







转载请注明文章出处和作者!
出处:http://blog.csdn.net/xl19862005
作者:大熊(Xandy)
在上一篇中简单的说明了一下要增加recovery功能所涉及到的代码修改部分,代码修改成功之后并不等于所需要的功能就OK了,编译通过烧录到目标板之后还有一大堆的问题需要处理!
经过一天的努力bootloader及recovery添加并编译成功了,烧录到样机上后首先要验证的是bootcmd切换是否正常,这里加入了测试用的bootcmd切换开关,如下红色标注:
#define CONFIG_EXTRA_ENV_SETTINGS \
"loadaddr=0x82000000\0" \
"nandboot=echo Booting from nand ...; " \
"nand read ${loadaddr} 280000 500000; bootm ${loadaddr}\0" \
"bootcmd=run nandboot\0" \
"bootargs=init=/init console=ttyO2,115200n8 ip=off " \
"androidboot.console=ttyO2 mem=512M rw ubi.mtd=6,2048 " \
"rootfstype=ubifs root=ubi0:rootfs rootdelay=2 " \
"omapdss.def_disp=lcd " \
"vram=8M omapfb.vram=0:8M mpurate=1000\0" \
"android_recovery_switch=1\0"
这里要说明一下,修改编译uboot之后烧录到样机上后这里的修改后的bootcmd是不会起作用的,原因就是在于烧录uboot的时候是烧录至uboot对应的分区的,而bootcmd这些系统启动参数则是保存在uboot-env这个分区里的,在上一篇的分区列表里就可以看出来!
关于如何烧录镜像文件至指定分区,这里简单提一下,可以用TI原厂提供的Flash v1.x烧录工具,也可以用fastboot或者其它的办法,我这里用的是fastboot批处理的方式!
那么怎样让新的bootcmd生效呢,我们可以用
nand erase
这个命令来擦除相应分区里的内容,但要注意的是如果你直接输入nand erase回车,那么你的整个nand空间将会被清除,包括xloader及uboot!那么要如想擦除指定分区呢?
需要再提到一个在uboot里对就的config里有类似如下的默认(default)分区列表:
#define MTDPARTS_DEFAULT"mtdparts=nand:512k(xloader),"\
"1920k(uboot),"\
"128k(ubootenv),"\
"5m(kernel),"\
"1m(cache),"\
"100m(recovery),"\
"256m(system)"
只需要在uboot的命令行里简单的输入一条命令:
mtdparts default
然后再运行nand erase xx,这里的xx可以是mtdparts里的分区代码,如
nand erase ubootenv
这样就可以擦除相应的分区空间了!
当系统启动后正常加载内核,开始解析UBI各种参数,但很有可能出现如下错误:
[ 1.675323] omap2-nand driver initializing
[ 1.679931] NAND device: Manufacturer ID: 0xad, Chip ID: 0xbc (Hynix )
[ 1.686767] Creating 7 MTD partitions on "omap2-nand.0":
[ 1.692321] 0x000000000000-0x000000020000 : "X-Loader"
[ 1.698944] 0x000000080000-0x000000240000 : "U-Boot"
[ 1.705902] 0x000000260000-0x0000002a0000 : "U-Boot Env"
[ 1.712554] 0x000000280000-0x000000780000 : "Kernel"
[ 1.720794] 0x000000780000-0x000000880000 : "cache"
[ 1.727325] 0x000000880000-0x000006c80000 : "recovery"
[ 1.774688] 0x000006c80000-0x000020000000 : "File System"
[ 1.946777] OneNAND driver initializing
[ 1.951416] UBI: attaching mtd5 to ubi0
[ 1.955413] UBI: physical eraseblock size: 131072 bytes (128 KiB)
[ 1.961944] UBI: logical eraseblock size: 129024 bytes
[ 1.967590] UBI: smallest flash I/O unit: 2048
[ 1.972473] UBI: sub-page size: 512
[ 1.977294] UBI: VID header offset: 512 (aligned 512)
[ 1.983367] UBI: data offset: 2048
[ 1.988586] UBI error: validate_ec_hdr: bad VID header offset 2048, expected 512
[ 1.996276] UBI error: validate_ec_hdr: bad EC header
[ 2.001556] UBI error: ubi_io_read_ec_hdr: validation failed for PEB 0
[ 2.008392] UBI error: ubi_init: cannot attach mtd5
这是因为在制作UBI文件镜像的时候的参数不对,这里提示的是VID header offset有问题,那么就按这里提示将VID header offset参数改成512
如下红色字串:
ubinize -o ${OUT_IMAGE_PATH}/recovery.img -m 2048 -p 128KiB -s 512 -O 512 reubinize.cfg
关于这些参数的说明可以在ubuntu下输入ubinize -h查看相应说明(前提是你已经下载并编译安装了mtd-ubifs)
重新制作文件镜像并烧录到机子上启动后出现如下信息:
[ 1.688598] omap2-nand driver initializing
[ 1.693206] NAND device: Manufacturer ID: 0xad, Chip ID: 0xbc (Hynix )
[ 1.700042] Creating 7 MTD partitions on "omap2-nand.0":
[ 1.705566] 0x000000000000-0x000000020000 : "X-Loader"
[ 1.712219] 0x000000080000-0x000000240000 : "U-Boot"
[ 1.719177] 0x000000260000-0x0000002a0000 : "U-Boot Env"
[ 1.725799] 0x000000280000-0x000000780000 : "Kernel"
[ 1.734039] 0x000000780000-0x000000880000 : "cache"
[ 1.740570] 0x000000880000-0x000006c80000 : "recovery"
[ 1.787994] 0x000006c80000-0x000020000000 : "File System"
[ 1.960144] OneNAND driver initializing
[ 1.964782] UBI: attaching mtd5 to ubi0
[ 1.968780] UBI: physical eraseblock size: 131072 bytes (128 KiB)
[ 1.975372] UBI: logical eraseblock size: 129024 bytes
[ 1.980987] UBI: smallest flash I/O unit: 2048
[ 1.985870] UBI: sub-page size: 512
[ 1.990692] UBI: VID header offset: 512 (aligned 512)
[ 1.996765] UBI: data offset: 2048
[ 2.167388] UBI: max. sequence number: 0
[ 2.187500] UBI: volume 0 ("rootfs") re-sized from 773 to 788 LEBs
[ 2.194702] UBI: attached mtd5 to ubi0
[ 2.198638] UBI: MTD device name: "recovery"
[ 2.204071] UBI: MTD device size: 100 MiB
[ 2.209259] UBI: number of good PEBs: 800
[ 2.214050] UBI: number of bad PEBs: 0
[ 2.218688] UBI: number of corrupted PEBs: 0
[ 2.223297] UBI: max. allowed volumes: 128
[ 2.228118] UBI: wear-leveling threshold: 4096
[ 2.233001] UBI: number of internal volumes: 1
[ 2.237640] UBI: number of user volumes: 1
[ 2.242248] UBI: available PEBs: 0
[ 2.246887] UBI: total number of reserved PEBs: 800
[ 2.251983] UBI: number of PEBs reserved for bad PEB handling: 8
[ 2.258209] UBI: max/mean erase counter: 1/0
[ 2.262664] UBI: image sequence number: 34986596
[ 2.267639] UBI: background thread "ubi_bgt0d" started, PID 563
可以看出对UBI的解析已经正常了,下面将进入ubifs,出现如下信息:
[ 7.308471] UBIFS error (pid 1): validate_sb: LEB size mismatch: 126976 in superblock, 129024 real
[ 7.317840] UBIFS error (pid 1): validate_sb: bad superblock, error 1
[ 7.326354] List of all partitions:
[ 7.330047] 1f00 128 mtdblock0 (driver?)
[ 7.335296] 1f01 1792 mtdblock1 (driver?)
[ 7.340576] 1f02 256 mtdblock2 (driver?)
[ 7.345855] 1f03 5120 mtdblock3 (driver?)
[ 7.351104] 1f04 1024 mtdblock4 (driver?)
[ 7.356384] 1f05 102400 mtdblock5 (driver?)
[ 7.361663] 1f06 413184 mtdblock6 (driver?)
[ 7.366912] b300 3872256 mmcblk0 driver: mmcblk
[ 7.372467] b301 3871232 mmcblk0p1 00000000-0000-0000-0000-000000000000mmcblk0p1
[ 7.381072] No filesystem could mount root, tried: ubifs
从这里得到的信息提示可以看出还是制作ubifs文件镜像的时候出问题了,这里提示的是超级块(superblock)有问题,LEB size mismatch!!
