







第一天
000_课程大纲介绍
第一个专题
1、Linux系统环境搭建和基本命令使用
第二至六个专题
2、Hadoop本地(单机)模式和伪分布式模式安装
Hadoop1.x理论知识,脚本体系,安装模式,认知HDFS文件系统,运行Mapreduce程序wordCout,如何查看Hadoop源码,Hadoop1.x包的结构等等
3、HDFS的体系结构、Shell操作、JavaAPI使用和应用案例
深入讲解HDFS相关内容,包括HDFS架构与设计,优缺点,如何存储文件,如何访问HDFS文件系统,包括:通过HDFS shell命令行,第二种通过Java API方式进行访问;另外讲解一些企业中的小案例,比如小文件的存储处理,类似百度网盘的分析(使用HDFS)等等。[3-4次课]
4、MapReduce入门、框架原理、深入学习和相关MR面试题
深入讲解MR,架构体系,执行流程,MR执行细节,讲解MR编写(WordCount):数据类型、输入输出格式、Combine、Partitioner、Sort和Group,插入企业中MR简单实用案例。7-8个课时
5、Hadoop?
6、Hadoop集群安装管理、NameNode安全模式和Hadoop1.x串讲复习
{属于hadoop运维工程师的课程,集群的安装部署[建立在为分布式安装基础上]}
->NN SafeMode、Hadoop管理员命令的使用。添加几点(机器)、卸载节点(机器)、监控Hadoop集群[3次课时]
第七至十个专题
7、ZooKeeper集群安装、回顾Hbase和mySql5.1安装与基本使用
主要为HBase和Hive基础理论讲解,zk协调HBase,mysql作为Hive元数据管理。【2次课时】
8、Hbase入门、存储原理、Shell命令、JavaAPI操作和应用案例
分布式数据库(NoSQL数据库),类似于Oracle数据库,存储几十亿行数据,上万列数据。准实时查询,与MR很好的集成,进行技术处理数据。体系架构、访问(shell和API)、MapReduce、管理,深入讲解,【4-5个课时】
