








通常数据挖掘操作的数据集可以看作数据对象的集合。数据对象有时也叫做记录、点、向量、模式、事件、案例、样本、观测或实体。数据对象用一组刻画对象基本特征(如物体质量或事件发生的时间)的属性描述。属性有时也叫做变量、特性、字段、特征或维。而在数学上,向量和矩阵可以用来表示数据对象及其属性。
和其它数据挖掘语言或工具一样,MADlib操作的基本对象也是向量与矩阵。对向量和矩阵的操作是通过一系列函数完成的。本篇将介绍MADlib中向量的概念,并举出一些简单的函数调用示例。用户可以使用psql的联机帮助,查看函数的参数、返回值和函数体等信息,例如:\df madlib.array_add或\df+ madlib.array_add。我们将侧重于应用,因为理解这些函数的意义和用法是使用MADlib进行数据挖掘的基础。
一、向量定义
数学中的向量(vector,也称为欧几里得向量、几何向量、矢量),是一个具有大小(magnitude)和方向(direction)的值。它可以形象化地表示为带箭头的线段。箭头所指代表向量的方向,线段长度代表向量的大小。图1(a)给出了两个向量:向量u长度为1、平行于y轴,向量v长度为2、与x轴夹角为45º。
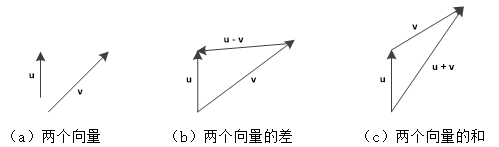
图1 两个向量以及它们的和与差
二、MADlib中的向量操作函数
在MADlib中,一维数组与向量具有相同的含义。MADlib的数组运算模块(array_ops)提供了一组用C实现的基本数组操作,是数据挖掘算法的支持模块。数组运算函数支持以下数字类型:
- SMALLINT
- INTEGER
- BIGINT
- REAL
- DOUBLE PRECISION(FLOAT8)
- NUMERIC(内部被转化为FLOAT8,可能丢失精度)
数组运算函数列表及功能描述如表1所示。
函数 | 描述 |
array_add() | 两个数组相加,需要所有值非空,返回与输入相同的数据类型。 |
sum() | 数组元素求和,需要所有值非空,返回与输入相同的数据类型。 |
array_sub() | 两个数组相减,需要所有值非空,返回与输入相同的数据类型。 |
array_mult() | 两个数组相乘,需要所有值非空,返回与输入相同的数据类型。 |
array_div() | 两个数组相除,需要所有值非空,返回与输入相同的数据类型。 |
array_dot() | 两个数组点积,需要所有值非空,返回与输入相同的数据类型。 |
array_contains() | 检查一个数组是否包含另一个数组。如果右边数组中的每个非零元素都等于左边数组中相同下标的元素,函数返回TRUE。 |
array_max() | 返回数组中的最大值,忽略空值,返回数组元素的相同类型。 |
array_max_index() | 返回数组中的最大值及其对应的下标,忽略空值,返回类型的格式为[max, index],其元素类型与输入类型相同。 |
array_min() | 返回数组中的最小值,忽略空值,返回数组元素的相同类型。 |
array_min_index() | 返回数组中的最小值及其对应的下标,忽略空值,返回类型的格式为[min, index],其元素类型与输入类型相同。 |
array_sum() | 返回数组中值的和,忽略空值,返回与输入相同的数据类型。 |
array_sum_big() | 返回数组中值的和,忽略空值,返回FLOAT8类型。该函数的意思是当汇总值可能超出元素类型范围时,替换array_sum()。 |
array_abs_sum() | 返回数组中绝对值的和,忽略空值,返回与输入相同的数据类型。 |
array_abs() | 返回由数组元素的绝对值组成的新数组,需要所有值非空。 |
array_mean() | 返回数组的均值,忽略空值。 |
array_stddev() | 返回数组的标准差,忽略空值。 |
array_of_float() | 创建元素个数为参数值的FLOAT8数组,初始值为0.0。 |
array_of_bigint() | 创建元素个数为参数值的BIGINT数组,初始值为0。 |
array_fill() | 将数组每个元素设置为参数值。 |
array_filter() | 过滤掉数组中的指定元素,要求所有值非空。返回与输入相同的数据类型。不指定被过滤元素时,该函数移除数组中的所有0值。 |
array_scalar_mult() | 数组与标量相乘,返回结果数组。需要所有值非空,返回与输入相同的数据类型。 |
array_scalar_add() | 数组与标量相加,返回结果数组。需要所有值非空,返回与输入相同的数据类型。 |
array_sqrt() | 返回由数组元素的平方根组成的数组,需要所有值非空。 |
array_pow() | 以数组和一个float8为输入,返回每个元素的乘幂(由第二个参数指定)组成的数组, 需要所有值非空。 |
array_square() | 返回由数组元素的平方组成的数组,需要所有值非空。 |
normalize() | 该函数规范化一个数组,使它的元素平方和为1。要求所有值非空。 |
表1 MADlib数组运算函数
下面用具体的例子说明函数的含义及用法。
(1)建立具有两个整型数组列array1和array2的数据库表并添加数据。
drop table if exists array_tbl;
create table array_tbl
( id integer, array1 integer[], array2 integer[] );
insert into array_tbl values
( 1, '{1,2,3,4,5,6,7,8,9}','{9,8,7,6,5,4,3,2,1}' ),
( 2, '{1,1,0,0,1,2,3,99,8}','{0,0,0,-5,4,1,1,7,6}'); (2)查询array1列的最小值及下标、最大值及下标、平均值和标准差。
select id, madlib.array_min(array1)min,
madlib.array_max(array1) max,
