人脸检测之一:样本准备
基于机器学习方法的人脸检测,通常需要固定大小的人脸图像样本作为训练用的正样本,不包含人脸的样本作为负样本。训练过程是一个监督学习的过程,通过特定的特征提取和学习规则的制定,让计算机计算出最有效的将两类样本区分开来的数据,这些数据最为自动检测系统的最终配置加以存储,在真正检测的时候,对于任意输入图像,系统可以调用存储好的数据(知识),对图像加以判断,从而得出样本属于‘+’或‘-’的结论。
模式识别问题总是和统计学紧紧相联系的,它所得出的结论往往不是绝对的1或0,只能说是1的概率是多少,是0的概率的多少。所以天气预报会有“降水概率为80%”这种听起来模棱两可的说法。预报出错的情况在所难免,就像所有的模式识别问题都会有false alarm和false positive一样,这就需要对模式识别的结果有理性的认识。喜欢钻牛角尖的人从事这项工作就很容易抑郁,因为往往有这种情况:你花了很大工夫设计的算法,仍然无法在识别率达到100%的同时又没有出现任何错检。所以不能总盯着那些一时无法解决的“特例”,要用一种权衡的思想通盘考虑问题。一个好的识别系统,应该是好的算法加上好的权衡。
人脸样本一般是用手工的方法从一幅包含人脸的照片上截取的,然后在缩放成统一的尺寸,比如16×16或20×20。这个过程需要一些耐性,即使设计一个专门的小程序来选取人脸位置并自动缩放,对于几千个样本,重复这样的操作也不是一件轻松愉快的事。好在我们从这个网址找到了现成的训练样本
http://www.cmucam.org/wiki/viola-jones ,它包含两个.pat文件(链接已经失效,pat文件可以直接
下载),分别存储两类图像样本,每个样本是24×24的灰度图像。这些样本是Viola-Jones 2001年论文里用的训练样本,从里面甚至可以找到很多熟悉的面孔。
利用附件里的matlab程序读出这些样本,正样本为:
psams = getsamples('faces.pat',24);
psams是3维矩阵,维度是24*24*4916,每个样本沿着z方向存放,可以用下面命令显示其中的某个样本:
imshow(psams(:,:,6));%显示第6个样本
同样负样本用下面语句读出:
nsams = getsamples('nonfaces.pat',24);
这只是很少的一部分负样本,对于一个鲁棒的系统来说远远不够,需要在训练过程中不断加入新的负样本。
并且还可以把它们拼成一个大图,写论文的同学可以从上面截一块出来,插到文章里:“看,我用的人脸样本是这样的”:
tilesamples(psams,'faces.bmp');
tilesamples(nsams,'nonfaces.bmp');
部分正样本如下:
把样本存储成3维矩阵的好处是,提取特征的运算可以充分利用矩阵运算功能,而不用循环处理每个图像。比如正样本的平均值可以用:
meanface = mean(double(psams),3);
imshow(meanface,[]);
平均脸的结果是这样的:
以下附件是从打包存储的样本文件.pat中读取人脸矩阵的matlab小程序:
getdata.rar
在著名英语教材新概念英语第四册里,有一篇关于回声定位的文章,提到:根据回声的模式,不光能定位鱼群,而且可以知道鱼群的种类,比如青鱼,还是鳕鱼。(With experience, and with improved apparatus, it is now possible not only to locate a shoal but to tell if it is herring, cod, or other well-known fish,by the pattern of its echo.)对于深海捕鱼的实际环境,定位鱼群唯一可资利用的信息就是回声信号的pattern,对鱼群的定位和识别,实际上变成对回声模式的定位和识别。对于人脸检测和识别问题,针对人脸图像pattern来进行分析是比较廉价和实用的方法。信号模式作为原始数据,要经过特征提取和特征分类两个步骤才能得到最终结果。对信号提取有代表性的信息,即特征,把pattern从数据空间转换到特征空间进行分类是模式识别一般的工作方式。