9、Hive安装、配置元数据、HiveQL语句学习和应用案例
串讲复习HDFS、Mapreduce、HBase、Hive和Sqoop安装与数据导入导出;
->整体复习,串讲Hadoop、HBase和Hive,在企业中如何使用,如何考虑,结合三者进行考虑。Sqoop用于数据的导入导出,将关系型数据库中的数据与HBase和Hive之间的相互导入导出。【3此课时】
10、答疑总结、任务调度Azkaban安装和使用
进行整个Hadoop1.x课程的答疑,与项目的讲解[重点是项目讲解]。讲解任务调度框架,如何管理Job、管理Hive【3此课时】
第十一个专题
11、Hadoop2.2.0介绍、集群安装和商业版Hadoop介绍
Hadoop2.x介绍,Hadoop2.4为基础讲解,理论讲解;与Hadoop1.x不同,有点哪些?
安装:分布式安装,HDFS和MR程序测试。
介绍商业版的Hadoop:对apache开源Hadoop版本包括:CDH Hortonworrsk,Intel,华为,IBM[这些需要自学];【2次课时】
第十二个专题
12、Cloudera Hadoop介绍,CM4.8安装和部署CDH4.5:商业版Hadoop CDH的介绍,以及管理工具CM的安装
001_Linux系统基本知识说明和启动Linux虚拟机
002_配置虚拟机IP地址和如何使用远程工具SecureCRT
003_Linux 环境下基本命令使用及Linux系统中文件的类型和权限
004_Linux 环境下基本命令讲解二
005_Linux 系统远程FTP工具与桌面工具XManager使用和培养三大能力
006_Linux 系统基本命令和基本配置的复习讲解
3.2.7 分析启动脚本
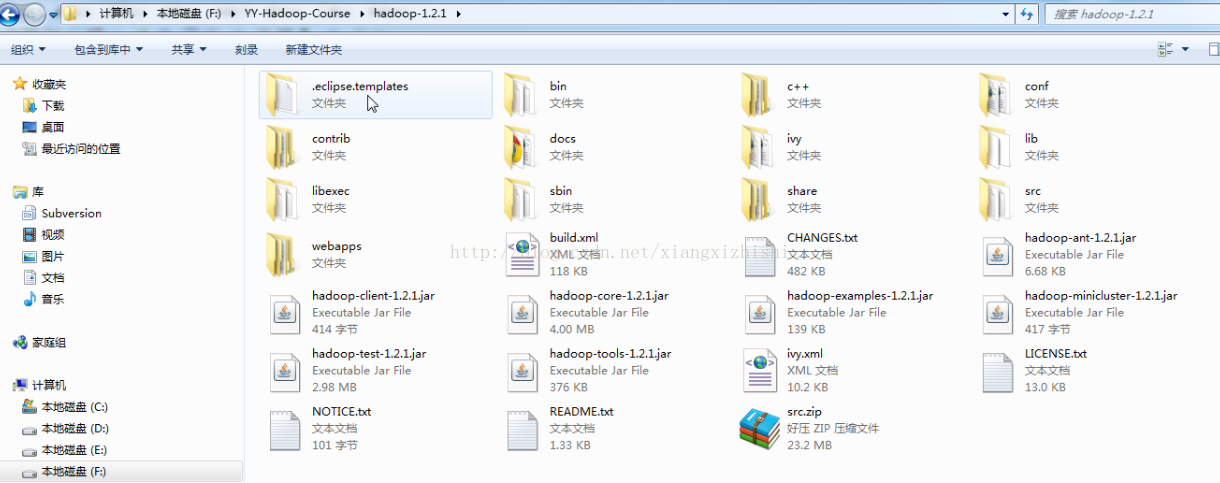
3.2.8 Hadoop1.X目录结构
如下图
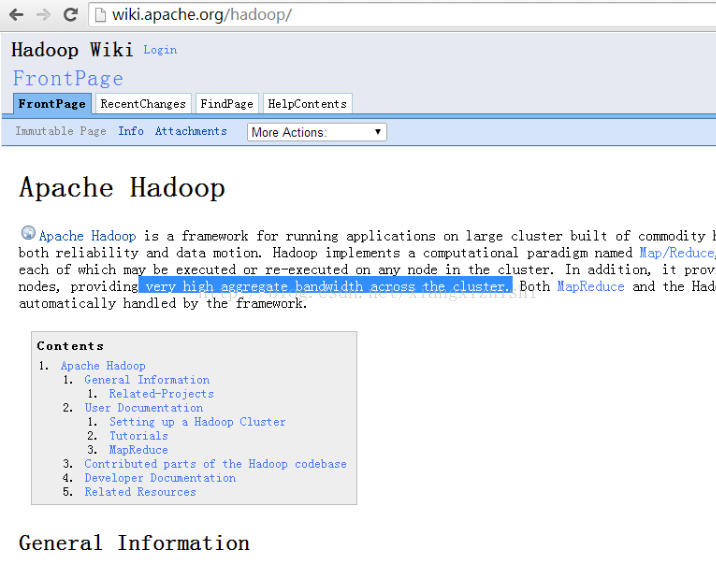