madlib.array_min_index(array1) min_idx,
madlib.array_max_index(array1) max_idx,
madlib.array_mean(array1) mean,
madlib.array_stddev(array1) stddev
from array_tbl; 结果:
id | min | max | min_idx | max_idx | mean | stddev
----+-----+-----+---------+---------+------------------+------------------
1 | 1 | 9 | {1,1} | {9,9} | 5 | 2.73861278752583
2 | 0 | 99 | {0,3} | {99,8} | 12.7777777777778 | 32.4259840936932
(2 rows)说明:
- MADlib的数组下标从1开始。
- 标准差的计算公式为:
,其中μ为平均值。
可以执行下面的查询验证标准差,结果同样是32.4259840936932。
select sqrt(sum(power(a-avg_a,2))/(count(*)-1))
from (select avg(a) avg_a
from (select unnest(array1) a from array_tbl where id=2) t) t1,
(select unnest(array1) a from array_tbl where id=2) t2;(3)执行数组加减运算。
select id,madlib.array_add(array1,array2),
madlib.array_sub(array1,array2)
from array_tbl;结果:
id | array_add | array_sub
----+------------------------------+-------------------------
1 | {10,10,10,10,10,10,10,10,10} | {-8,-6,-4,-2,0,2,4,6,8}
2 | {1,1,0,-5,5,3,4,106,14} | {1,1,0,5,-3,1,2,92,2}
(2 rows)与数的加法一样,向量的加法也具有一些我们熟知的性质。如果u、v和w是3个向量,则向量的加法具有如下性质。
- 向量加法的交换律。加的次序不影响结果:u + v =v + u。
- 向量加法的结合律。相加时向量分组不影响结果:(u +v) + w = u + (v + w)。
- 向量加法单位元存在性。存在一个零向量(zero vector),简记为0,是单位元。对于任意向量u,有u + 0 = u。
- 向量加法逆元的存在性。对于每个向量u,都存在一个逆向量-u,使得u + (-u) = 0。
(4)数组乘以一个标量。
select id, madlib.array_scalar_mult(array1,3), madlib.array_scalar_mult(array1,-3)
from array_tbl;结果:
id | array_scalar_mult | array_scalar_mult
----+---------------------------+------------------------------------
1 | {3,6,9,12,15,18,21,24,27} | {-3,-6,-9,-12,-15,-18,-21,-24,-27}
2 | {3,3,0,0,3,6,9,297,24} | {-3,-3,0,0,-3,-6,-9,-297,-24}
(2 rows)标量乘改变向量的量值,如果标量是正则方向不变,如果标量为负则方向相反。如果u和v是向量,α和β是标量(数),则向量的标量乘法具有如下性质。
- 标量乘法的结合律。被两个标量乘的次序不影响结果:α(βu)=(αβ)u。
select id,
madlib.array_scalar_mult(madlib.array_scalar_mult(array1,3),2),
madlib.array_scalar_mult(madlib.array_scalar_mult(array1,2),3)
from array_tbl;结果:
id | array_scalar_mult | array_scalar_mult
----+-----------------------------+-----------------------------
1 | {6,12,18,24,30,36,42,48,54} | {6,12,18,24,30,36,42,48,54}
2 | {6,6,0,0,6,12,18,594,48} | {6,6,0,0,6,12,18,594,48}
(2 rows)- 标量加法对标量与向量乘法的分配率。两个标量相加后乘以一个向量等于每个标量乘以该向量之后的结果向量相加:(α+β)u =αu + βu。
select id,
madlib.array_scalar_mult(array1,5),
madlib.array_add
(madlib.array_scalar_mult(array1,2),madlib.array_scalar_mult(array1,3))
from array_tbl;结果:
id | array_scalar_mult | array_add
----+-----------------------------+-----------------------------
1 | {5,10,15,20,25,30,35,40,45} | {5,10,15,20,25,30,35,40,45}
2 | {5,5,0,0,5,10,15,495,40} | {5,5,0,0,5,10,15,495,40}
(2 rows)- 标量乘法对向量加法的分配率。两个向量相加之后的和与一个标量相乘等于每个向量与该标量相乘然后相加:α(u + v) =αu +αv。
select id,