对于图像来说,除了提取均值方差等统计学里比较常用的信息之外,更多地还要利用信号处理领域常用的卷积(模板不动就是内积)方法。图像处理教材中关于图像滤波(去噪),差分(边缘提取)等方法,以及DCT变换,傅立叶变换和小波变换等都可以看作是二维卷积方法的具体应用。比如PCA方法中使用的KL变换,就是用若干模板和图像进行内积计算(点乘),每个内积结果可以看作一个特征,它的作用是方便地提取图像的能量成分,优点是全局性好,倾向于图像表达,因为根据这些特征值很容易重建原始图像。想想视频编码所用的和KL变换相似的DCT变换吧,它们的目的在于重建而非识别。另外基于全局的方法需要每个图像点都参与计算,对一个8×8的图像来说,一次内积的计算量为64次乘法和63次加法。
所以,基于局部计算的小波(wavelet)特征的优势就比较明显了:只计算有可能产生分类效果的局部特征,如果用很少的特征能把两类模式区分开,就不必需要全体图像的参与。比如最简单的Haar小波算子,或称模板:{-1,1},它的作用是计算两个图像点的差。如果要计算两个区域的差算子可以是这样:{-1,-1-1,-1,1,1,1,1},它的作用是一个区域的和减去另一个区域的和,对于一个8×8的二维区域也需要64+1次加(减)法,如果这样的特征出现在图像的不同位置,计算量也是很大的。实际上,用积分数组可以很容易的计算。
积分数组是指一个和原始信号相同尺寸的数组,对一维信号来说,它的每个点存储的都是左边的原始信号的和。Matlab中的cumsum()函数作用就是计算积分数组。
>> x=rand(64,1);
>> xc=cumsum(x);
>> plot(x),hold on,plot(xc,'r');
信号x和它的积分数组xc结果如图:
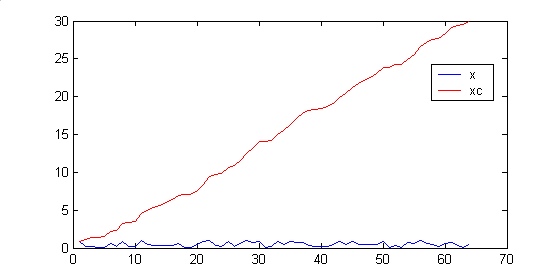
积分数组xc的作用是如果对x中任意一个区间(a,b]求和,只要计算xc上ab两点的差即可。例如计算点15到35点间的和:
>> sum(x(15:35))
ans =
10.7401
>> xc(35)-xc(14)
ans =
10.7401
对于一个2D图像im求积分数组,只要沿着图像x,y方向做两次cumsum:imc=cumsum(cumsum(im1,1),2);
im=rand(64);
imc=cumsum(cumsum(im,1),2);
imshow(im,[]);
imshow(imc,[]);
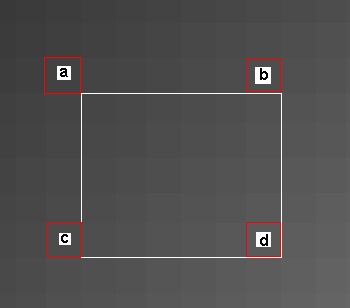
这样要求im中矩形对应的面积的话,只要在imc中计算 a+d-b-c 即可,也就是说任意大小区域的求和,只要3次加法即可实现。在viola-jones的论文中,特征定义为相邻两个(也有3个或4个)区域面积的差,称为Haar-like小波特征,可以用积分数组算法快速求得。对于一个24*24的图像样本,在不同位置计算不同尺寸、方向的Haar-like小波,这样可能的特征的数目在10万数量级。可以用一个程序穷举出文章描述的特征的各种配置(见附件),每种配置包含Haar小波的种类1-5(特征可能有2到4个矩形组成,2个和3个矩形的特征各有水平竖直2种方式),特征矩形左上角在样本中的位置的坐标,特征中单个小方块的长宽,这样每个特征需要5维矢量进行描述。10万个特征种类,我们可以事先计算好,用10万×5的矩阵存储下来。具体方法如下:
>> ft=generate_featuretype(24,[1,2,3,4,5],1,1,[1:24]);
>> size(ft)
ans =
162336 5
显示其中的若干行:
>> ft(2000:2006,:)
