









本博客地址【http://blog.csdn.net/xiantian7】
版权所有,违者必究
豆瓣图片下载
scrapy startproject doubanImage
建立工程, pretty easy huh?
scrapy shell urlLink
及时工程中不添加任何代码,命令行也可以这么使用,这是用来模拟爬取的效果
出现结果
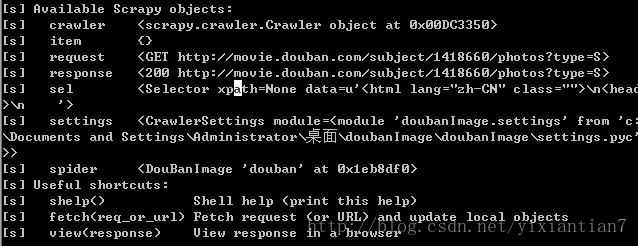
当然,测试爬取的效果,就是针对response 和sel两个结果来做处理,主要是sel,在sel的基础上使用xpath等过滤方法。基本的xpath用法前面介绍过
现在强调及几个重要的用法
1.sel是一个selector
2. sel.xpath(),之后得到的是一个selectorList,就是一堆的selector,这样就可以更快的获取我们需要的数据(使用sel.select()是一样的效果)
3、要取出节点下面的文本数据,需要使用sel.xpath().extract() 方法 或者 sel.select().extract()
hxs.select(‘//ul/li/div/a/@href’).extract()
选取了xpath中herf元素中的内容,<a href="被选取的内容"><img src="link"></img></a>
当然如果要选取link,应该这么写 hxs.select(‘//ul/li/div/a/img/@src').extract()
这么写可以得到图片的地址sel.select("//ul/li/div[@class='cover']/a/@href").extract()
而且对比一下就会发现,如果缩略图的URL是:
http://img3.douban.com/view/photo/thumb/public/p2151696782.jpg
那么这个图片的URL就是
http://img3.douban.com/view/photo/photo/public/p2151696782.jpg
然后我们点击图片左下角的查看原图,就会发现,图片的链接是:
http://img3.douban.com/view/photo/raw/public/p2151696782.jpg
这样只要简单的做一下字符串替换,就可以得到原图的link了
那么得到的spider文件应该是这样的
from scrapy.spider import BaseSpider
from scrapy.selector import HtmlXPathSelector
class DouBanImage(BaseSpider):
name = "douban"
allowed_domains = ["douban.com"]
filename = 'douban.txt'
f = open(filename, 'wb')
start_urls = ["http://movie.douban.com/subject/10581289/photos?type=S"]
def parse(self, response):
hxs = HtmlXPathSelector(response)
sites = hxs.select('//ul/li/div/a/img/@src').extract()
for site in sites:
site = site.replace('thumb','raw')
self.f.write(site)
self.f.write('\r\n')我们把链接地址全部就写入一个文件
观察每一页的地址,可以发现。。。。很有规律性的。。。start=0,40,80,120...于是乎,一个简单无比的代码就出来了
某一个页面分析完,不一定像我这种只想要图片地址的,比如说可能有人还想要每张图片的评论,所以呢,就有了Item这个文件,对于编辑items.py这个文件,每添加一个项,就是用XXX=Filed()就可以了。
from scrapy.item import Item, Field
class DoubanimageItem(Item):
# define the fields for your item here like:
# name = Field()
ImageAddress = Field()
pass最终的spider文件
from scrapy.spider import BaseSpider
from scrapy.selector import HtmlXPathSelector
from doubanImage.items import DoubanimageItem
import urllib
class DouBanImage(BaseSpider):
name = "douban"
allowed_domains = ["douban.com"]
start_urls = [];
f = open('douban.txt', 'w')
for i in range(0,1560,40):
start_urls.append('http://movie.douban.com/subject/10581289/photos?type=S&start=%d&sortby=vote&size=a&subtype=a'%i)
def parse(self, response):
hxs = HtmlXPathSelector(response)
sites = hxs.select('//ul/li/div/a/img/@src').extract()
items = []
self.f = open('douban.txt', 'a')
counter=0
for site in sites:
site = site.replace('thumb','raw')
self.f.write(site)
self.f.write('\r\n')
item = DoubanimageItem()
item['ImageAddress'] = site
items.append(item)
urllib.urlretrieve(site,str(counter)+'.jpg')
print'--------------------------------------------------------------'
print '*****************picture '+str(counter)+" is already downloaded************"
counter=counter+1;
self.f.close()
return items
上面的item的内容是:

reference link: 点我
数据库链接
先贴代码:
1、工程firstScrapy item文件
from scrapy.item import Item, Field
class FirstscrapyItem(Item):
title = Field(serializer=str)
link = Field(serializer=str) 2、spider文件
#coding=utf-8
__author__ = 'chenguolin'
"""
Date: 2014-03-06
"""
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from scrapy.contrib.spiders import CrawlSpider, Rule #这个是预定义的蜘蛛,使用它可以自定义爬取链接的规则rule
from scrapy.selector import HtmlXPathSelector #导入HtmlXPathSelector进行解析
from firstScrapy.items import FirstscrapyItem
f=open('log.txt','a')
class firstScrapy(CrawlSpider):
name = "firstScrapy" #爬虫的名字要唯一
allowed_domains = ["yuedu.baidu.com"] #运行爬取的网页
#start_urls = ["http://yuedu.baidu.com/book/list/0?od=0&show=1&pn=0"] #第一个爬取的网页
start_urls = ["http://yuedu.baidu.com/book/list/0?od=0&show=1"]
#以下定义了两个规则,第一个是当前要解析的网页,回调函数是myparse;第二个则是抓取到下一页链接的时候,不需要回调直接跳转
rules = [Rule(SgmlLinkExtractor(allow=('/ebook/[^/]+fr=booklist')), callback='myparse'),
Rule(SgmlLinkExtractor(allow=('/book/list/[^/]+pn=[^/]+', )), follow=True)]
#回调函数
def myparse(self, response):
x = HtmlXPathSelector(response)
item = FirstscrapyItem()
# get item
item['link'] = response.url
item['title'] = ""
f.write(str(item['link']+'\r\n'))
strlist = x.select("//h1/@title").extract()
if len(strlist) > 0:
item['title'] = strlist[0]
# return the item
return item
#coding=utf-8
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
from twisted.enterprise import adbapi #导入twisted的包
import MySQLdb
import MySQLdb.cursors
class FirstscrapyPipeline(object):
def __init__(self): #初始化连接mysql的数据库相关信息
self.dbpool = adbapi.ConnectionPool(
dbapiName='MySQLdb',
host='127.0.0.1',
db = '表名',
user = 'root',
passwd = '密码',
cursorclass = MySQLdb.cursors.DictCursor,
charset = 'utf8',
use_unicode = False
)
# pipeline dafault function #这个函数是pipeline默认调用的函数
def process_item(self, item, spider):
query = self.dbpool.runInteraction(self._conditional_insert, item)
return item
# insert the data to databases #把数据插入到数据库中
def _conditional_insert(self, tx, item):
p=open('yeah.txt','a')
p.write(str(item["link"]))
sql = "insert into book values (%s, %s)"
tx.execute(sql,(item["title"][0:], item["link"][0:]))
BOT_NAME = 'firstScrapy'
SPIDER_MODULES = ['firstScrapy.spiders']
NEWSPIDER_MODULE = 'firstScrapy.spiders'
ITEM_PIPELINES = [
'firstScrapy.pipelines.FirstscrapyPipeline'
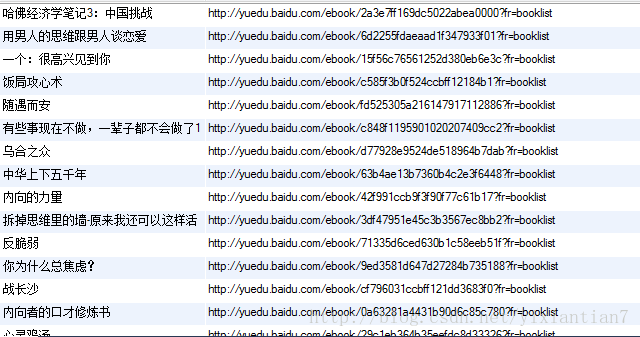
]再贴图
存储数据库的结果
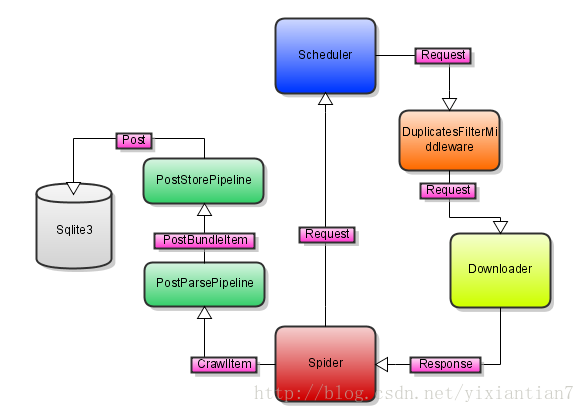
系统流程图
最后的数据库可以是其他数据库,我们这里使用的是MySQL














 434
434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









