









本次作业题的内容是利用朴素贝叶斯分类器识别是否为垃圾邮件,关于文本的提取,分词,和标注都是已成形的数据,只需要写个朴素贝叶斯分类器验证正确率就可以。
关于朴素贝叶斯的模型可以参考
http://blog.csdn.net/longxinchen_ml/article/details/50597149,讲的很清楚,ng在视频中讲的朴素贝叶斯分类器用的是伯努利模型,即只计算某个词受否存在,而忽略了关于词频,而本道作业题使用的多项式模型。
在本次作业中有几个注意的点:
1.需使用laplace平滑,因为有些词语可能在我们的训练数据中从未出现过,就会导致概率为0的情况,而朴素贝叶斯模型中分子是一些概率连乘积,如果有一项为0,会导致答案为0。
2.朴素贝叶斯模型中分子是一些概率连乘积,而每一项都很小,会导致连乘积很小,出现越界的情况,导致为0,这里对于概率取对数,概率的连乘积也变成对数相加,由于对数和x是正相关的,在最后判断的时候只需比较取对数后的结果大小即可。
3.
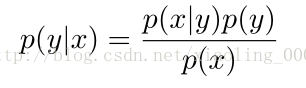 我们通常是运用这个式子进行计算,但是由于分母一样,所以我们常常会舍去分母,但是这样的话是否为垃圾邮件的概率两者想加不为1,所以要都计算,在比大小,判断是否为垃圾邮件
我们通常是运用这个式子进行计算,但是由于分母一样,所以我们常常会舍去分母,但是这样的话是否为垃圾邮件的概率两者想加不为1,所以要都计算,在比大小,判断是否为垃圾邮件
我们通常是运用这个式子进行计算,但是由于分母一样,所以我们常常会舍去分母,但是这样的话是否为垃圾邮件的概率两者想加不为1,所以要都计算,在比大小,判断是否为垃圾邮件
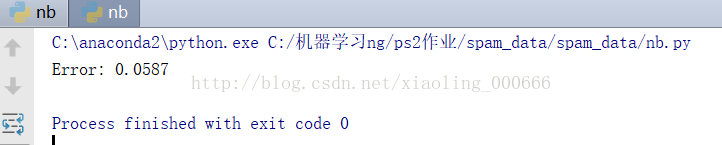
可以看出朴素贝叶斯模型的误差还是比较小的,有95%左右的正确率。
# -*- coding: utf-8 -*-
import numpy as np
def readMatrix(file):
fd = open(file, 'r')
hdr = fd.readline() #第一行数据
rows, cols = [int(s) for s in fd.readline().strip().split()] #读取第二行数据,以空格分割转化为列表s储存并让rows等于列表中第一个元素,并让cols为列表中第二个元素
tokens = fd.readline().strip().split() #读取第三行数据,以空格分开储存在列表tokens中
matrix = np.zeros((rows, cols))
Y = []
for i, line in enumerate(fd): #i代表位置,line代表字母
nums = [int(x) for x in line.strip().split()] #nums是提取的数字
Y.append(nums[0]) #Y代表是否为垃圾邮件
kv = np.array(nums[1:]) #kv为后列数据
k = np.cumsum(kv[:-1:2])
v = kv[1::2]
matrix[i, k] = v #训练数据中matrix为2144*1448,tokens为1448,y为2144,一共2144个数据,1448个特征x
def nb_train(matrix, list,category):
state0 = [0] * len(list)
state1 = [0] * len(list)
count_state0=0
count_state1=0
for i in range(len(matrix)):
if category[i]== 0:
state0 = state0 + matrix[i]
count_state0=count_state0+1
else:
state1 = state1 + matrix[i]
count_state1=count_state1+1
state0=state0/(len(matrix)*len(matrix[0]))
state1=state1/(len(matrix)*len(matrix[0]))
for i in range(len(state0)): #laplace平滑
if state0[i]==0:
state0[i]=float(1)/(len(matrix)*len(matrix[0])+len(matrix))
for i in range(len(state1)): #laplace平滑
if state1[i]==0:
state1[i]=float(1)/(len(matrix)*len(matrix[0])+len(matrix))
proportion_state0=float(count_state0)/(count_state0+count_state1)
proportion_state1=float(count_state1)/(count_state0+count_state1)
return state0,state1,proportion_state0,proportion_state1
def nb_test(matrix,state0, state1, proportion_state0, proportion_state1): #测试数据中matrix为800*1448,tokens为1448,y为800,一共800个数据,1448个特征x
output = np.zeros(matrix.shape[0]) #对于普通概率取对数
output0=[]
output1=[]
for i in range(len(matrix)):
possibility0=0
possibility1=0
for j in range(len(matrix[0])):
while matrix[i][j]>=1:
possibility0 = possibility0+np.log(state0[j])
possibility1 = possibility1+np.log(state1[j])
matrix[i][j] = matrix[i][j]-1
possibility0=possibility0+np.log(proportion_state0)
possibility1=possibility1+np.log(proportion_state1)
output0.append(possibility0)
output1.append(possibility1)
for i in range(len(output1)):
if output0[i]<output1[i]:
output[i]=1
else:
output[i]=0
return output
# def nb_test(matrix,state0, state1, proportion_state0, proportion_state1): #测试数据中matrix为800*1448,tokens为1448,y为800,一共800个数据,1448个特征x
# output1 = np.zeros(matrix.shape[0]) #利用普通朴素贝叶斯算法,出现了过多概率为0的位置
# for i in range(len(matrix)):
# possibility=1
# for j in range(len(matrix[0])):
# while matrix[i][j]>=1 :
# possibility=possibility*state0[j]
# matrix[i][j] = matrix[i][j]-1
# possibility=possibility*proportion_state0
# output[i]=possibility
# return output
def evaluate(output, label):
error = (output != label).sum() * 1. / len(output)
print 'Error: %1.4f' % error
def main():
trainMatrix, tokenlist, trainCategory = readMatrix('MATRIX.TRAIN')
testMatrix, tokenlist, testCategory = readMatrix('MATRIX.TEST')
state0, state1, proportion_state0, proportion_state1 = nb_train(trainMatrix,tokenlist,trainCategory)
output = nb_test(testMatrix,state0, state1, proportion_state0, proportion_state1)
evaluate(output, testCategory)
return
if __name__ == '__main__':
main()














 688
688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