ans =
1 5 6 5 1
1 6 6 5 1
1 7 6 5 1
1 8 6 5 1
1 9 6 5 1
1 10 6 5 1
1 11 6 5 1
第1列表示两矩形的水平haar特征,2,3列表示左上角在24×24样本中的坐标,4,5列是一个矩形的尺寸。
实际上根据文章提供的特征描述的启发下,我们可以扩展出更多的类似两个矩形之间面积差的特征来。如果我们不限制两个矩形是“相邻”的话,需要有另外两个数来表示两个矩形之间的相对位置,这样的组合爆炸可以得到更多的特征表达。
上面提到用10万×5的矩阵存储一个表,每行是一个特征的描述,有10万个可能的特征,我们用每个特征的描述在24×24样本上都可以计算出一个特征值。假设我们有正负样本各5千,这样每个样本可以得到10万个特征值;对于单个特征类别每个特征在样本集上计算可以同样得到一个特征矢量。也就是说有这样一个表,可以把所有样本的所有特征值存储起来:

从水平方向看,它的每行对应一个样本;纵向看,它的每列对应一个特征种类在所有样本上的表现,是具有统计意义的。所谓训练,就是要利用这样庞大的2D数据,把那些能将两类样本加以区分出来的特征找出来,也就是说,从上面所说10万特征中,得到一个子集,它们最能体现出两类样本的差别。假设为了保留尽可能多的信息,我们用double型表示每个特征,那么存储量为8*1e9/1024/1024 = 7629.4 MByte,实际上可以先将数据量化,比如表示成8位unsigned char的形式,那么存储量就只有原来的1/8。另外,如果设计的最终分类器是分层结构的(应该是这样的),每层只需要提取很少的几个或几百个有用的特征,那么完全可以减少候选特征的数量;更进一步,样本数目也可以进一步减少(这样做也是有科学依据的,5k个分布均匀的样本可能和w个样本具有相同的代表性),这样上面这个表的水平竖直维数都可以大大减少,从而减少存储量。
相关文献:
[1] Viola-Jones论文 Robust Real-time Object Detection
附件:generate_featuretype.m
穷举出特征计算参数配置的程序。在Viola-Jones论文中,第4页注释2提到特征数为45396个,他们的特征位置为样本图像的奇数点,所以只有全部的1/4左右。
人脸检测之三: 贝叶斯公式.概率分布
设计一个模式识别系统需要确定两件事:第一件,用什么模式特征进行比较?提取那些能有效区分类别的特征,让同类样本在特征空间中尽量挤在一起,而让不同类别的样本间距离尽量远。(这里的“距离”根据不同的测量方法而有所不同,但总是希望通过某些方法把特征变换到线性空间中,毕竟欧式距离是比较直观的观察方法。)比如,在一个锅里炒黑豆子和白豆子(不止两颗),要想把他们分成黑豆和白豆两堆,比较好的特征是颜色;把大白菜和甘蓝菜分成两堆的特征是形状。如果白菜的“圆度roundness”是一种度量测度,用一个坐标轴表示,那么白菜们的这个特征在坐标轴上的位置应该是扎堆(clustering)的。如果有多种特征,每个特征对应一个坐标轴,组成的一个特征空间,它可能是很多维的高维空间。 第二件事,设计分类器。在特征空间中画一条线,线左边是大白菜,右边是甘蓝菜,这条线就是分类器。困难在于,两类模式在特征空间中的交界并不总是很明显。两类样本尽管聚类,比如呈现出高斯分布,但边界的地方两类是混在一起的。如果特征选择得不够好,这种不可分的情况就更加不可避免。模式分类问题其实都可以归结为"分大白菜哪点事"。
对于人脸检测问题,两类目标分别为人脸(正样本'+')和非人脸(负样本 '-'),也需要经过对图像提取特征和设计分类器两个串行步骤,现有的部分方法可以列一个表,比如:
特征 | 分类器
————————————
pca降维 | AdaBoost
小波分解 | NN(神经网)
Haar-like小波| SVM(支撑向量机)
HOG | 贝叶斯分类法
LBP |
...... | ......