LEB size mismatch继续ubuntu下输入mkfs.ubifs -h查看帮助,看出有如下一条:
-e, --leb-size=SIZE logical erase block size
就是这个-e参数了,按这里提示将之前的126976修改成129024,最后如下:
mkfs.ubifs -r ${RECOVERY_ROOTFS} -F -o ubifs.img -m 2048 -e 129024 -c 788
另外还有一个要说明的是ubifs.cfg这个文件及-c参数确认的问题
如我对应的recovery的ubifs.cfg文件如下:
[ubifs]
mode=ubi
image=ubifs.img
vol_id=0
vol_size=95MiB
vol_type=dynamic
vol_name=rootfs
vol_flags=autoresize
这里要注意的是上面红色字串
关于这些值的计算说明如下:
Usable Size Calculation
As documented here, UBI reserves a certain amount of space for management and bad PEB handling operations. Specifically:
- 2 PEBs are used to store the UBI volume table
- 1 PEB is reserved for wear-leveling purposes;
- 1 PEB is reserved for the atomic LEB change operation;
- a % of PEBs is reserved for handling bad EBs. The default for NAND is 1%
- UBI stores the erase counter (EC) and volume ID (VID) headers at the beginning of each PEB. 1 min I/O unit is required for each of these.
To calculate the full overhead, we need the following values:
| Symbol | Meaning | Value for XO test case |
|---|---|---|
| SP | PEB Size | 128KiB |
| SL | LEB Size | 128KiB - 2 * 2KiB = 124 KiB |
| P | Total number of PEBs on the MTD device | 100MiB / 128KiB = 800 |
| B | Number of PEBs reserved for bad PEB handling | 1% of P = 8 |
| O | The overhead related to storing EC and VID headers in bytes, i.e. O = SP - SL | 4KiB |
UBI Overhead = (B + 4) * SP + O * (P - B - 4)
= (8 + 4) * 128Kib + 4 KiB * (800 - 8 - 4)
= 4688 KiB
= 36.625 PEBs (取整数 36)
This leaves us with 800-36=764 PEBs or 97792KiB available for user data.
Note that we used "-c 788" in the above mkfs.ubifs command line to specify the maximum filesystem size, not "-c 764" The reason for this is that mkfs.ubifs operates in terms of LEB size (124 KiB), not PEB size (128Kib). 97792KiB / 124 Kib = 788.645... (取整788).
Volume size = 97792KiB (~95MiB)
这里要说明一下的是,为什么我把recovery分区设置成了100MiB,原因是要得到B这个参数是1% * P得到的,那么P一定要大于等于100,而100*128KiB = 12.5MiB,由于我的nand是512MiB,就干脆把recovery分区设置成100MiB(要考虑到坏块等问题)经过上面这些折腾之后,重新烧录recovery文件镜像,系统重启之后,哈哈,看下图:
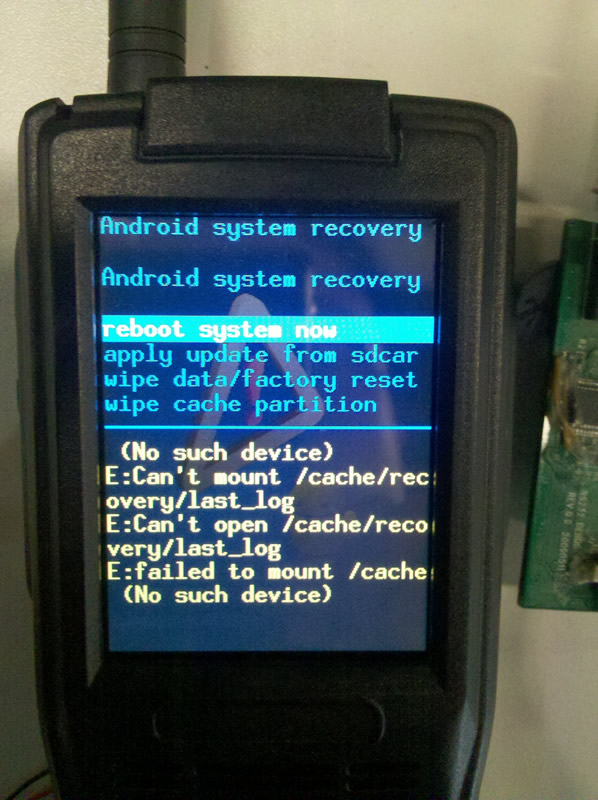
但很快发现问题了,第一次进入recovery状态是OK的,断电重启再次进入时则会出现如下错误:
[ 1.754913] UBI: attaching mtd4 to ubi0
[ 1.759155] UBI: physical eraseblock size: 131072 bytes (128 KiB)