madlib.array_scalar_mult(madlib.array_add(array1, array2),3),
madlib.array_add
(madlib.array_scalar_mult(array1,3),madlib.array_scalar_mult(array2,3))
from array_tbl;结果:
id | array_scalar_mult | array_add
----+------------------------------+------------------------------
1 | {30,30,30,30,30,30,30,30,30} | {30,30,30,30,30,30,30,30,30}
2 | {3,3,0,-15,15,9,12,318,42} | {3,3,0,-15,15,9,12,318,42}
(2 rows)- 标量单位元的存在性。如果α = 1,则对于任何向量u,有αu = u。
由向量加法和标量与向量乘法引出了向量空间的概念。向量空间(vector space)是向量的集合,连同一个相关联的标量集(如实数集),满足上述性质,并且关于向量加法和标量与向量乘法是封闭的。封闭是指向量相加的结果、向量与标量相乘的结果都是原向量集中的向量。向量空间具有如下性质:任何向量都可以用一组称作基(basis)的向量线性组合(linear combination)表示。更明确地说,如果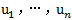
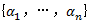
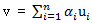
基向量通常是正交的(orthogonal)。向量正交是直线垂直的二维概念的推广。从概念上讲,正交向量是不相关的或独立的。如果基向量是相互正交的,则将向量表示成基向量的线性组合事实上把该向量分解成一些独立分量(independent component)。
因此,n维空间的向量可以看作标量(数)的n元组。为了具体地解释,考虑二维欧几里得空间,其中每个点都与一个表示该点到原点的位移的向量相关联。到任意点的位移向量都可以用x方向和y方向的位移和表示。这些位移分别是该点的x和y坐标。
我们使用记号
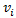
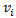
(5)数组乘除。这里过滤掉了id=2的行,否则查询会因为除零错误而失败。
select id,madlib.array_mult(array1,array2),
madlib.array_div(array1,array2)
from array_tbl
where 0 != all(array2);结果:
id | array_mult | array_div
----+----------------------------+---------------------
1 | {9,16,21,24,25,24,21,16,9} | {0,0,0,0,1,1,2,4,9}
(1 row)参与计算的两个数组都是整型,结果也是整型,因此除法运算的结果都被取整。与加法类似,数组乘除运算实际也就是向量分量上的乘除:
select array_agg(a * b), array_agg(a/b)
from (select unnest(array1) a, unnest(array2) b
from array_tbl where id=1) t;结果:
array_agg | array_agg
----------------------------+---------------------
{9,16,21,24,25,24,21,16,9} | {0,0,0,0,1,1,2,4,9}
(1 row)(6)计算数组点积。
select id, madlib.array_dot(array1,array2)
from array_tbl;结果:
id | array_dot
----+-----------
1 | 165
2 | 750
(2 rows) 两个向量u和v的点积u·v的定义为: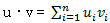
select sum(a * b)
from (select unnest(array1) a, unnest(array2) b
from array_tbl where id=2) t;由点积的定义,我们定义何谓两个向量正交。在欧式空间中,可以证明两个非零向量的点积为0当且仅当它们是垂直的。从几何角度,两个向量定义一个平面,并且它们的点积为0当且仅当这两个向量在平面内的夹角等于90 º。我们说这样的两个向量是正交的(orthogonal)。
(7)向量规范化
select madlib.normalize(array1) from array_tbl;结果:
normalize
-------------------------------------------------------------------------------------------------------------------------
---------------------------------------------
{0.0592348877759092,0.118469775551818,0.177704663327728,0.236939551103637,0.296174438879546,0.355409326655455,0.41464421
4431365,0.473879102207274,0.533113989983183}
{0.0100600363590491,0.0100600363590491,0,0,0.0100600363590491,0.0201200727180982,0.0301801090771473,0.995943599545862,0.