原则上左右两边任选两项都可以组成一个图像识别系统,学术期刊(国内的更多些)上多如牛毛的文章几乎就是这么任意组合来的。实际上这也仅仅是一小部分,每种方法都能衍生出许多变化。经常听到某人听说某人的系统用了“神经网络”,这话提供的信息实在有限,因为他没有说他用的是什么特征,还有是什么神经网,是RBF网,还是BP网,如果是BP网那么有几层,每层都什么配置。久而久之,“神经网”,“SVM”这些词的滥用让它们都有被妖魔化的趋势。
我们的方法可以这样准确地描述,“Viola-Jones的Haar-like小波,加上经过Boosting的Naive Bayes组合分类器”,可真够罗嗦的。Haar-like小波特征我们在上节有介绍,用matlab计算比较方便,比如我们有若干24×24的样本图像组成一个3D矩阵samples, xy方向是图像平面,沿着它的z方向可以遍历所有样本,比如samples(:,:,7)表示第7个样本。所有样本的积分图像(积分数组)分两步计算:
cumsam = cunsum(cunsum(samples,1),2);
对所有样本计算一个矩形特征的方法也可以利用矩阵特性批量进行,假设矩形由a,b,c,d四点组成:
f1 = cumsam(ay,ax,:)+cumsam(dy,dx,:)-cumsam(by,bx,:)-cumsam(cy,cx,:);
另一个矩形特征为f2,则一个Haar小波特征为 fv = f1 - f2.
以上是对上一节特征提取具体计算方法的补充。接下来,因为上边提到的特征数目太多(10万多),希望从大量的特征feature pool)中选取有效的特征,原则是两类样本在这个特征轴上的分布尽可能离得远些,越远越好。“训练(training)”过程是个离线的过程(离线又是个什么东西?离线offline是相对于“在线online”说的,表示这种过程是在生产线下完成的,可以不计时间代价,“我可以等!”。训练好的模型,是需要用在实际检测中的,所以需要越快越好,叫“在线”。),就是从这个pool中打捞有用的特征,它们单个的分类能力尽管有限,但它们的组合,可以很强大。如何评价每个特征分布的好坏?用Bayesian 把每个都试一试看,看看哪个特征两类的分布差距最大。
贝叶斯公式,据我粗浅的认识应该是指:类别对于特征的后验概率正比于该类别在这些特征分布下的条件概率(就是上述特征分布)乘以该类的先验概率(比如世界人口的男女比例)。用公式表达: P(wi | f1,f2,...fn ) = p(f1,f2,...fn | wi ) * p(wi),wi表示很多类中的第i类,f1,...,fn表示。它的意思是,在给定特征值 f1,f2,...fn的情况下,属于类别wi的概率是多少。比如我们有m个类别,对于每个wi,i=1...m,都可算出一个概率,选其中最大的,对应的那个wi就是最终的类别,这个唤作“最大化后验概率(MAP)”。对于每个类别,都可以根据采集到的样本实现知道特征分布函数p(f1,f2,...fn | wi ),有几类就有几个这样的分布函数,叫概率分布函数(pdf)。对于人脸检测这样的两类问题(w+和w-),贝叶斯分类器可以用两类后验概率的比值表示,
f(f1,...fn) = P(w+ | f1,f2,...fn )/P(w- | f1,f2,...fn ) ,
这个值越大,越倾向于正样本,通常用一个阈值决定是'+'还是'-',另外p(w+)和p(w-)的比值可以认为是固定的和特征无关,最终分类器表示为条件概率的比值的形式:
f(f1,...fn) = p( f1,f2,...fn | w+ ) / p( f1,f2,...fn | w- )
对于组合特征f1,f2,...fn 的分布函数p( f1,f2,...fn | w+ )进一步简化的方法是,在假设n个特征统计无关的情况下,可以用每个特征的特征分布的连乘的形式来表达:
p( f1,f2,...fn | w+ ) = p( f1 | w+ ) × p( f2 | w+ ) ×... × p( fn | w+ ) ;
这部分具体可参考概率论相关书籍。所谓统计意义的不相关,是指每个特征呈现的分布不是由其他特征决定的,是独立的p(f1|f2,...,fn) = p(f1), 这样的独立性假设是保证每个特征对分类的贡献都不受其他特征影响,它的反面则是指它提供的信息是冗余的。就象在班会上,程老师让大家发表对某项班级活动的看法,在老薛发言之后,我站起来说:“我完全同意薛同学的看法“。这样我的意见就不包含任何有用的信息(除了暴露了我其实并不关心这样的活动),是高度冗余的。
虽然实际上f1,f2,...,fn之间并非总是相对独立的,但还是假设上式勉强成立,这个一般叫做Naive Bayes(Naive 这个字源自法语,Too simple, sometimes naive.)。实际上,我们提到的AdaBoost方法就是尽量去除数据之间的相关性的。这样分类器表示为:
p( f1 | w+ ) × p( f2 | w+ ) ×... × p( fn | w+ )
f(f1,...fn) = ------------------------------------------------------
p( f1 | w- ) × p( f2 | w- ) ×... × p( fn | w- )
上式左右两边取对数,这样讨厌的乘除法就变成加减法了:
ln(f(f1,...fn)) = [ln(p( f1 | w+ )) - ln(p( f1 | w- )) ] + ....+ [ln(p( fn | w+ )) - ln(p( fn | w- )) ] ;
其中ln(p( fj | w+ ))是某个特征的概率分布函数p( fj | w+ )的对数形式,p( fj | w+ )如果用参数化的形式表达成比如高斯分布或者混合高斯分布的形式的话,那么只用若干参数就可以表达了,但是它们并不是服从高斯分布的,所以通常用非参数的方法表达,那就是直方图。把ln(p( fj | w+ )) - ln(p( fj | w- )) 表示成一个直方图,表示每个特征的置信度,那么人脸检测就变成这样一个过程:
1 在输入的一个图像区域里,计算若干特征;
2 根据每个特征查表,在直方图里找到对应的置信度值;
3 把这些特征对应的置信度值求和,用一个阈值Th决定输出为‘+’或‘-’。
实际上不论用什么特征,什么分类器(神经网,SVM),它们最终的形式都可以表示成一组特征数据的加权和,以及一个最后的判决阈值Th的形式:
if ( SUM ( H(fj) ) >Th ) , j = 1, .. .., n, n个特征
wi = face;
else
wi = nonface;
下节将介绍特征分布的直方图是如何被用来选取特征,并最终组合成分类器的。
以上方法都不是我想出来的,我只是用白话写写我的理解。参考文献如下:
[1] 边肇祺, 《模式识别》
[2] Tom M.Mitchell, Machine learning (《机器学习》 )
[3] Bo WU, Haizhou AI, Chang HUANG, Shihong LAO, Fast Rotation Invariant Multi-View Face Detection Based on Real Adaboost, In Proc. the 6th IEEE Conf. on Automatic Face and Gesture Recognition (FG 2004), Seoul, Korea, May 17-19, 2004.