通过查看readme可以通过提供的地址,进入wiki(学习Hadoop非常重要的一个入口),可以进行相关信息的查看。
007_What is Apache Hadoop讲解
008_Hadoop 的发展史和版本发展与区别
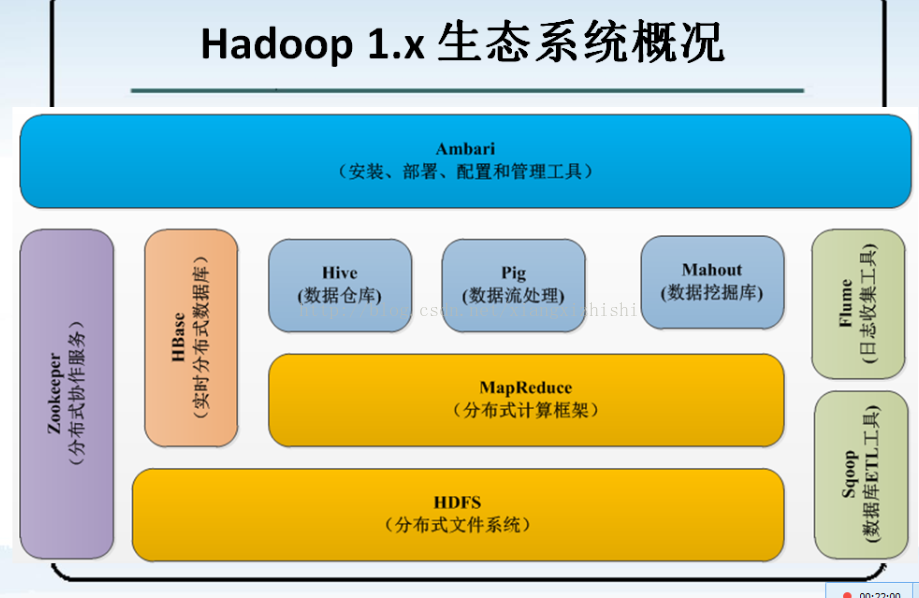
009_Hadoop 1.x 生态系统介绍讲解
1、对Apache Hadoop生态系统的认知(Hadoop1.x和Hadop2.x)
注意:
l ETL:提取 -> 转换 -> 加载
从数据库中获取数据,并进行一系列的数据清理和清洗筛选,将合格的数据进行转换成一定的格式数据进行存储,将格式化的数据存储到HDFS文件系统上,以供计算框架进行数据分析和挖掘。
格式化数据:
|- TSV格式,每行数据的每列之间以制表符(\t)进行分割;
|- CSV格式,每行数据的每列之间以(逗号)进行分割;
l Sqoop:
将关系型数据库中的数据与HDFS(HDFS文件,HBase中表,Hive中的表)上的数据进行相互导入导出。
l Flume:
收集各个应用系统和框架的日志,并将其放到HDFS分布式文件系统的响应指定目录下。
l Ambari
安装、部署、配置和管理工具,后面会讲比它更好用更强大的工具!
注意:
Hadoop1.x与Hadoop2.x生态的同与不同:
ü 增加了YARN
ü 改进了Pig->Pig2
ü Tez以及Storm
展望,后续会议2.x版本为主,-->Spark
2、Apache Hadoop1.x框架架构原理的初步认识
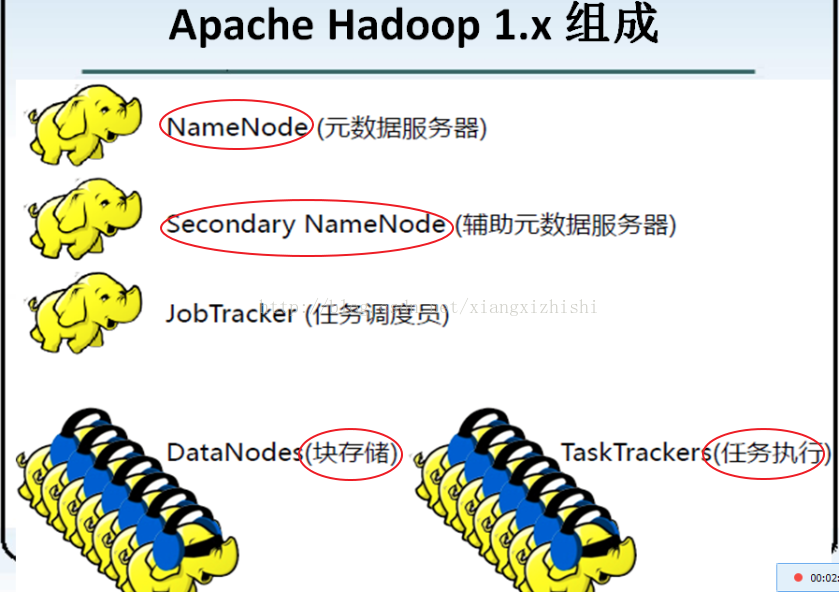
对于分布式系统和框架的架构来说,一般分为两部分:
1) :管理层(用于管理应用层的)
2) :应用层()
HDFS,分布式文件系统 说明:
l NameNode,属于管理层,用于管理数据的存储
l SecondaryNameNode,也属于管理层,辅助NameNode进行管理
