







 博主介绍了自己初次尝试爬虫技术,通过phpspider框架爬取了看看豆网站11751本书的信息,爬取速度为每秒1条,受限于单线程和mysql数据库。提到了使用多线程和redis可以提升速度。爬取后的数据导出为.csv文件,并在Excel中进行了初步分析。他还分享了项目的GitHub链接,鼓励读者指正错误。
博主介绍了自己初次尝试爬虫技术,通过phpspider框架爬取了看看豆网站11751本书的信息,爬取速度为每秒1条,受限于单线程和mysql数据库。提到了使用多线程和redis可以提升速度。爬取后的数据导出为.csv文件,并在Excel中进行了初步分析。他还分享了项目的GitHub链接,鼓励读者指正错误。
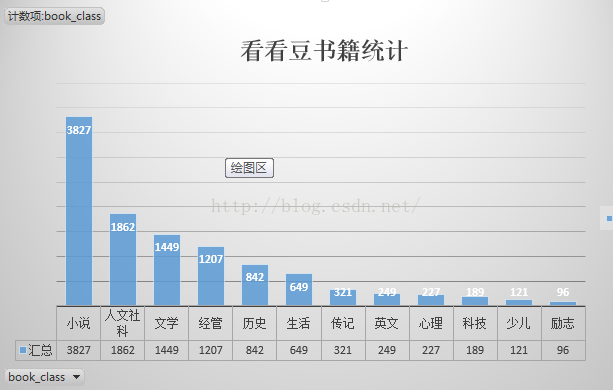
其实很早我就开始关注爬虫技术,这两天特别学习了一下,并且做了一个简单的demo。爬取了看看豆网站的数据信息。总共11751本书,爬取了不到3个小时,基本每秒爬取1条。速度慢的原因主要是单线程,使用mysql数据库。想要提高速度的话可以使用多线程和redis。但是对于初学者来说只要能爬取下来就很不错了。在这里我使用了一个爬虫框架---phpspider。
爬取完成后,我把数据从数据库中导成.csv格式。由于我的数据比较少,所以我是直接excle中做的分析。按道理来说应该使用JS的ECharts做数据分析的。但是我的Node.JS还没有学习过。所以先简单的进行测试。另,我已经把自己的demo上传到了github。https://github.com/XiaoTommy/phpspider
附:
ECharts官网:http://echarts.baidu.com/
Node.js官网:https://nodejs.org/en/

demo源代码如下:
<?php
ini_set("memory_limit", "1024M");
require dirname(__FILE__).'/../core/init.php';
/* Do NOT delete this comment */
/* 不要删除这段注释 */
$configs = array(
'name' => '看豆豆',
// 'log_show' => false,
'tasknum' => 1,
//'save_running_state' => true,
'domains' => array(
'kankandou.com',
'www.kankandou.com'
),
'scan_urls' => array(
'https://kankandou.com/'
),
'list_url_regexes' => array(
"https://kankandou.com/book/page/\d+"
),
'content_url_regexes' => array(
"https://kankandou.com/book/view/\d+.html",
),
'max_try' => 5,
//'export' => array(
//'type' => 'csv',
//'file' => PATH_DATA.'/qiushibaike.csv',
//),
//'export' => array(
//'type' => 'sql',
//'file' => PATH_DATA.'/qiushibaike.sql',
//'table' => 'content',
//),
'export' => array(
'type' => 'db',
'table' => 'kankandou',
),
'fields' => array(
array(
'name' => "book_name",
'selector' => "//h1[contains(@class,'title')]/text()",
'required' => true,
),
array(
'name' => "book_content",
'selector' => "//div[contains(@class,'content')]/text()",
'required' => true,
),
array(
'name' => "book_author",
'selector' => "//p[contains(@class,'author')]/a",
'required' => true,
),
array(
'name' => "book_img",
'selector' => "//div[contains(@class,'img')]/a/img",
'required' => true,
),
array(
'name' => "book_format",
'selector' => "//p[contains(@class,'ext')]",
'required' => true,
),
array(
'name' => "book_class",
'selector' => "//p[contains(@class,'cate')]/a",
'required' => true,
),
array(
'name' => "click_num",
'selector' => "//i[contains(@class,'dc')]",
'required' => true,
),
array(
'name' => "download_num",
'selector' => "//i[contains(@class,'vc')]",
'required' => true,
),
),
);
$spider = new phpspider($configs);
$spider->on_handle_img = function($fieldname, $img)
{
$regex = '/src="(https?:\/\/.*?)"/i';
preg_match($regex, $img, $rs);
if (!$rs)
{
return $img;
}
$url = $rs[1];
$img = $url;
//$pathinfo = pathinfo($url);
//$fileext = $pathinfo['extension'];
//if (strtolower($fileext) == 'jpeg')
//{
//$fileext = 'jpg';
//}
以纳秒为单位生成随机数
//$filename = uniqid().".".$fileext;
在data目录下生成图片
//$filepath = PATH_ROOT."/images/{$filename}";
用系统自带的下载器wget下载
//exec("wget -q {$url} -O {$filepath}");
替换成真是图片url
//$img = str_replace($url, $filename, $img);
return $img;
};
$spider->start();
其中有任何不对的地方,望请指正。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









