







1、hive sql报错Error: Error while compiling statement: FAILED: SemanticException UDF reflect is not allowed。
set hive.server2.builtin.udf.blacklist=empty_blacklist; set hive.server2.builtin.udf.blacklist; select t1.device_id, t1.appsflyer_id, t1.dt as server_date, t1.event_time, t1.platform, t1.device_model, t1.device_manufacturer, t1.app_version, t2.media_source, t2.install_time from ( – 每天 按事件时间 全量计算设备增加日期 select device_id, appsflyer_id, event_time, platform, device_model, device_manufacturer, app_version, dt from ( select device_id, appsflyer_id, event_time, platform, device_model, device_manufacturer, app_version, dt, row_number() over(partition by device_id order by event_time) rn from opay_dw.dwd_owallet_client_first_visit_base_di where dt <= ‘2021-04-12’ and device_id != ‘’ and platform != ‘h5’ ) tx where rn = 1 ) t1 left join ( – 设备关联渠道信息 SELECT appsflyer_id, media_source, app_name, install_time from ( SELECT appsflyer_id, media_source, app_name, install_time, row_number() over(PARTITION BY appsflyer_id ORDER BY install_time) rn from opay_dw.dwd_opay_tracker_appsflyer_di where dt<= if(‘2021-04-12’ <= ‘2020-11-30’, ‘2020-11-30’, ‘2021-04-12’) and event_name = ‘install’ and app_id=‘team.opay.pay’ ) t0 where rn = 1 ) t2 on nvl(t1.appsflyer_id, regexp_replace(reflect(“java.util.UUID”, “randomUUID”), “-”, “”)) = t2.appsflyer_id
在使用HiveServer2使用hive内置的UDF函数reflect 的时候,提示“semanticexception udf reflect is not allowed”,“reflect ”不允许被使用,默认情况下,HiveServer2为了安全,禁用了部分udf函数。
可以通过修改hive-site.xml,重启HiveServer2,即可生效(无法使用set进行修改)。
<property>
<name>hive.server2.builtin.udf.blacklist</name>
<value>empty_blacklist</value>
</property>
<property>
<name>hive.server2.builtin.udf.whitelist</name>
<value></value>
</property>
2、TEZ引擎一直卡主
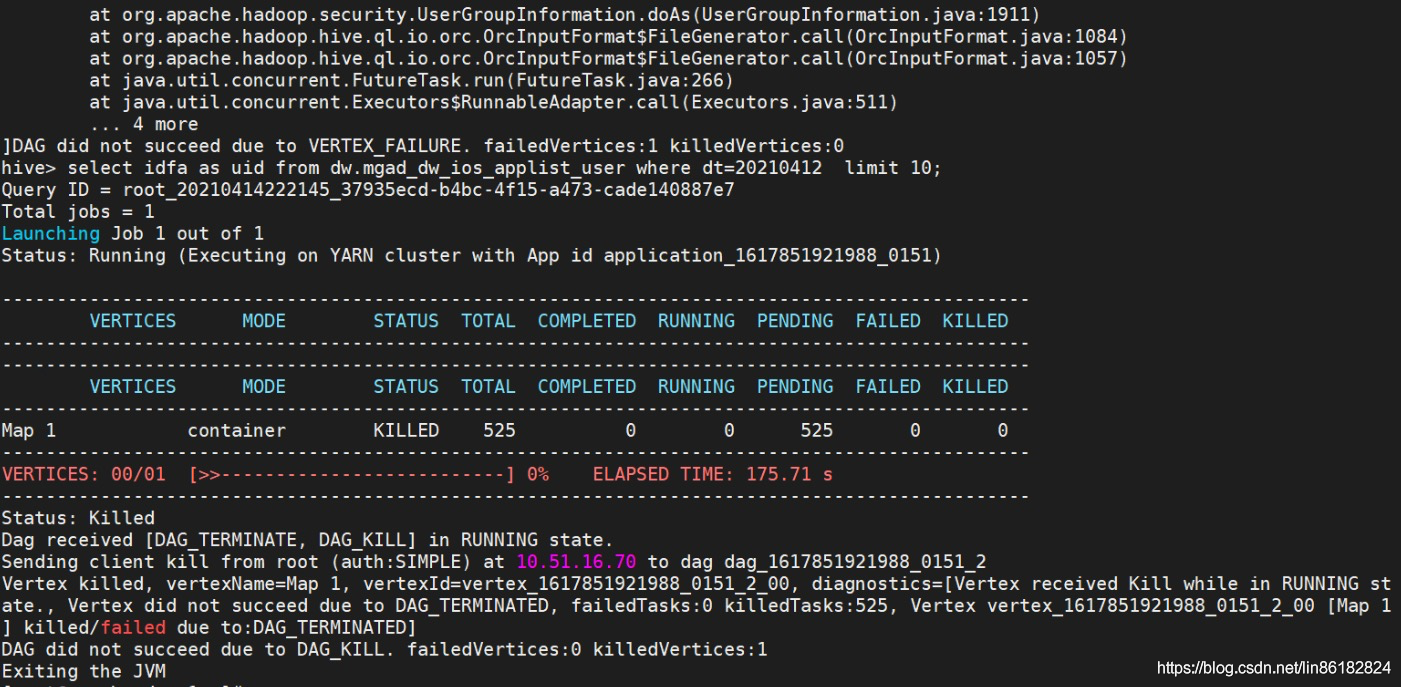
原因是:集群的 mapreduce.map.cpu.vcor
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1009
1009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