http://media.cs.tsinghua.edu.cn/~imagevision/publications.htm
人脸检测之四: 直方图.AdaBoost
先撇开人脸检测问题,来看看直方图。
一.用带权重的样本统计直方图
直方图Histogram,是一种常见的概率分布的非参数(区别于高斯分布,泊松分布等用参数表达概率密度的方法)表达方法。直方图可以看成概率密度分布的离散化表达方法。它的计算很简单,是一种投票的方法,就是每个样本往对应的小盒子(bin)里投一票。假设N个样本数据x量化为1~M之间的整数,那么Hist是M维数组,对应的直方图计算方法如下:
//initializing
for i=1:M
Hist[i] = 0;
end
//voting
for i = 1:N
Hist[x[i]] += 1 ;
end
为了表示成概率分布,需要Hist数组和为1:
//normalize
for j = 1:M
Hist[j] = Hist[j]/sum(Hist) ; //sum(Hist) = Hist[1] + Hist[2] + ... + Hist[M];
end
在这里sum(Hist)等于样本个数N。以上“投票+归一化”两个步骤,其实可以和成一步,即每个样本x[i]有一个对应的权重w[i]=1/N,投票的时候往小盒子里放的是权重:
//initializing
for i=1:M
Hist[i] = 0;
end
//voting
for i = 1:N
Hist[x[i]] += w[i] ;
end
这样得到数组Hist里的每个值都是一个0-1之间的小数,表示当x取这个值(数组对应的下标)时候的概率。
二.样本权重的变化影响直方图形状
如果想改变一个概率分布取曲线的形状,比如,在训练的时候要强调x[i]=3的样本,一种办法是增加这种样本的个数,使Hist[3]变大,另一种方法是增加和它对应的样本的权重w[i],让某些样本产生“一个顶俩”的效果,这两种方式都能起到改变概率分布的作用。
对人脸检测这类基于图像的目标检测方法,需要搜集大量样本进行离线的训练,样本要尽可能覆盖所有可能的情况,从而使所提取特征的概率分布具有代表性,当样本数趋向于无穷大的时候,概率分布就趋向于真实的分布情况。但通常在实际中,样本数总是有限的,这时就可以
通过增加某些比较重要的样本的权重,来达到看起来是增加了某些样本数量的效果。
另外,直方图数组Hist的某个bin中的样本权重的改变,不应该仅仅影响当前的bin,也应该对周围相邻的bin造成影响。比如,在统计一个地区人群的身高分布的时候,如果只有一个样本x=1.65m,我们可以在Hist数组中对应1.6<=x<1.7这一个bin里投上一票,但是1.5<=x<1.6和1.7<=x<1.8两个bin的得票为0。其实不应该这样,根据身高应该是连续分布的这一假设,从样本x=1.65m可以安全地推断出世上也应该有身高1.59和1.71的人,这样左右两个相邻的bin的值就不应为0,应该也受到x=1.65m这个样本的影响,这种影响可以假设是服从高斯分布,即越远的bin受影响越小。这其实是另一种常见的概率密度估计的非参数方法,kernel density estimation(KDE)。我们的人脸检测应用由于样本足够多,所以没有考虑这一方法。也就是说,每个特征值在投票的时候,只对一个bin起作用,不影响相邻的那两个。
三.根据当前分类结果改变样本的权重并选择“好”的特征
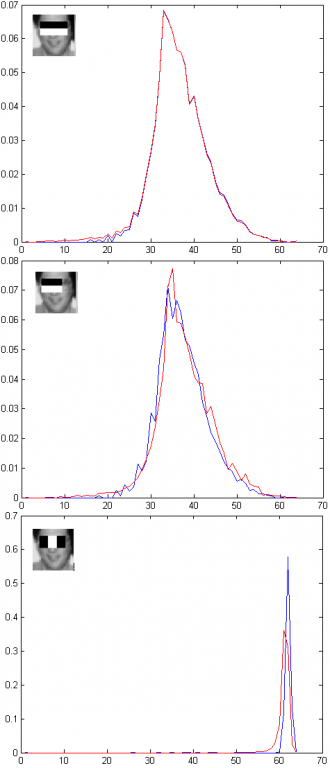
