






目录
判断:anyMatch、allMatch和noneMatch
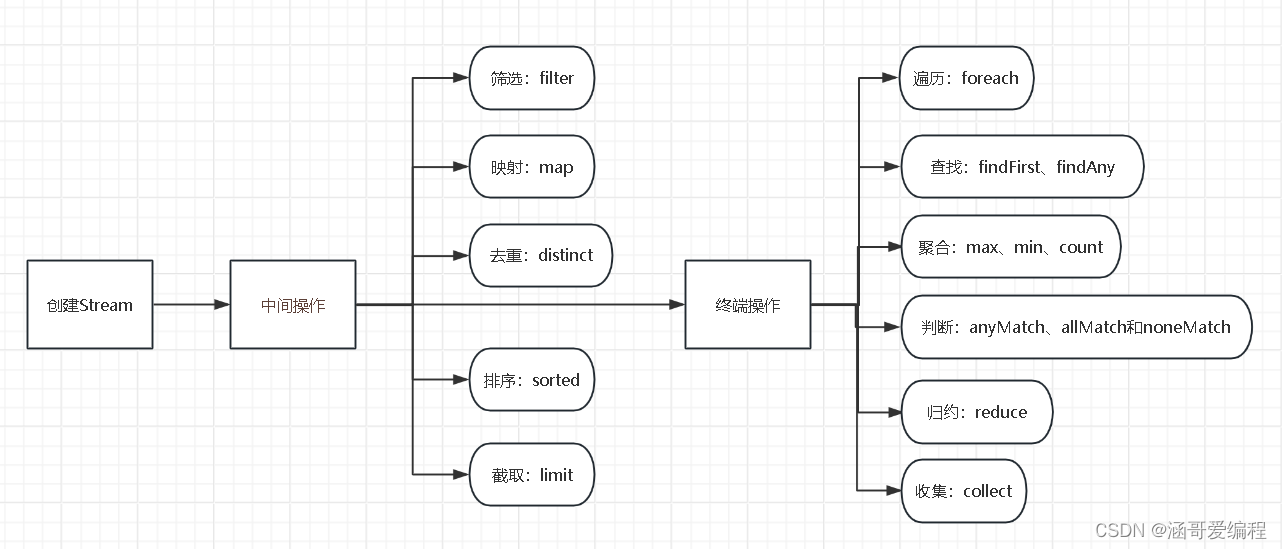
Stream概述
Stream是一种用来处理集合的新方法,它可以把集合中的元素看作是一条流,流可以在管道里进行各种操作,比如筛选、排序、聚合等。Stream的优点是可以简化代码,提高效率,支持并行处理,还可以延迟执行。
常用操作
温馨提示:在stream流中都是lambda表达式的表现,如果有不懂lambad表达式的,可以先去学习这篇:
Lambda表达式&Stream流(从入门到精通,通俗易懂)
Stream的创建
Stream流的创建可以通过集合或数组来创建。例如,List.stream() 方法可以将一个集合列表转换为一个 Stream流。
集合创建流
集合对象.stream()或者parallelStream()方法
List<String> list = Arrays.asList("a1", "a2", "b1", "c2", "c1");
// 创建一个串行流
Stream<String> stream = list.stream();
// 创建一个并行流
Stream<String> parallelStream = list.parallelStream();
串行流也可以转换成并行流:
Stream<String> stream = list.stream().parallel();
一般情况下,对于小规模数据,串行流可能更快,而对于大规模数据,并行流更有优势
数组创建流
Arrays.stream(数组) 或 Stream.of(数组) 来创建
Integer[] arr = {1,2,3,4};
Stream<Integer> stream1 = Arrays.stream(arr);
Stream<Integer> stream2 = Stream.of(arr);中间操作
这是对 Stream 进行一系列转换的步骤,比如筛选、映射、排序等。这些操作不会修改原始数据,而是返回一个新的 Stream
筛选:filter
List<Integer> numbers = Arrays.asList(7, 6, 9, 3, 8, 2, 1, 9, 6, 7);
// 筛选大于5的数
List<Integer> filteredList = numbers.stream()
.filter(x -> x > 5)
.collect(Collectors.toList());
System.out.println("筛选结果: " + filteredList);
输出结果:筛选结果: [7, 6, 9, 8, 9, 6, 7]
映射:map
将流中的每个元素传入给定的函数,得到一个新的流。
Stream<String> stream = Stream.of("one", "two", "three", "four");
// 转大写
stream.map(String::toUpperCase)
.forEach(System.out::println)
// 上面的写法与以下同等
// str 就是传进来的元素 比如第一个:one 第二个two 就跟for循环一样
stream.map(str -> str.toUpperCase())
.forEach(System.out::println);
结果:
ONE
TWO
THREE
FOUR
去重:distinct
List<Integer> numbers = Arrays.asList(6, 6, 7, 7, 8, 9, 9);
List<Integer> distinctList = numbers.stream()
.distinct()
.collect(Collectors.toList());
System.out.println("结果: " + distinctList);结果: [6, 7, 8, 9]
排序:sorted
List<Integer> numbers = Arrays.asList(7, 6, 9, 3, 8, 2, 1, 9, 6, 7);
//第一种 默认
List<Integer> sortedList = numbers.stream()
.sorted()
.collect(Collectors.toList());
System.out.println("默认排序结果: " + sortedList);
// 第二种 自定义排序
List<Integer> sortedList1 = numbers.stream()
// 如果是b.compareTo(a)则降序 a.compareTo(b)则升序
.sorted((a, b) -> b.compareTo(a))
.collect(Collectors.toList());
System.out.println("自定义排序结果: " + sortedList1);
结果:
默认排序结果: [1, 2, 3, 6, 6, 7, 7, 8, 9, 9]
自定义排序结果: [9, 9, 8, 7, 7, 6, 6, 3, 2, 1]
截取:limit
List<Integer> numbers = Arrays.asList(1, 2, 3, 6, 6, 7, 7, 8, 9, 9);
// Limit: 截取3个
List<Integer> limitedList = numbers.stream()
.limit(3)
.collect(Collectors.toList());
System.out.println("结果: " + limitedList);结果: [1, 2, 3]
终结操作
这是触发 Stream 流的最终操作,会产生一个最终的结果
遍历:forEach
对流中的每个元素执行指定的操作。
List<Integer> list = Arrays.asList(7, 6, 9, 3, 8, 2, 1);
// 遍历输出符合条件的元素
list.stream().filter(x -> x > 6).forEach(System.out::println);结果:7, 6, 9, 3, 8, 2, 1
查找:findFirst、findAny