0804802908723929}
(2 rows) 点积也可以用来计算欧式空间中的向量长度: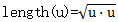
select madlib.array_scalar_mult
(array1::float[],1/sqrt(madlib.array_dot(array1, array1)))
from array_tbl;并且可以使用下面的查询验证范数为1:
select id,sum(a)
from (select id,power(unnest(madlib.normalize(array1)),2) a from array_tbl) t
group by id;给定向量范数,向量的点积也可以写成:
u·v = ‖u‖‖v‖cos(θ)
其中,θ是两个向量之间的夹角。把项分组并重新排列,上式可以改写成:
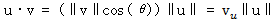
其中,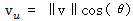
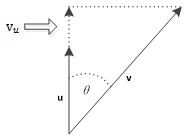
图2 向量v在向量u方向的正交投影
一个与正交性密切相关的概念是线性独立性(linear independent)。如果一个向量集中的每个向量都不能表示成该集合中其它向量的线性组合,则该集合是线性独立的。如果一个向量集不是线性独立的,则它们是线性依赖的(linearly dependent)。我们希望基中每个向量都不线性依赖于其余的基向量。如果选择相互正交(独立的)基向量,则我们自动得到一个线性独立的基向量集,因为任意两个向量都正交的向量集是线性独立的。
(8)构造一个9个元素的数组,数组元素的值设为1.3。
select madlib.array_fill(madlib.array_of_float(9), 1.3::float);结果:
array_fill
---------------------------------------
{1.3,1.3,1.3,1.3,1.3,1.3,1.3,1.3,1.3}
(1 row)array_of_float函数构造一个9个元素的数组,初始值为0,array_fill填充数组元素值。array_fill函数中第一个参数的数组元素数据类型需要与第二个参数的数据类型相同。
(9)过滤掉数组中的指定元素
select madlib.array_filter(array1),
madlib.array_filter(array1,2),
madlib.array_filter(array1,20)
from array_tbl;结果:
array_filter | array_filter | array_filter
---------------------+--------------------+----------------------
{1,2,3,4,5,6,7,8,9} | {1,3,4,5,6,7,8,9} | {1,2,3,4,5,6,7,8,9}
{1,1,1,2,3,99,8} | {1,1,0,0,1,3,99,8} | {1,1,0,0,1,2,3,99,8}
(2 rows)在没有给出第二个参数的情况下,madlib.array_filter函数缺省过滤掉数组中的0元素,如果给出了第二个元素,则从第一个参数指定的数组中过滤掉该值。如果值在数组中不存在,则结果返回原数组。
(10)将二维数组列展开为一维数组集合。
array_unnest_2d_to_1d是madlib 1.11版本的新增的函数,用于将二维数组展开为一维数组。1.10版本并无次函数,但可以创建一个UDF实现。
create or replace function madlib.array_unnest_2d_to_1d(anyarray)
returns table(unnest_row_id int,unnest_result anyarray) as
$func$
select d1,array_agg(val)
from (select $1[d1][d2] val,d1,d2
from generate_series(array_lower($1,1), array_upper($1,1)) d1,
generate_series(array_lower($1,2), array_upper($1,2)) d2
order by d1,d2) t
group by d1
$func$ language sql immutable;之后就可以调用函数展开二维数组:
select id,(madlib.array_unnest_2d_to_1d(val)).*
from (select 1::int as id,
array[[1.3,2.0,3.2],[10.3,20.0,32.2]]::float8[][] as val
union all
select 2,
array[[pi(),pi()/2],[2*pi(),pi()],[pi()/4,4*pi()]]::float8[][])t
order by 1,2;结果:
id | unnest_row_id | unnest_result
----+---------------+--------------------------------------
1 | 1 | {1.3,2,3.2}
1 | 2 | {10.3,20,32.2}
2 | 1 | {3.14159265358979,1.5707963267949}
2 | 2 | {6.28318530717959,3.14159265358979}
2 | 3 | {0.785398163397448,12.5663706143592}
(5 rows)三、稀疏向量