l DataNode:属于应用层,用于进行数据的存储,被NameNode进行管理,要定时向NmaeNode进行工作汇报,执行NameNode分配分发的任务。
MapReduce,分布式的并行计算框架,
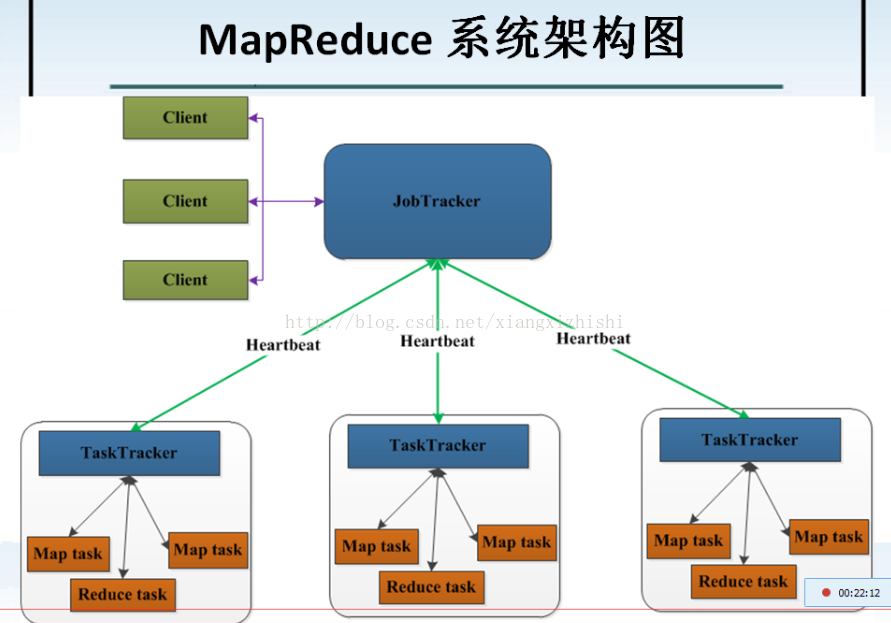
l JobTracker:属于管理层,管理集群资源和对任务进行资源调度,监控任务的执行。
l TaskTracker:属于应用层,执行JboTracker分配分发的任务,并向JobTracker进行汇报。
另,Apache Hadooop守护进行作用:
Ø NameNodwe是主节点,存储文件的元素据如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在DataNode等
Ø DataNode,在本地文件系统存储文件块数据,以及块数据的校验和。
Ø Secondary NameNode,用来监控HDFS状态的负载后台程序,每隔一段时间获取HDFS元数据的快照。
Ø JobTracker,负载接受用户提交的作用,负载启动、跟踪任务的执行。
Ø TaskTracke,负载执行由JobTracker分配的任务,管理各个任务在每个节点上的执行情况。
1)
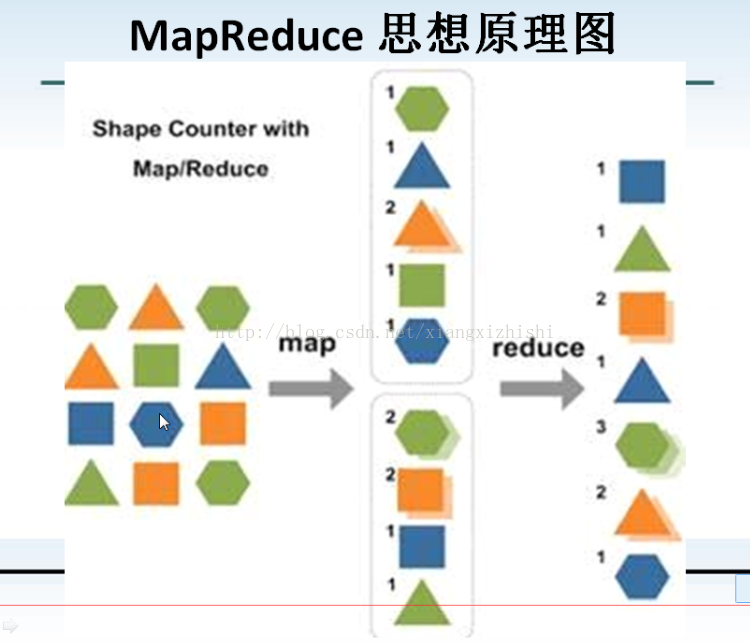
map:化整为零
Map:归约
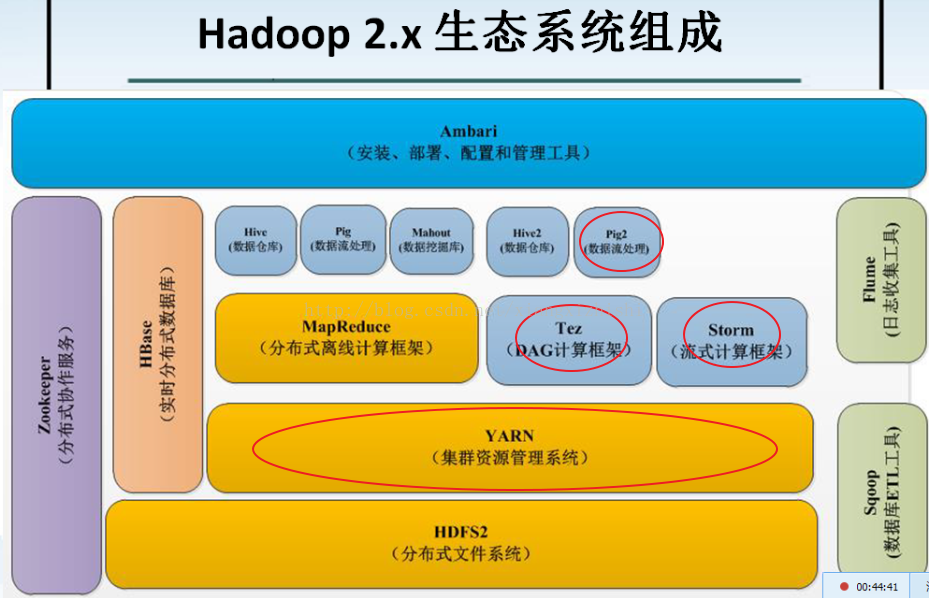
010_Hadoop 2.x 生态系统介绍讲解
注意:
Hadoop1.x与Hadoop2.x生态的同与不同:
ü 增加了YARN
ü 改进了Pig->Pig2
ü Tez以及Storm
展望,后续会议2.x版本为主,-->Spark
011_Hadoop 1.x 服务讲解
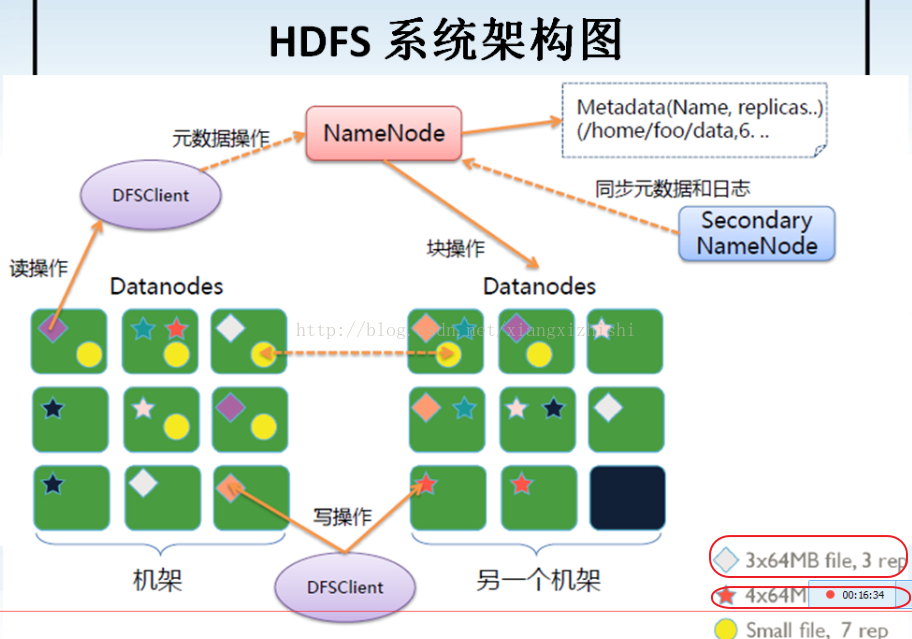
012_HDFS 架构的讲解
说明:
NameNode,存储文件的元数据
2) 文件名称
3) 文件的目录结构