List<Integer> list = Arrays.asList(6, 7, 3, 8, 1, 2, 9);
// 匹配第一个
Optional<Integer> findFirst = list.stream().filter(x -> x > 6).findFirst();
// 匹配任意(适用于并行流)
Optional<Integer> findAny = list.parallelStream().filter(x -> x > 6).findAny();
System.out.println("匹配第一个值:" + findFirst.get());
System.out.println("匹配任意一个值:" + findAny.get());匹配第一个值:7
匹配任意一个值:8
是否存在大于6的值:true
聚合:max、min、count
max和min几乎同理
max和min的参数和排序sorted的参数是一样的
Comparator<? super T> comparator 中的方法:int compare(T o1, T o2)
对于max来说,o1-o2则是找最大值,o2-o1则是最小值,而min相反
List<Integer> list = Arrays.asList(6, 7, 3, 8, 1, 2, 9);
// 查找最大的数
Optional<Integer> max = list.stream().max((o1, o2) -> o1 - o2);
System.out.println(max.get());
// 最小值
Optional<Integer> min = list.parallelStream().min((o1, o2) -> o1 - o2);
System.out.println(min.get());结果:
9
1
count:计算流中的元素个数
List<Integer> list = Arrays.asList(6, 7, 3, 8, 1, 2, 9);
// 查找大于6的个数
long count = list.stream().filter(x -> x > 6).count();
System.out.println(count); //3判断:anyMatch、allMatch和noneMatch
判断流中是否存在满足指定条件的元素
anyMatch
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
// 判断是否有大于3的
boolean anyMatchResult = numbers.stream().anyMatch(x -> x > 3);
System.out.println(anyMatchResult); // trueallMatch
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
// 判断是否全部大于3
boolean allMatchResult = numbers.stream().allMatch(x -> x > 3);
System.out.println(allMatchResult); // false
noneMatch
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
// 判断是否全部没有大于5
boolean noneMatchResult = numbers.stream().noneMatch(x -> x > 5);
System.out.println(noneMatchResult); // true
归约:reduce
通过指定的操作将流中的元素合并成一个结果
public class ReduceExample {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
// 示例1: 求和
Optional<Integer> sum = numbers.stream()
.reduce((x, y) -> x + y);
System.out.println("Sum: " + sum.orElse(0));
// 示例2: 求乘积
Optional<Integer> product = numbers.stream()
.reduce((x, y) -> x * y);
System.out.println("Product: " + product.orElse(1));
// 示例3: 求最大值
Optional<Integer> max = numbers.stream()
.reduce(Integer::max);
System.out.println("Max: " + max.orElse(0));
}
}
收集:collect
将流中的元素收集到一个容器中,如List、Set、Map等
collect主要依赖java.util.stream.Collectors类内置的静态方法。
toList/toSet/toMap
List<Student> list= new ArrayList<>();
list.add(new Student("Alice", 20, "男"));
list.add(new Student("Bob", 22, "女"));
list.add(new Student("Diana", 23, "男"));
list.add(new Student("Eve", 19, "女"));
// 转为list集合
List<Student> listNew = list.stream()
.filter(x -> x.getSex().equals("男"))
.collect(Collectors.toList());
System.out.println("toList: " + listNew);
// 转为set集合
Set<Student> set = list.stream()
.filter(x -> x.getSex().equals("女"))
.collect(Collectors.toSet());
System.out.println("toSet: " + set);
// 转为map
