESCAPE_CRLF,
serdeConstants.SERIALIZATION_LAST_COLUMN_TAKES_REST,
serdeConstants.ESCAPE_CHAR,
serdeConstants.SERIALIZATION_ENCODING,
LazySerDeParameters.SERIALIZATION_EXTEND_NESTING_LEVELS,
LazySerDeParameters.SERIALIZATION_EXTEND_ADDITIONAL_NESTING_LEVELS
})
public class LazySimpleSerDe extends AbstractEncodingAwareSerDe {
。。。。。。。。略。。。。。如果我们想要改变存储在文件上的分隔符在哪个地方改动呢?打开serdeConstants这个类:
public static final String FIELD_DELIM = "field.delim";//字段域分隔符
public static final String COLLECTION_DELIM = "colelction.delim";//集合内部元素之间分隔符
public static final String MAPKEY_DELIM = "mapkey.delim";//map的key和value之间的分割符ObjectInspector
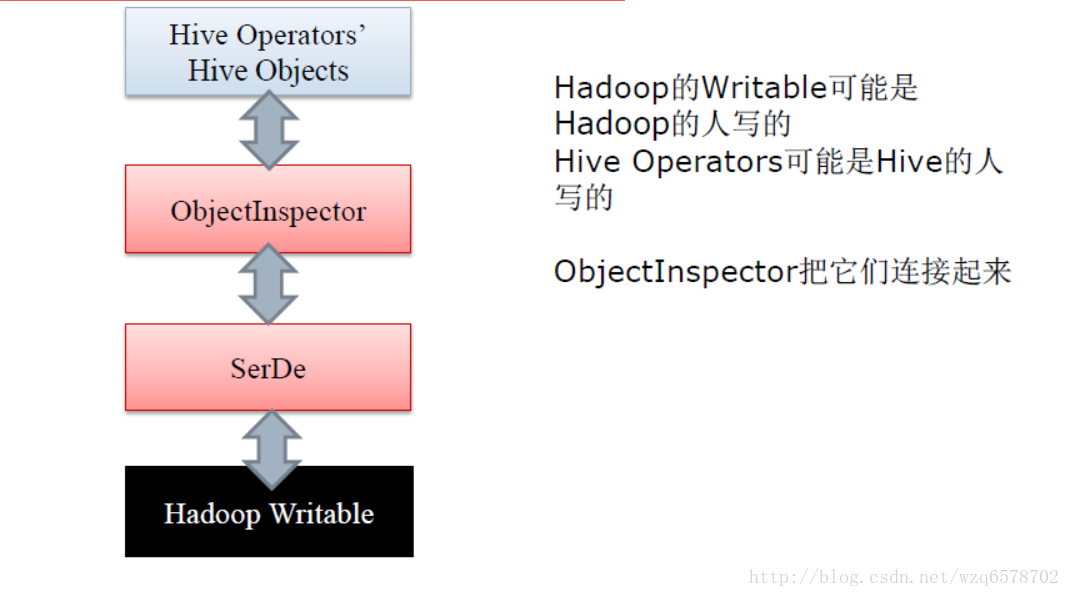
ObjectInspector作用相当大,它解耦了数据使用和数据格式
ObjectInspector接口使得Hive可以不拘泥于一种特定数据格式
在输入端和输出端切换不同的输入/输出格式
在不同的Operator上使用不同的数据格式
https://insight.io/github.com/apache/hive/blob/master/serde/src/java/org/apache/hadoop/hive/serde2/objectinspector/ObjectInspector.java
我们在上文的 explain select * from src a join src b on a.key=b.key where a.key<100;执行计划的时候,在stage-3有一个 Map Operator,这个操作是一个读操作,即反序列化Deserializer。
Deserializer是如何工作的
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/exec/MapOperator.java?line=125
value : hadoop中一条数据;context:hadoop的配置
private Object readRow(Writable value, ExecMapperContext context) throws SerDeException {
Object deserialized = deserializer.deserialize(value);
Object row = partTblObjectInspectorConverter.convert(deserialized);
if (hasVC()) {
rowWithPartAndVC[0] = row;
if (context != null) {
populateVirtualColumnValues(context, vcs, vcValues, deserializer);
}
int vcPos = isPartitioned() ? 2 : 1;
rowWithPartAndVC[vcPos] = vcValues;
return rowWithPartAndVC;
} else if (isPartitioned()) {
rowWithPart[0] = row;
return rowWithPart;
}
return row;
}Serializer是如何工作的
源码:https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/exec/ReduceSinkOperator.java?line=112
。。。。。。。。。。略
protected transient Serializer keySerializer;
protected transient boolean keyIsText;
protected transient Serializer valueSerializer;
。。。。。。。。。。。。。略
protected transient ObjectInspector keyObjectInspector;
