







所有示例代码打包下载 : 点击打开链接
Java8新特性 :
- 接口新增默认方法和静态方法
- Optional类
- Lambda表达式
- 方法引用
- Stream API - 函数式操作流元素集合
- Date/Time API
- 新API和工具
- Nashorn , JavaScript引擎
5 . Stream API - 函数式操作流元素集合
Stream流是Java8 API的新成员 , 它允许你以声明的方式处理数据集合(通过类似SQL的查询语句来表达 , 而不是临时编写一个实现) . 就现在来说 , 你可以把它们看成遍历数据集的高级迭代器 , 熟练应用之后 , 在大部分情况下你都不需要再写循环去遍历集合了 . 此外 , 流还可以透明的并行处理 , 也不需要写任何多线程代码了 . 这是目前为止最大的一次对Java库的完善 , 颠覆了Java8之前的代码书写风格 . 例如 , 对集合中的每个元素进行运算并转换为另一个集合
List<Integer> oldList = Arrays.asList(1 , 2 , 3 , 4 , 5);
List<String> newList1 = new ArrayList<>();
//Java8之前
for(Integer i : oldList){
newList1.add(i * 100 + "分");
}
//Java8
List<String> newList2 = oldList.stream().map(i -> i * 100 + "分").collect(Collectors.toList());
}Stream的风格就是将要处理的元素集合看成一种流 , 流在管道中传输 , 并且在管道中不同的节点上进行处理 , 比如筛选 , 排序 , 聚合等 , 然后输出最终符合我们需求的集合数据 . 即元素流在管道中经过中间操作(intermediate operation)的处理 , 最后由最终操作(terminal operation)得到前面处理的结果 . 由于Stream过于强大 , 我们这里只将常用的做一下说明
5.1 生成流
在Java8中 , 集合接口有两个方法来生成流 :
Stream<String> stream1 = list1.stream();//Stream<T> stream();为集合创建串行流
Stream<String> stream2 = list1.parallelStream();//Stream<T> parallelStream();为集合创建并行流 , 在使用过程中 ,你也随时可以调用parallel()方法将一个串行流转为并行流Stream<Object> stream3 = Stream.builder().add(list1).build();
Stream<Object> stream4 = Stream.empty();
Stream<String> stream6 = Stream.of("111","222","333");//比较常用的就这一个
ArrayBlockingQueue<String> queue=new ArrayBlockingQueue<>(20);
queue.addAll(list1);
Stream<String> stream7 = Stream.generate(()->{
try {
return queue.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
return null;
});
Stream<String> stream8 = Stream.concat(list1.stream(), list1.stream());5.2 几个重要的方法
| 类别 | 方法 | 描述 | 备注 |
| 遍历 | void forEach(Consumer<? super T> action) | 遍历操作,遍历执行Consumer 对应的操作 | |
| 筛选/切片 | Stream<T> filter(Predicate<? super T> predicate | 过滤操作,根据Predicate判断结果保留为真的数据,返回结果仍然是流 | |
| Stream<T> distinct() | 去重操作,筛选出不重复的结果,返回结果仍然是流 | ||
| Stream<T> limit(long maxSize) | 截取限制操作,只取前 maxSize条数据,返回结果仍然是流 | ||
| Stream<T> skip(long n) | 跳过操作,跳过n条数据,取后面的数据,返回结果仍然是流 | ||