Map<String, Student> map = list.stream().filter(s->s.getAge()>20).collect(Collectors.toMap(k -> k.getName(), v -> v));
System.out.println("toMap: " + map);结果:
toList: [Student(name=Alice, age=20, sex=男), Student(name=Diana, age=23, sex=男)]
toSet: [Student(name=Bob, age=22, sex=女), Student(name=Eve, age=19, sex=女)]
toMap: {Diana=Student(name=Diana, age=23, sex=男), Bob=Student(name=Bob, age=22, sex=女)}
统计(count/averaging)
- 计数:
count - 平均值:
averagingInt、averagingLong、averagingDouble - 最值:
maxBy、minBy - 求和:
summingInt、summingLong、summingDouble - 统计以上所有:
summarizingInt、summarizingLong、summarizingDouble
都是一样的操作,没有任何区别,我就拿summarizingInt举例了,
List<Student> list= new ArrayList<>();
list.add(new Student("Alice", 20, "男"));
list.add(new Student("Bob", 22, "女"));
list.add(new Student("Diana", 23, "男"));
list.add(new Student("Eve", 19, "女"));
// 一次性统计 年龄的所有:如最大年龄、最小年龄、平均年龄等
IntSummaryStatistics collect = list.stream().collect(Collectors.summarizingInt(Student::getAge));
System.out.println(collect);分组(partitioningBy/groupingBy)
partitioningBy分区:将stream按条件分为两个Map
groupingBy分组:将集合分为多个Map
List<Student> studentList = new ArrayList<>();
studentList.add(new Student("Alice", 20, "男"));
studentList.add(new Student("Bob", 22, "女"));
studentList.add(new Student("Diana", 23, "男"));
studentList.add(new Student("Eve", 19, "女"));
// 根据 age >= 21分两个区
Map<Boolean, List<Student>> partitionedByAge = studentList.stream()
.collect(Collectors.partitioningBy(student -> student.getAge() >= 21));
System.out.println("年龄大于等于21的分区结果:\n"+partitionedByAge);
// 根据性别分组
Map<String, List<Student>> groupedByGender = studentList.stream()
.collect(Collectors.groupingBy(Student::getSex));
System.out.println("根据性别分组:\n"+groupedByGender);结果:
年龄大于等于21的分区结果:
{false=[Student(name=Alice, age=20, sex=男), Student(name=Eve, age=19, sex=女)],true=[Student(name=Bob, age=22, sex=女), Student(name=Diana, age=23, sex=男)]}
根据性别分组:
{女=[Student(name=Bob, age=22, sex=女), Student(name=Eve, age=19, sex=女)],男=[Student(name=Alice, age=20, sex=男), Student(name=Diana, age=23, sex=男)]}
接合(joining)
将你指定的元素内容进行连接,返回一个字符串
List<Student> studentList = new ArrayList<>();
studentList.add(new Student("Alice", 20, "男"));
studentList.add(new Student("Bob", 22, "女"));
studentList.add(new Student("Diana", 23, "男"));
studentList.add(new Student("Eve", 19, "女"));
// 将所有的学生的名字用,连接起来
String nameJoin = studentList.stream().map(Student::getName).collect(Collectors.joining(","));
System.out.println(nameJoin);结果:Alice,Bob,Diana,Eve
注意事项:
惰性求值:如果没有终结操作,中间操作是不会得到执行的。
流是一次性的:一旦一个流对象经过一个终结操作后,这个流就不能再被使用了,只能重新创建流对象再使用。
不会影响原数据:我们在流中可以对数据做很多处理,但正常情况下是不会影响原来集合中的元素的。
喜欢博主的可以关注一波,一起进步!!!
制作不易,你的点赞就是我的动力














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