protected transient ObjectInspector valueObjectInspector;我们在写数据的时候serialize(Object obj, ObjectInspector objInspector) obj是个什么对象我们是通过objInspector来描述的。
FileSinkOperator:
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/exec/FileSinkOperator.java?line=92
public class FileSinkOperator extends TerminalOperator<FileSinkDesc> implements
Serializable {
。。。。。。。。。略。。。。FileSinkDesc:
@Explain(displayName = "File Output Operator", explainLevels = { Level.USER, Level.DEFAULT, Level.EXTENDED })
public class FileSinkDesc extends AbstractOperatorDesc {ReduceSinkDesc原理也是如此:
@Explain(displayName = "Reduce Output Operator", explainLevels = { Level.USER, Level.DEFAULT, Level.EXTENDED })
public class ReduceSinkDesc extends AbstractOperatorDesc {在FileSinkDesc的注解@Explain中有个displayName=File Output Operator和我们之前的执行计划中的输出:
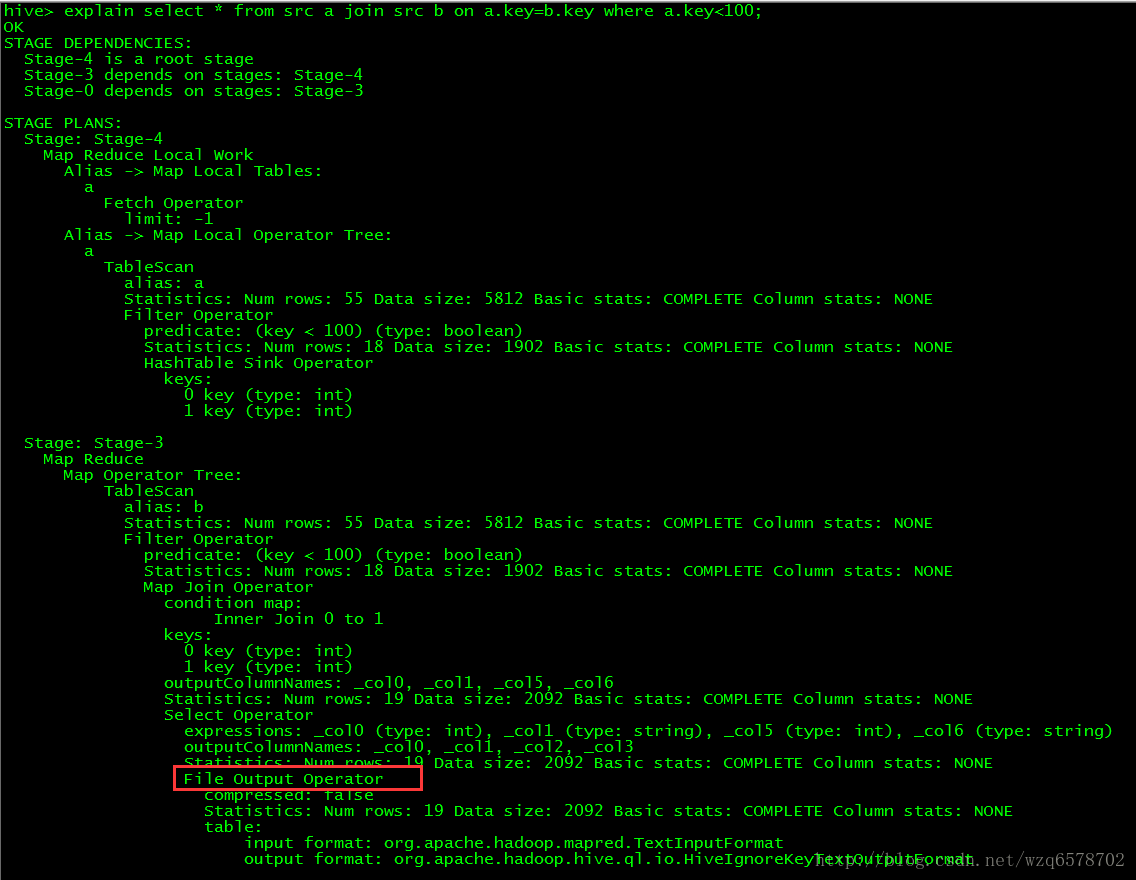
由此我们在根据执行bebug的时候就是根据类似于这种注解去判断的。
Hive的本质是一条SQL生成的一系列Operators,并执行它们 每个Operators的原理和适应条件,决定查询的性能 这里的代码是ReduceSinkOperator:
private BytesWritable makeValueWritable(Object row) throws Exception {
int length = valueEval.length;
// Evaluate the value
for (int i = 0; i < length; i++) {
cachedValues[i] = valueEval[i].evaluate(row);
}
// Serialize the value
return (BytesWritable) valueSerializer.serialize(cachedValues, valueObjectInspector);
}valueSerializer.serialize(cachedValues, valueObjectInspector);将row序列化最终为为BytesWritable【hadoop的数据类型】
ReduceSinkOperator的Sink是下沉的意思,此处是map的输出结果输入到reduce中,row是map的结果,输出是BytesWritable,即用BytesWritable作为reduce的输入。
由此可以看出,hive的主要功能是对一条sql解析生成若干operator,并且执行他们,和关系型数据库还有很大的不同的,关系型数据库还有存储 功能。
创建自定义Serde
参考:https://cwiki.apache.org/confluence/display/Hive/DeveloperGuide
何时添加自定义SerDe
用户有更有效的序列化磁盘数据的方法,添加Ser(不常出现)
用户的数据有特殊的序列化格式,当前的 Hive 不支持,而用户又不想在将数据加载至 Hive 前转换数据格式,添加De(经常出现)
Hive常用可编程用户接口文件格式FileFormats
序列化与反序列化器Serde
Map-Reduce脚本
UDxF(UDF, UDAF, UDTF)
创建自定义SerDe
大多数情况,只需要De而不是SerDe
只需要读取(反序列化)特殊格式的数据,而不是写(序列化)数据
读完之后用Hive内置的数据结构处理会更高效
创建自定义SerDe的过程
1.准备数据
2.使用IDE,继承AbstractSerde接口
3.实现serialize()和deserialize()方法
4.将创建的类打包为serde.jar
5.Add serde.jar 命令添加分布式缓存
6.建表,指定刚才编写的类
7.读写数据















 428
428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









