




一、概述
目前计算框架和作业类型繁多:包括MapReduce Java、Streaming、HQL、Pig等,如何对这些框架和作业进行统一管理和调度是我们需要面临的一个问题。目前有多种解决方案:可以使用Crontab,也可以自己设计调度系统,还可以直接使用开源系统。
如果我们自己设计调度系统,可以通过crontab+shell来实现,如下所示:
//mapreduce_job.sh
cmd=“hadoop jar example1.jar xxx –D …..”
$cmd
code=$?
while [ $code != 0 ]; do
echo “run job failed, run submit……"
$cmd
done//hive_job.sh
cmd=“hive -e \“use mydatabase; ALTER TABLE t_aa ADD IF NOT EXISTS PARTITION (pt='2013052515') location '/group/data/aa/2013-05-25-15/';SELECT COUNT(1) FROM t_aa WHERE t_aa.pt = '2013052515‘\” ”
$cmd
code=$?
while [ $code != 0 ]; do
echo “run hql failed, run submit……"
$cmd
done//main.sh
sh mapreduce_job.sh
sh hive_job.sh//crontab
*/10 * * * * root /opt/bin/main.sh可以看到自己设计调度系统有几个缺点:
- 编写复杂,不灵活
- 不易于管理
- 难以与监控、报警相结合
此时我们就需要使用开源作业流调度系统,常见的如下:
- Oozie:Yahoo!开源,基于xml表达作业依赖关系;
- Azkaban:Linkedin开源,通过Java property配置作业依赖关系
- Zeus(宙斯):阿里开源,通过界面配置作业依赖关系
- 其他开源系统:Cascading(通过Java API编程实现作业依赖关系)
下面我们来详细阐述一下哎Oozie的基本使用。
二、Oozie架构和原理
1、什么是Oozie?
Apache Oozie 是用于 Hadoop 平台的一种工作流调度引擎。该框架使用 Oozie 协调器促进了相互依赖的重复工作之间的协调,我们可以使用预定的时间或数据可用性来触发 Apache Oozie。也可以使用 Oozie bundle 系统提交或维护一组协调应用程序。它在Hadoop生态系统中的位置如下:
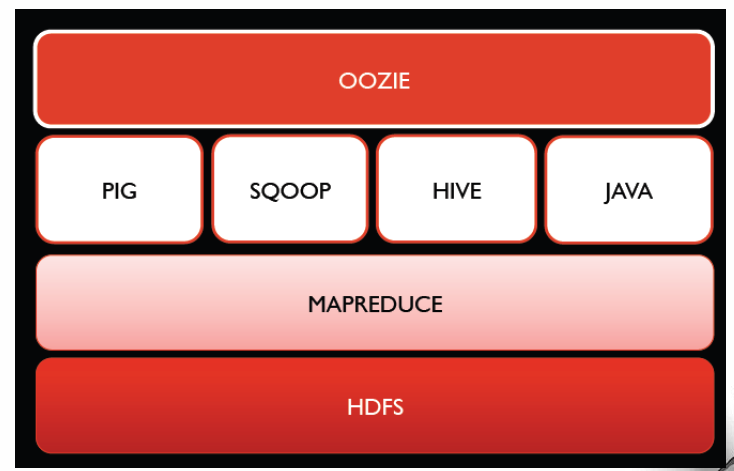