| 排序 | Stream<T> sorted(Comparator<? super T> comparator) | 对流中的元素进行排序 , 返回结果仍然是流 | |
| 映射 | Stream<R> map(Function<? super T, ? extends R> mapper) | 转化操作,根据参数T,转化成R类型,返回结果仍然是流 | |
| Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper) | 转化操作,根据参数T,转化成R类型流,这里会生成多个R类型流,返回结果仍然是流 | ||
| 匹配 | boolean anyMatch(Predicate<? super T> predicate) | 判断是否有一条匹配,根据Predicate判断结果中是否有一条匹配成功 | |
| boolean allMatch(Predicate<? super T> predicate) | 判断是否全都匹配,根据Predicate判断结果中是否全部匹配成功 | ||
| boolean noneMatch(Predicate<? super T> predicate) | 判断是否一条都不匹配,根据Predicate判断结果中是否所有的都不匹配 | ||
| 查找 | Optional<T> findAny() | 查找操作, 查询当前流中的任意元素并返回Optional | |
| Optional<T> findFirst() | 查找操作, 查询当前流中的第一个元素并返回Optional | ||
| 归约 | T reduce(T identity, BinaryOperator<T> accumulator) | 归约操作,同样两个类型的数据进行操作后返回相同类型的结果。比如两个整数相加、相乘等。 | |
| Optional<T> max(Comparator<? super T> comparator) | 求最大值,根据Comparator计算的比较结果得到最大值 | ||
| Optional<T> min(Comparator<? super T> comparator) | 求最小值,根据Comparator计算的比较结果得到最小值 | ||
| 汇总统计 | <R, A> R collect(Collector<? super T, A, R> collector) | 汇总操作,汇总对应的处理结果。 | |
| long count() | 统计流中数据数量 | ||
| 最终操作 | R collect(Collector<? super T, A, R> collector) | 通常出现在管道传输操作结束标记流的结束 |
Stream操作还有两个基础的特征 :
1 . 中间操作都会返回新的流, 这样多个操作可以串联成一个管道 , 即链式调用(参看jQuery) . 并且这样做可以对操作进行优化 , 比如延迟执行(laziness)和短路(short-circuiting) .
2 . 内部迭代 : 以前对集合遍历都是通过Iterator或者for-each的方式 , 显式的在集合外部进行迭代 , 这叫做外部迭代 . Stream提供了内部迭代的方式 , 通过访问者模式(Visitor)实现 .
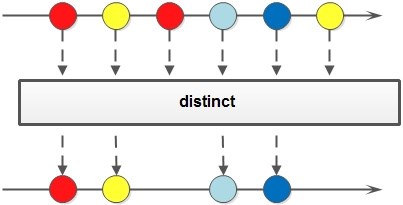
Stream.of(1,2,3,1,2,3).distinct().forEach(System.out::println); // 打印结果:1,2,3创建了一个Stream(命名为A),其含有重复的1,2,3等六个元素,而实际上打印结果只有“1,2,3”等3个元素。因为A经过distinct去掉了重复的元素,生成了新的Stream(命名为B),而B中只有“1,2,3”这三个元素,所以也就呈现了刚才所说的打印结果。
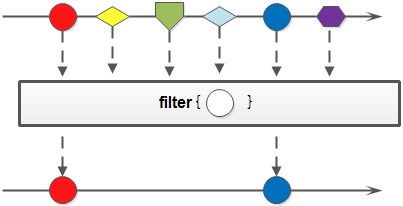
Stream.of(1, 2, 3, 4, 5).filter(item -> item > 3).forEach(System.out::println);// 打印结果:4,5创建了一个含有1,2,3,4,5等5个整型元素的Stream,filter中设定的过滤条件为元素值大于3,否则将其过滤。而实际的结果为4,5。
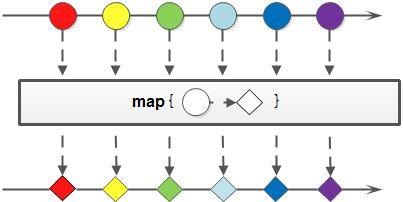
Stream.of("a", "b", "hello").map(item-> item.toUpperCase()).forEach(System.out::println);// 打印结果 A, B , HELLO传给map中Lambda表达式,接受了String类型的参数,返回值也是String类型,在转换行数中,将字母全部改为大写