4) 文件属性(权限、副本数、生成的时间)
文件 -> Block(块) -> (存储在)DataNodes上,
013_MapReduce 架构讲解和MapReduce思想原理讲解
014_Apache Hadoop 三种安装部署模式讲解
单机(本地)模式(Standalone Mode)
1) 安装JDK:
① 解压/opt/software/jdk-64b-linx-x64.bin到/opt/modules/
② 配置环境变量,编辑/etc/profile文件,添加如下内容:
##java
export JAVA_HOME=/opt/modules/jdk1.6.0_45
Export PATH=$PATH:$JAVA_HOME/bin
以root用户登陆,执行以下命令,使配置生效。
③ 测试
2)安装Hadoop1.2.1
① 解压
② 移动到软件安装目录
③ 配置环境变量
注意:以root用户登陆,使配置生效。
④ 测试
3)
015_Apache Hadoop 1.x 单机(本地)模式安装部署与测试
016_Hadoop 1.x 伪分布式安装部署
伪分布式模式(Pseudo-Distributed Mode)
一台机器,每个Hadoop守护进程都是一个独立的JVM进程,通常用于调试
伪分布模式要点:
017_查看Hadoop 日志以及日志的格式和命名组成
日志格式:
有两种日志:分别以log跟out结尾
① 以log结尾的日志
通过log4j日志记录格式进行日志的记录,采用的日常滚动文件后缀策略来命名日志文件,内容比较全
② 以out结尾的日志
记录标注输出
注意:在hadoop-env配置文件中可以进行配置,格式含有如下图:
018_Hadoop 1.x 守护进程服务三种启动停止方式
Hadoop启动、停止:
Hadoop启动、停止的三种模式,
1) 分别启动以及分别停止
分别启动HDFS和Mapreduce,命令如下,
启动:
$start-dfs.sh
$start-mapred.sh
停止:
$stop-mapred.sh
$stop-dfs.sh
2) 全部启动或全部停止
启动:
Start-all.sh
启动顺序:NameNode、DataNode、SecondNameNode、JobTracker、TaskTracker
停止:
Stop-all.sh
停止顺序:JobTracker、TaskTracker、NameNode、DataNode、SecondNameNode
具体如下图,
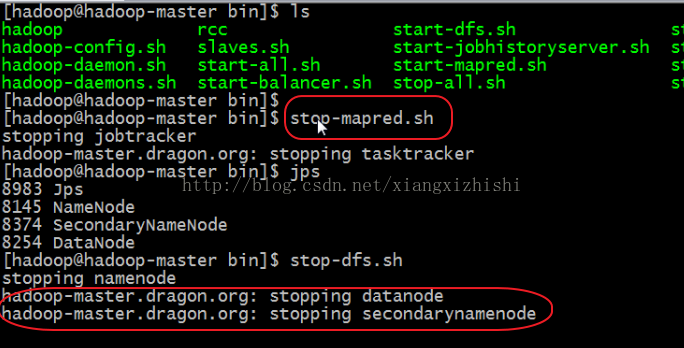
3) 分别启动、停止5个后台守护进程
启动顺序:NameNode、DataNode、SecondNameNode、JobTracker、TaskTracker
停止顺序:JobTracker、TaskTracker、NameNode、DataNode、SecondNameNode
具体命令如下图所示,
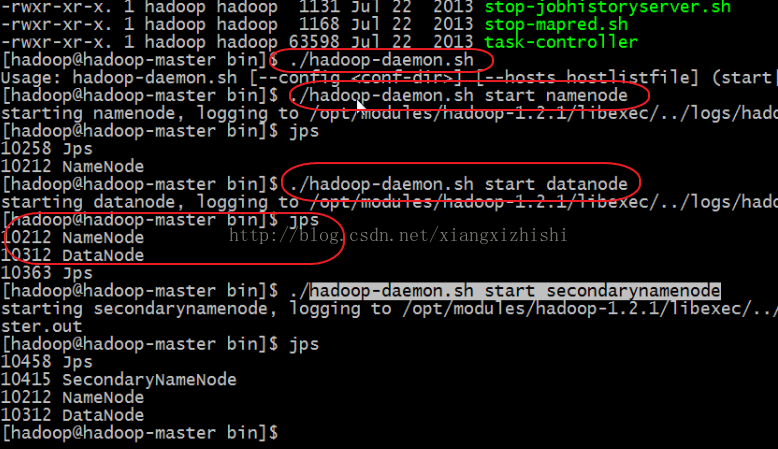
说明,
启动:
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
hadoop-daemon.sh start secondarynamenode
hadoop-daemon.sh start jobtracker
hadoop-daemon.sh start tasktracker
停止:
hadoop-daemon.sh stop jobtracker
hadoop-daemon.sh stop tasktracker
hadoop-daemon.sh stop namenode
hadoop-daemon.sh stop datanode
hadoop-daemon.sh stop secondarynamenode














 3818
3818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