有些数据集,如具有非对称特征的数据集,一个对象的大部分属性上的值都为0,在许多情况下,非零项还不到1%。实际上,稀疏性(sparsity)是一个优点,因为只有非零值才需要存储和处理。这将节省大量的计算时间和存储空间。此外,有些数据挖掘算法仅适合处理稀疏数据。
1. MADlib的稀疏向量
MADlib的svec模块,实现了一种稀疏向量数据类型,能够为包含大量重复元素的向量提供压缩存储。浮点数组进行各种计算,有时会有很多的零或其它缺省值,在科学计算、零售优化、文本处理等应用中,这是很常见的。每个浮点数在内存或磁盘中占用8字节,节省多个零值的存储空间通常是有益的,而且,跳过零值对于很多向量计算也会提升性能。
MADlib1.10版本仅支持float8稀疏向量类型,例如有如下float8[]数据类型的数组:
'{0, 33,...40000个0..., 12, 22 }'::float8[]这个数组会占用320KB的内存或磁盘,而其中绝大部分存储的是0值。即使我们利用null位图,将0作为null存储,还是会得到一个5KB(40000/8)的null位图,内存使用效率还是不够高。何况在执行数组操作时,40000个零列上的计算结果并不重要。为了解决这个向量存储问题,svec类型使用行程长度编码(Run Length Encoding,RLE),即用一个数-值对数组表示稀疏向量。上面的数组以这种方式被存储为:
'{1,1,40000,1,1}:{0,33,0,12,22}'::madlib.svec就是说1个0、1个33、40000个0等等,只使用5个整型和5个浮点数类型构成数组存储。除了节省空间,这种RLE表示也很容易实现向量操作,并使向量计算更快。svec模块提供了稀疏向量数据类型相关的函数库。
2. 创建稀疏向量
有以下四种方式可以创建稀疏向量。
(1)直接使用常量表达式构建一个svec。
select'{n1,n2,...,nk}:{v1,v2,...vk}'::madlib.svec;其中n1、n2、...、nk分别指定值v1、v2、...、vk的个数,例如:
dm=# select'{1,3,5}:{2,4,6}'::madlib.svec;
svec
-----------------
{1,3,5}:{2,4,6}
(1 row)(2)将一个float数组转换成svec。
select('{v1,v2,...vk}'::float[])::madlib.svec;例如:
dm=# select ('{2,4,4,4,6,6,6,6,6}'::float[])::madlib.svec;
svec
-----------------
{1,3,5}:{2,4,6}
(1 row)(3)使用聚合函数创建一个svec,例如:
svec_agg
----------------------------------------------
{1,1,1,1,1,1,1,1,1,1}:{1,2,3,4,5,6,7,8,9,10}
(1 row)(4)利用madlib.svec_cast_positions_float8arr()函数创建svec,例如:
dm=# select madlib.svec_cast_positions_float8arr(array[1,3,5], array[2,4,6], 10, 0.0);
svec_cast_positions_float8arr
-------------------------------
{1,1,1,1,1,5}:{2,0,4,0,6,0}
(1 row)此查询语句的含义是,生成一个10个元素的svec向量,其中1、3、5位置上的值分别是2、4、6,其它位置的值为0。svec模块的svec_cast_positions_float8arr函数提供了从给定的位置数组和值数组声明一个稀疏向量的功能。下面再看一个例子:
dm=# select madlib.svec_cast_positions_float8arr(
dm(# array[1,2,7,5,87],array[.1,.2,.7,.5,.87],90,0.0);
svec_cast_positions_float8arr
-----------------------------------------------------
{1,1,2,1,1,1,79,1,3}:{0.1,0.2,0,0.5,0,0.7,0,0.87,0}
(1 row)第一个整数数组表示第二个浮点数数组的位置,即结果数组的第1、2、5、7、87下标对应的值分别为0.1、0.2、0.5、0.7、0.87。位置本身不需要有序,但要和值的顺序保持一致。第三个参数表示数组的最大维数。小于1最大维度将被忽略,此时数组的最大维度就是位置数组中的最大下标。最后的参数表示没有提供下标的位置上的值。
3. 稀疏向量示例
(1)简单示例
对svec类型可以应用<、>、*、**、/、=、+、SUM等操作和运算,并且具有典型的向量操作的相关含义。例如,加法(+)操作是对两个向量中相同下标对应的元素进行相加。为了使用svec模块中定义的运算符,需要将madlib模式添加到search_path中。
dm=# -- 将madlib模式添加到搜索路径中
dm=# set search_path="$user",public,madlib;
SET
dm=# -- 稀疏向量相加
dm=# select ('{0,1,5}'::float8[]::madlib.svec
dm(# + '{4,3,2}'::float8[]::madlib.svec)::float8[];
float8
---------
{4,4,7}
(1 row)如果最后不转换成float8[],结果是一个svec类型:
dm=# select('{0,1,5}'::float8[]::madlib.svec
dm(# + '{4,3,2}'::float8[]::madlib.svec);
?column?