flatMap:和map类似,不同的是其每个元素转换得到的是Stream对象,会把子Stream中的元素压缩到父集合中;
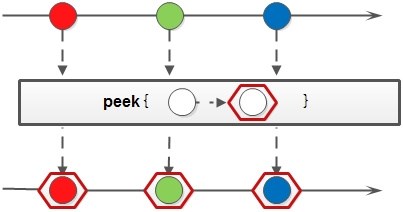
Stream.of(1, 2, 3, 4, 5)
.peek(integer -> System.out.println("accept:" + integer))
.forEach(System.out::println);
// 打印结果
// accept:1
// 1
// accept:2
// 2
// accept:3
// 3
// accept:4
// 4
// accept:5
// 5peek方法生成一个包含原Stream的所有元素的新Stream,同时会提供一个消费函数(Consumer实例),新Stream每个元素被消费的时候都会执行给定的消费函数,并且消费函数优先执行
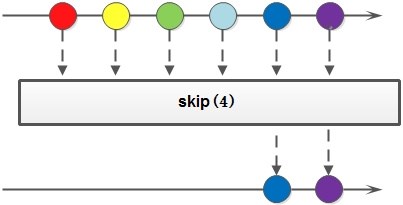
Stream.of(1, 2, 3,4,5).skip(2) .forEach(System.out::println); // 打印结果 3,4,5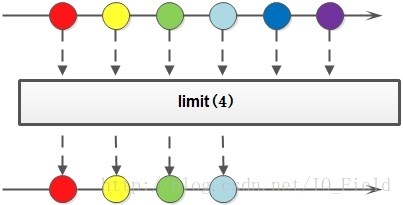
Stream.of(1, 2, 3,4,5).limit(2).forEach(System.out::println);// 打印结果 1,25.3 Collectors
Collectors类是一个非常有用的是归约操作工具类,工具类中的方法常与流的collect方法结合使用。比如 toList将结果Stream转成新的list , groupingBy方法可以用来分组,在转化Map时非常实用;partitioningBy方法可以用来分区(分区可以当做一种特殊的分组,真假值分组),joining方法可以用来连接,这个应用在比如字符串拼接的场景。其他常用的api还有toSet , toCollection , toMap等 , 关于更高级的用法 , 可以参看这篇博文 : http://blog.csdn.net/IO_Field/article/details/54971608
5.4 并行流
Collection接口的实现类调用parallelStream方法就可以实现并行流,相应地也获得了并行计算的能力。或者Stream接口的实现调用parallel方法也可以得到并行流。并行流实现机制是基于fork/join 框架,将问题分解再合并处理。
不过并行计算是否一定比串行快呢?这也不一定。实际影响性能的点包括:- 数据大小输入数据的大小会影响并行化处理对性能的提升。 将问题分解之后并行化处理, 再将结果合并会带来额外的开销。 因此只有数据足够大、 每个数据处理管道花费的时间足够多 时, 并行化处理才有意义。
- 源数据结构 . 每个管道的操作都基于一些初始数据源, 通常是集合。 将不同的数据源分割相对容易,这里的开销影响了在管道中并行处理数据时到底能带来多少性能上的提升。
- 装箱 . 处理基本类型比处理装箱类型要快。
- 核的数量 . 极端情况下, 只有一个核, 因此完全没必要并行化。 显然, 拥有的核越多, 获得潜在性能提升的幅度就越大。 在实践中, 核的数量不单指你的机器上有多少核, 更是指运行时你的机器能使用多少核。 这也就是说同时运行的其他进程, 或者线程关联性( 强制线程在某些核或 CPU 上运行) 会影响性能。
- 单元处理开销 . 比如数据大小, 这是一场并行执行花费时间和分解合并操作开销之间的战争。 花在流中每个元素身上的时间越长, 并行操作带来的性能提升越明显 .
注 : 关于中间操作和最终操作 , 也有人称之为惰性求值方法和及早求值方法 . 像filter这样只描述Stream,最终不产生新集合的方法叫作惰性求值方法;而像count这样最终会从Stream产生值的方法叫作及早求值方法 .
在一个Stream操作中,可以有多次惰性求值,但有且仅有一次及早求值
为什么要区分惰性求值和及早求值? 只有在对需要什么样的结果和操 作有了更多了解之后, 才能更有效率地进行计算。 例如, 如果要找出大于 10 的第一个数字, 那么并不需要和所有元素去做比较, 只要找出第一个匹配的元素就够了。 这也意味着可以在集合类上级联多种操作, 但迭代只需一次。这也是函数编程中惰性计算的特性,即只在需要产生表达式的值时进行计算。这样代码更加清晰,而且省掉了多余的操作。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









