









最近想找一个用来管理scrapy项目的界面或系统,于是发现了scrapyd,也许会有用。
在scrapy项目的目录下,在命令行中运行scrapyd就能打开scrapyd。
然后在浏览器中打开http://localhost:6800/ 就能进入scrapyd界面。
之后在我安装的curl目录下(在学Elasticsearch时安装),用curl运行了几个 scrapyd 提供的 json API,都没有出现应该出现的结果。几个例子如下:
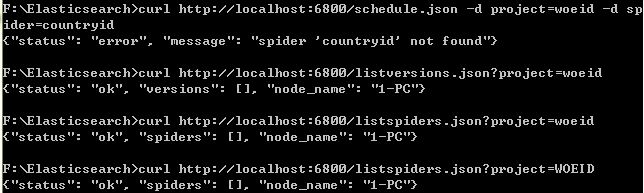
之后上网找到一个scrapyd-client的包,用于控制scrapyd的使用。在cmd中,需要用 scrapyd deploy <...> 命令进行操作















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