-------------
{2,1}:{4,7}
(1 row)两个向量的点积(%*%)结果是float8类型,如(0*4+ 1*3 + 5*2) = 13:
dm=# select'{0,1,5}'::float8[]::madlib.svec
dm-# %*% '{4,3,2}'::float8[]::madlib.svec;
?column?
----------
13
(1 row)有些聚合函数对svec也是可用的,如svec_count_nonzero。
drop table if exists list;
create table list (a madlib.svec);
insert into list values
('{0,1,5}'::float8[]::madlib.svec),('{10,0,3}'::float8[]::madlib.svec),
('{0,0,3}'::float8[]::madlib.svec),('{0,1,0}'::float8[]::madlib.svec);svec_count_nonzero函数统计svec中每一列非0元素的个数,返回计数的svec。
dm=# select madlib.svec_count_nonzero(a)::float8[] from list;
svec_count_nonzero
--------------------
{1,2,3}
(1 row)svec数据类型中不应该使用NULL,因为NULL会显式表示为NVP(No Value Present)。
dm=# select'{1,2,3}:{4,null,5}'::madlib.svec;
svec
-------------------
{1,2,3}:{4,NVP,5}
(1 row)含有NULL的svec相加,结果中显示NVP。
dm=# select'{1,2,3}:{4,null,5}'::madlib.svec
dm-# + '{2,2,2}:{8,9,10}'::madlib.svec;
?column?
--------------------------
{1,2,1,2}:{12,NVP,14,15}
(1 row)可以使用svec_proj()函数访问svec元素,该函数的参数为一个svec和一个元素下标。
dm=# select madlib.svec_proj('{1,2,3}:{4,5,6}'::madlib.svec, 1)
dm-# + madlib.svec_proj('{4,5,6}:{1,2,3}'::madlib.svec, 15);
?column?
----------
7
(1 row)通过svec_subvec()函数可以访问一个svec的子向量,该函数的参数为一个svec,及其起止下标。
dm=# select madlib.svec_subvec('{2,4,6}:{1,3,5}'::madlib.svec, 2, 11);
svec_subvec
-----------------
{1,4,5}:{1,3,5}
(1 row)svec的元素/子向量可以通过svec_change()函数进行改变。该函数有三个参数:一个m维的svec sv1,起始下标j,一个n维的svec sv2,其中j + n- 1 <= m,返回类似sv1的svec,但子向量sv1[j:j+n-1]被sv2所替换。
dm=# select madlib.svec_change('{1,2,3}:{4,5,6}'
dm(# ::madlib.svec,3,'{2}:{3}'::madlib.svec);
svec_change
---------------------
{1,1,2,2}:{4,5,3,6}
(1 row)还有处理svec的高阶函数,如svec_lapply对应r语言中的lapply()函数。这里的所谓高阶函数,可以简单理解为函数(svec_lapply)的参数是函数名(sqrt)。
dm=# select madlib.svec_lapply('sqrt','{1,2,3}:{4,5,6}'::madlib.svec);
svec_lapply
-----------------------------------------------
{1,2,3}:{2,2.23606797749979,2.44948974278318}
(1 row)(2)扩展示例
下面的示例是稀疏向量的一个具体应用,说明如何将文档转化为稀疏向量,并进一步对文档归类。假设有一个由若干单词组成的文本数组:
drop table if exists features;
create table features (a text[]);
insert into features values
('{am,before,being,bothered,corpus,document,i,in,is,me,
never,now,one,really,second,the,third,this,until}');同时有一个文档集合,每个文档表示为一个单词数组:
drop table if exists documents;
create table documents(a int,b text[]);
insert into documents values
(1,'{this,is,one,document,in,the,corpus}'),
(2,'{i,am,the,second,document,in,the,corpus}'),
(3,'{being,third,never,really,bothered,me,until,now}'),