[ 1.765625] UBI: logical eraseblock size: 129024 bytes
[ 1.771301] UBI: smallest flash I/O unit: 2048
[ 1.776214] UBI: sub-page size: 512
[ 1.780975] UBI: VID header offset: 512 (aligned 512)
[ 1.787078] UBI: data offset: 2048
[ 1.794128] UBI error: ubi_io_read: error -74 (ECC error) while reading 64 bytes from PEB 2:0, read 64 bytes
[ 1.804473] [<c00a3678>] (unwind_backtrace+0x0/0xec) from [<c02be868>](ubi_io_read+0x1b4/0x248)
[ 1.813659] [<c02be868>] (ubi_io_read+0x1b4/0x248) from [<c02bee1c>](ubi_io_read_ec_hdr+0x6c/0x338)
[ 1.823242] [<c02bee1c>] (ubi_io_read_ec_hdr+0x6c/0x338) from[<c02c24f0>] (ubi_scan+0x1b4/0xb9c)
[ 1.832489] [<c02c24f0>] (ubi_scan+0x1b4/0xb9c) from [<c02b9624>]
从错误提示的内容来看是ECC出问题了,但是这里用的是HWECC,怎么会报这个错误呢?
google一遍,在下面这篇博客里找到了问题的原因:
http://blog.csdn.net/lidehua1975/article/details/7768185
按照这里的方法修改,其中options最先的初始化是在arch/arm/mach-omap2/board-xx.c的
zt6810_flash_init函数中
static void __init zt6810_flash_init(void)
{
……
……
NAND_NO_SUBPAGE_WRITE if (nandcs < GPMC_CS_NUM) {
printk(KERN_INFO "Registering NAND on CS%d\n", nandcs);
board_nand_init(zt6810_nand_partitions,ARRAY_SIZE(zt6810_nand_partitions),nandcs, NAND_BUSWIDTH_16 | NAND_NO_SUBPAGE_WRITE);//modify by Xandy,NO subpage write
}
}
编译完内核烧录,再次进入到recovery模式,出现如下信息:
[ 7.308471] UBIFS error (pid 1): validate_sb: LEB size mismatch:129024 in superblock,126976 real
[ 7.317840] UBIFS error (pid 1): validate_sb: bad superblock, error 1
[ 7.326354] List of all partitions:
[ 7.330047] 1f00 128 mtdblock0 (driver?)
[ 7.335296] 1f01 1792 mtdblock1 (driver?)
[ 7.340576] 1f02 256 mtdblock2 (driver?)
[ 7.345855] 1f03 5120 mtdblock3 (driver?)
[ 7.351104] 1f04 1024 mtdblock4 (driver?)
[ 7.356384] 1f05 102400 mtdblock5 (driver?)
[ 7.361663] 1f06 413184 mtdblock6 (driver?)
[ 7.366912] b300 3872256 mmcblk0 driver: mmcblk
[ 7.372467] b301 3871232 mmcblk0p1 00000000-0000-0000-0000-000000000000mmcblk0p1
[ 7.381072] No filesystem could mount root, tried: ubifs
哎,重新把制作recovery文件镜像的参数改回之前的吧:
mkfs.ubifs -r ${RECOVERY_ROOTFS} -F -o ubifs.img -m 2048 -e126976 -c 788
烧录,运行,就不会再出现上面这些问题了!
真的是拔山涉水呀!!
目前 recovery系统已经正常加载了,但还有问题,比如图中提示的cache分区无法挂上去,这个有空再更进修改recovery下分区挂载的问题。















 9459
9459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