对于人脸检测问题,我们希望两类(faces and nonfaces)模式特征的分布离得比较远,或者看起来分得比较开。举例来说,假设我们在所有样本上提取如下3种特征,此时feature pool尺寸是3,我们要从里面选2个最好的特征:
这个图表示的是3种计算特征的方法,用矢量表示分别是[2,5,5,16,4],[2,5,5,12,4],[3,5,5,5,7]。每个矢量中5个数的含义是:[特征种类,矩形左上角坐标的x,y,单个矩形的宽,高];特征计算方法是白色矩形内的像素和减去黑色矩形内的像素和。其中第1个和第2个特征只在尺寸上有很小的差别,接下来的试验就是希望说明这两个特征的确是有很高的相关性的,在分类能力上是冗余的,而第3个特征和第1、2两个特征则基本上是不相关的。
我们先把这三个特征对于所有样本的概率分布(直方图的数组长度为64,也就是说特征值在所有可能的表达范围里量化为64级)画出来看看(蓝色曲线表示正样本,红色表示负样本):
可以看出所有特征的两类分布都有很大的重叠,如前所述,‘好‘的特征是指两个曲线的'差别'比较大。表达概率分布曲线之间的“距离”的度量方法有很多,参考论文中的方法是先计算两条曲线对应bin的几何平均值,然后求和(见参考文献的公式(3)),用matlab语言表达是这样:Z(h) = 2*sum(sqrt(wp.*wn)),wp和wn是表示两类直方图的数组。 可以看出这个值越小说明两类的差别越大。当曲线wp和wn完全重合的时候,z值最大,表示这个特征完全不具有分类能力;当两条曲线完全不重叠时,z值最小,表示这个特征的分类能力最强,用一个阈值就能把两堆白菜分开来。我们要从有许多特征里选出那些‘好’的特征,就是选取使z达到最小的那个。
我们现有的3个特征的z分别是1.6586,1.7384,1.7627,也就是说第1个特征最好。那么次好的特征是哪个?是第2个z=1.7384吗?答案是否定的,因为第2个特征和第1个特征太象了,因为特征采样的空间位置决定了他俩拥有很相似的概率分布,它和第1个特征都是高度相关的。接下来介绍的AdaBoost方法,就是要去掉这种相关性的影响,从而选出真正的第二个‘好特征’。具体方法是通过改变样本的权重:减小可靠的样本的权重,增大难以区分的样本的权重,利用权重改变后的样本集合进行下一轮的特征选择。
根据上一篇博客,Naive贝叶斯分类器的对数表达形式为:
ln(f(f1,...fn)) = [ln(p( f1 | w+ )) - ln(p( f1 | w- )) ] + ....+ [ln(p( fn | w+ )) - ln(p( fn | w- )) ] ;
其中hp =[ln(p( f1 | w+ )) - ln(p( f1 | w- ))] 可以看成是特征f1的置信度曲线,它是曲线wp和wn的相同x坐标处的p值的比值的对数。也就是说,当我们计算得到一个样本的特征值,在这个曲线上查表,如果ln(p( f1 | w+ ))>ln(p( f1 | w- )),表示样本更象人脸,置信度结果为正数;当ln(p( f1 | w+ ))<ln(p( f1 | w- )),样本更象非人脸,置信度结果为负数;当ln(p( f1 | w+ ))=ln(p( f1 | w- ))置信度为0。
当我们选出一个特征后,可以根据每个样本的置信度hp决定如何改变它的权重,对于正样本假设它的权重为Dp ,权重改变方法为:Dp = Dp.*exp(-1*hp); 对于负样本,为Dn = Dn.*exp(1*hn)。