例如,Oozie可以 运行一个 Apache Sqoop 作业,以便在 MySQL 数据库中的数据上执行导入操作,并将数据传输到 Hadoop 分布式文件系统 (HDFS) 中。可以利用导入的数据集执行 Sqoop 合并操作,从而更新较旧的数据集。通过利用 UNIX shell 操作,可从 MySQL 数据库中提取用来执行 Sqoop 作业的元数据。同理,可执行 Java 操作来更新 Sqoop 作业所需的 MySQL 数据库中的元数据。
2、Oozie的基本原理
本质上来说,Oozie是一种Java Web应用程序,它运行在Java servlet容器(例如Tomca中),并使用数据来存储相关数据,其基本运行流程如下:
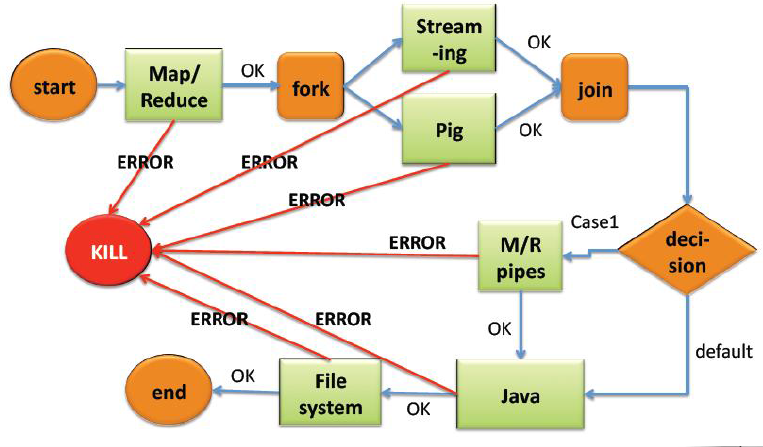
- 工作流定义
当前运行的工作流实例,包括实例的状态和变量。Oozie工作流是放置在控制依赖DAG(有向无环图 Direct Acyclic Graph)中的一组动作(例如,Hadoop的Map/Reduce作业、Pig作业等),其中指定了动作执行的顺序。我们会使用hPDL(一种XML流程定义语言)来描述这个图。 - hPDL
hPDL是一种很简洁的语言,只会使用少数流程控制和动作节点。控制节点会定义执行的流程,并包含工作流的起点和终点(start、end和fail节点)以及控制工作流执行路径的机制(decision、fork和join节点)。动作节点是一些机制,通过它们工作流会触发执行计算或者处理任务。Oozie为以下类型的动作提供支持: Hadoop map-reduce、Hadoop文件系统、Pig、Java和Oozie的子工作流(SSH动作已经从Oozie schema 0.2之后的版本中移除了)。 - 计算过程
所有由动作节点触发的计算和处理任务都不在Oozie之中——它们是由Hadoop的Map/Reduce框架执行的。这种方法让Oozie可以支持现存的Hadoop用于负载平衡、灾难恢复的机制。这些任务主要是异步执行的(只有文件系统动作例外,它是同步处理的)。这意味着对于大多数工作流动作触发的计算或处理任务的类型来说,在工作流操作转换到工作流的下一个节点之前都需要等待,直到计算或处理任务结束了之后才能够继续。Oozie可以通过两种不同的方式来检测计算或处理任务是否完成,也就是回调和轮询。当Oozie启动了计算或处理任务的时候,它会为任务提供唯一的回调URL,然后任务会在完成的时候发送通知给特定的URL。在任务无法触发回调URL的情况下(可能是因为任何原因,比方说网络闪断),或者当任务的类型无法在完成时触发回调URL的时候,Oozie有一种机制,可以对计算或处理任务进行轮询,从而保证能够完成任务。 - 参数化定义