(4,'{the,document,before,me,is,the,third,document}');如果忽略文档中词的顺序,则文档可以用词向量表示,其中每个词是向量的一个分量(属性),而每个分量的值对应词在文档中出现的次数。文档集合的这种表示通常称作文档-词矩阵(document-term matrix)文档是该矩阵的行,而词是矩阵的列。实践应用时,仅存放稀疏数据矩阵的非零项。
现在有了字典和文档,我们要对每个文档中的出现单词的数量和比例应用向量运算,将文档进行分类。在开始处理前,需要找到每个文档中出现的字典中的单词。我们为每个文档创建一个稀疏特征向量(Sparse Feature Vector,SFV)。SFV是一个N维向量,N是字典单词的数量,SFV中的每个元素是文档中对每个字典单词的计数。svec模块中有一个函数可以从文档创建SFV:
dm=# select madlib.svec_sfv((select a from features limit 1),b)::float8[]
dm-# from documents;
svec_sfv
-----------------------------------------
{0,0,0,0,1,1,0,1,1,0,0,0,1,0,0,1,0,1,0}
{1,0,0,0,1,1,1,1,0,0,0,0,0,0,1,2,0,0,0}
{0,0,1,1,0,0,0,0,0,1,1,1,0,1,0,0,1,0,1}
{0,1,0,0,0,2,0,0,1,1,0,0,0,0,0,2,1,0,0}
(4 rows)注意,madlib.svec_sfv()函数的输出是每个文档一个向量,元素值是相应字典顺序位置上单词在文档中出现的次数。通过对比特征向量和文档,更容易地理解这一点:
dm=# select madlib.svec_sfv((select a from features),b)::float8[], b
dm-# from documents;
svec_sfv | b
-----------------------------------------+--------------------------------------------------
{0,0,0,0,1,1,0,1,1,0,0,0,1,0,0,1,0,1,0} | {this,is,one,document,in,the,corpus}
{1,0,0,0,1,1,1,1,0,0,0,0,0,0,1,2,0,0,0} | {i,am,the,second,document,in,the,corpus}
{0,0,1,1,0,0,0,0,0,1,1,1,0,1,0,0,1,0,1} | {being,third,never,really,bothered,me,until,now}
{0,1,0,0,0,2,0,0,1,1,0,0,0,0,0,2,1,0,0} | {the,document,before,me,is,the,third,document}
(4 rows)可以看到文档"i am the second document in the corpus",它的SFV为{1,3*0,1,1,1,1,6*0,1,2,3*0}。单词“am”是字典中的第一个单词,并且在文档中只出现一次。单词“before”没有出现在文档中,所以它的值为0,以此类推。函数madlib.svec_sfv()能够将大量文档高速并行转换为对应的SFV。
分类处理的其余部分都是向量运算。实际应用中很少使用实际计数值,而是将计数转为权重。最普通的权重叫做tf/idf,对应术语是Term Frequency / InverseDocument Frequency即词频-逆文件频率。对给定文档中给定单词的权重计算公式为:
{#Times in document} * log {#Documents /#Documents the term appears in} 例如,单词“document”在文档A中的权重为1* log (4/3),而在文档D中的权重为2 * log(4/3)。在每个文档中都出现的单词的权重为0,因为log(4/4)= log(1) = 0,而仅出现在一个文档中的词具有最大权重log(文档数量)。TF-IDF是一种统计方法,用以评估一个词对于一个文件集或一个语料库中的其中一个文档重要程度。词的重要性随着它在文档中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。简单说就是,一个词在一篇文档中出现次数越多, 同时在所有文档中出现次数越少, 越能够代表该文章。
对于这部分处理,我们需要一个具有字典维数(19)的稀疏向量,元素值为:
log(#documents/#Documents each term appearsin)整个文档列表对应单一上述向量。#documents是文档总数,本例中是4,但对于每个字典单词都对应一个分母,其值为出现该单词的文档数。这个向量再乘以每个文档SFV中的计数,结果即为tf/idf权重。
drop table if exists corpus;
create table corpus
as (select a, madlib.svec_sfv((select a from features),b) sfv
from documents);
drop table if exists weights;
create table weights
as (select a docnum, madlib.svec_mult(sfv,logidf) tf_idf
from (select madlib.svec_log(madlib.svec_div(
count(sfv)::madlib.svec,
madlib.svec_count_nonzero(sfv))) logidf
from corpus) foo, corpus order by docnum); 查询权重:
dm=# select * from weights;
docnum | tf_idf
--------+----------------------------------------------------------------------------------------------------------------
------------------------------------------
1 | {4,1,1,1,2,3,1,2,1,1,1,1}:{0,0.693147180559945,0.287682072451781,0,0.693147180559945,0,1.38629436111989,0,0.287
682072451781,0,1.38629436111989,0}
2 | {1,3,1,1,1,1,6,1,1,3}:{1.38629436111989,0,0.693147180559945,0.287682072451781,1.38629436111989,0.69314718055994
5,0,1.38629436111989,0.575364144903562,0}
3 | {2,2,5,1,2,1,1,2,1,1,1}:{0,1.38629436111989,0,0.693147180559945,1.38629436111989,0,1.38629436111989,0,0.6931471
80559945,0,1.38629436111989}
4 | {1,1,3,1,2,2,5,1,1,2}:{0,1.38629436111989,0,0.575364144903562,0,0.693147180559945,0,0.575364144903562,0.6931471
80559945,0}
(4 rows)尽管文档具有具有数以百千计或数以万计的属性(词),但是每个文档向量都是稀疏的,因为它具有相对较少的非零属性值。这样,相似性不能依赖共享0的个数,因为任意两个文档多半不会包含许多相同的词,从而如果统计0-0匹配,则大多数文档都与其它大部分文档非常类似。因此文档的相似性度量需要忽略0-0匹配,而且还必须能处理非二元向量。下面定义的余弦相似度(cosinesimilarity)就是文档相似性最常用的度量之一。如果x和y是两个文档向量,则:
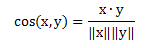
现在就可以使用文档向量的点积的ACOS,获得一个文档与其它文档的“角距离”。下面计算第一个文档与其它文档的角距离:
dm=# select docnum, 180. *
dm-# (acos(madlib.svec_dmin(1., madlib.svec_dot(tf_idf, testdoc)
dm(# / (madlib.svec_l2norm(tf_idf)
dm(# * madlib.svec_l2norm(testdoc))))/3.141592654) angular_distance
dm-# from weights,
dm-# (select tf_idf testdoc from weights where docnum = 1 limit 1) foo
dm-# order by 1;
docnum | angular_distance
--------+------------------
1 | 0
2 | 78.8235846096986
3 | 89.9999999882484
4 | 80.0232034288617
(4 rows)可以看到文档1与自己的角距离为0度,而文档1与文档3的角距离为90度,因为它们之间没有任何相同的单词。
四、向量与数据分析
尽管最初引进向量是为了处理力、速度、加速度这样的量,但是实践证明它们也能用来表示和理解许多其它类型的数据。特别是,我们常常把一个数据对象或属性看作向量。例如,文档可以用向量表示,其中每个分量对应一个词,而每个分量的值是该词在文档中出现的次数。这会产生非常稀疏、高维的向量。这里,稀疏是指向量的大部分分量为0。
一旦我们用向量表示数据对象,我们就可以在数据上执行各种向量计算。例如,我们可以计算两个向量的余弦相似度或距离。这种相似性度量不考虑向量的量值(长度),而只考虑两个向量在相同方向的程度。就文档而言,这意味如果两个文档以相同的比例包含相同词,则它们相同。两个文档中都不出现的词在计算相似性时不起作用。
我们还可以简单地定义两个向量(点)之间的距离。如果u和v是向量,则这两个向量(点)之间的欧几里得距离简单地定义为:
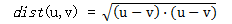
如果在考虑相似性时,向量各分量的量值确实很重要,这种度量更合适。
对于向量数据,计算向量集的均值也有意义。向量集的均值通过计算每个分量的均值实现。确实,有些聚类方法,如K-均值就是将数据对象划分成组(簇),并用数据对象(数据向量)的均值刻画每个簇。其基本思想是,簇中数据对象靠近均值的簇是好的簇。其中,对于象鸢尾花(最流行的机器学习数据集之一)这样的数据集,相似性用欧氏距离度量,而对于象文档这样的数据集用余弦相似性度量。
数据上的其它常用运算也可以看作向量上的运算。考虑降维操作,在最简单的方法中,数据向量中的某些分量被删除,而保留其它分量不变。有些降维技术产生数据向量的新的分量(属性)集,这些新分量是原分量的线性组合。
对于某些数据分析领域(如统计学),分析技术用数据向量和包含这些数据向量的数据矩阵上的运算数学地表达。这样,向量表示带动了可以用来表示、变换和分析数据的强有力的数学工具。














 1671
1671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