在我们的例子中,现在第一轮特征选择已经选出第1号特征z(1)=1.6586为最好特征,按照 [ln(p( f1 | w+ )) - ln(p( f1 | w- )) ] 得到每个样本的置信度值,改变样本权重后,上面3个特征的概率分布(直方图)变成下面的曲线了:
可以看出,特征1的两类样本曲线完全重合在一起,特征2则几乎重合在一起了,而特征3几乎没有任何变化。也就是说,特征1完全变成一个没用的特征了,而 权重的变化对特征3影响不大。这个第二轮特征选择过程,曲线间“距离”度量z重新计算后分别为 1.6586,1.6454, 1.4163,可见第二轮计算3号特征是最好的。第1个特征完全废掉了,第2个特征也几乎废了,就因为它和第1个特征太象了(高度冗余的)。
这种利用现有分类器(这里是指特征的置信度曲线)改变样本权重,再进行下一轮特征选取的训练方法,统称为AdaBoost(Adaptive Boosting)。这里的根据样本置信度改变权重的方式称为RealAdaboost。每个特征的置信度hp其实都可以看成一个分类器(比如hp大于一个阈值,则为人脸),只是这样的分类器的分类能力很低,称为弱分类器。训练过程,就是从feature pool中选取好的特征(弱分类器),组成最终的强分类器。
四.串联若干强分类器组成最终的分类器
上一篇博客提到,一个强分类器的最终形式是把若干特征的置信度相加:
if ( SUM ( H(fj) ) >Th ) , j = 1, .. .., n, n个特征
输出 face;
else
输出 nonface;
对于人脸检测系统特征个数可能达上千个,在进行实际的人脸检测的时候,一个照片要送到分类器中进行确认的图像块个数往往数以百万记,而其中真正包含人脸的往往很少,只有几十或几百个,也就是说,非人脸的先验概率远远大于人脸。这样就希望有一种机制,可以通过计算少量特征就快速地拒绝掉那些肯定不是人脸的样本。在训练的时候,我们发现仅仅使用最好的2个特征组合的强分类器,可以在保证几乎100%检测率的情况下,拒绝掉几乎50%的负样本。这样,最终的人脸检测系统,是由若干强分类器串联而成的,象一个向一边生长的二叉树,每个强分类器只负责把样本分成“非人脸”和“有可能是人脸”两类,对于后一类样本再送入到下一个强分类器。就象很多叠在一起的筛子一样,只有通过最下面一个筛子的样本才被判断为人脸。而论文中,这种机制称为cascade。
假设每个强分类器的检测率为99%,错检率为50%(拒绝掉50%的非人脸),假设我们有10级强分类器串联,最终的分类器的检测率为0.99^10=0.9044,错检率为0.50^10=9.7656e-004。实际训练的初始化阶段,每层强分类器要给定的参数是1检测率,2错检率或3样本个数中的某两个。
两类训练样本假设为5000和1万,每层检测率为99%,错检率为50%,程序自动选取了若干特征组成两层结构的分类器。由于每层都拒绝掉50%的负样本,第3层训练开始的时候,正样本还有4900,负样本只剩下2500,太少了。这时,要做一件事,就是利用现有的分类器做为人脸检测器,在不包含人脸的图像样本中搜集负样本(其实就是这个半成品人脸检测器的错检结果),作为下一层训练的负样本。这个重新采样搜集负样本的过程称为Bootstrapping,在数据挖掘和模式识别领域是常用的一个操作步骤。试验中看到的有趣的现象是,越是处在后面的强分类器的负样本越是看起来象人脸,也需要更多的弱特征组合才能得到一个不错的强分类器。
参考文章:


























 5990
5990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