Oozie工作流可以参数化(在工作流定义中使用像${inputDir}之类的变量)。在提交工作流操作的时候,我们必须提供参数值。如果经过合适地参数化(比方说,使用不同的输出目录),那么多个同样的工作流操作可以并发。 - 设计触发器
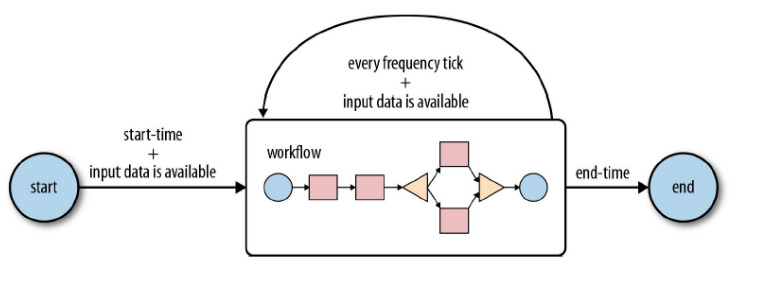
一些工作流是根据需要触发的,但是大多数情况下,我们有必要基于一定的时间段和(或)数据可用性和(或)外部事件来运行它们。Oozie协调系统(Coordinator system)让用户可以基于这些参数来定义工作流执行计划。Oozie协调程序让我们可以以谓词的方式对工作流执行触发器进行建模,那可以指向数据、事件和(或)外部事件。工作流作业会在谓词得到满足的时候启动。 - 设计定时器
经常我们还需要连接定时运行、但时间间隔不同的工作流操作。多个随后运行的工作流的输出会成为下一个工作流的输入。把这些工作流连接在一起,会让系统把它作为数据应用的管道来引用。Oozie协调程序支持创建这样的数据应用管道。
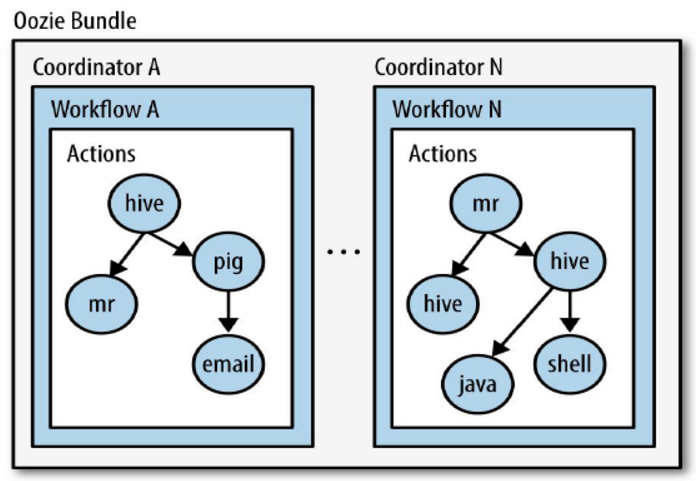
3、Oozie 层次结构
Oozie是管理Hadoop作业的工作流调度系统。Oozie定义了控制流节点和动作节点。其基本层次结构如下:
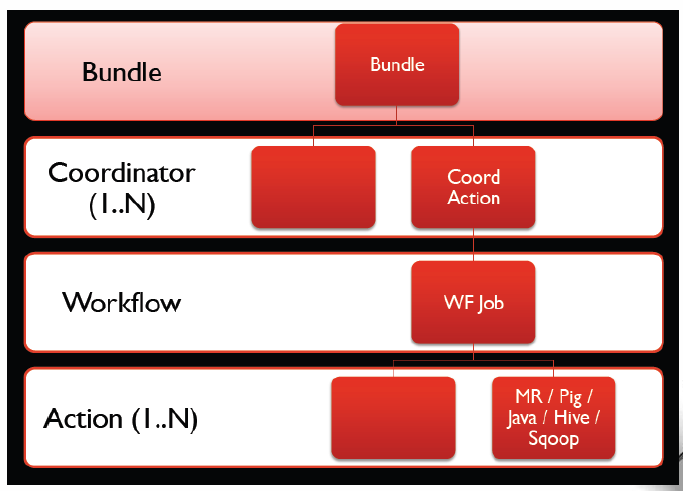
- Workflow:顺序执行流程节点;
- Coordinator:定时触发workflow;
- Bundle Job:绑定多个Coordinator。
4、Oozie安装
Oozie的安装较为复杂,这里不详细展开,具体可参考这位博主的相关博客。点我
三、Oozie使用示例
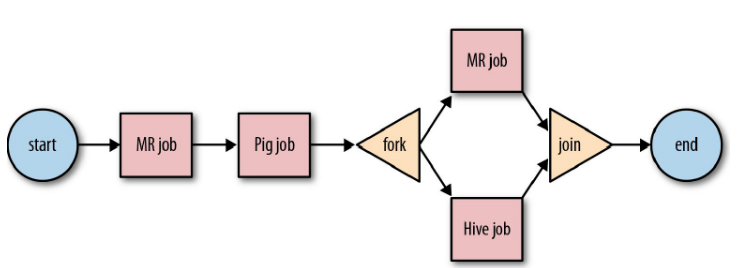
我们创建一个简单的示例。我们拥有两个Map/Reduce作业——一个会获取最初的数据,另一个会合并指定类型的数据。实际的获取操作需要执行最初的获取操作,然后把两种类型的数据——Lidar和Multicam——合并。为了让这个过程自动化,我们需要创建一个简单的Oozie工作流。
<!--
Copyright (c) 2011 NAVTEQ! Inc. All rights reserved.
NGMB IPS ingestor Oozie Script
-->
<workflow-app xmlns='uri:oozie:workflow:0.1' name='NGMB-IPS-ingestion'>
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 788
788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









