







一、概述
HBase是一个构建在HDFS上的分布式列存储系统;HBase是Apache Hadoop生态系统中的重要一员,主要用于海量结构化数据存储;从逻辑上讲,HBase将数据按照表、行和列进行存储。它介于nosql和RDBMS之间,仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务(可通过hive支持来实现多表join等复杂操作)。主要用来存储非结构化和半结构化的松散数据。与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。因为HDFS适合批处理场景,不支持数据随机查找,不适合增量数据处理,也不支持数据更新,而HBase的出现正好解决了HDFS不能解决的问题。
下面一幅图是Hbase在Hadoop Ecosystem中的位置。
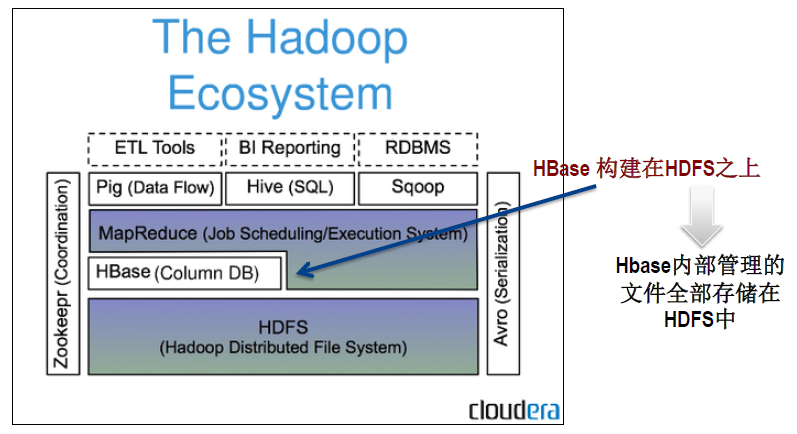
二、HBase表的特点
- 大:一个表可以有数十亿行,上百万列;
- 无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中不同的行可以有截然不同的列;
- 面向列:面向列(族)的存储和权限控制,列(族)独立检索;
- 稀疏:对于空(null)的列,并不占用存储空间,表可以设计的非常稀疏;
- 数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳;
- 数据类型单一:Hbase中的数据都是字符串,没有类型
HBase采用列存储形式。列存储不同于传统的关系型数据库(数据在表中是按行存储的),列方式所带来的重要好处之一就是,由于查询中的选择规则是通过列来定义的,因此整个数据库是自动索引化的。按列存储每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量,一个字段的数据聚集存储,那就更容易为这种聚集存储设计更好的压缩/解压算法。下图讲述了传统的行存储和列存储的区别:
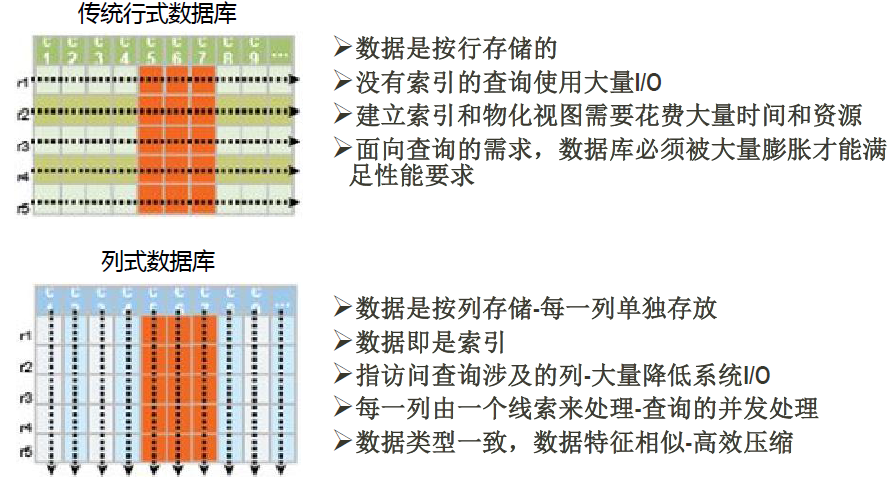
三、HBase的数据模型
HBase是基于Google BigTable模型开发的,典型的key/value系统;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 191
191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









