










本文由@星沉阁冰不语出品,转载请注明作者和出处。
文章链接:http://blog.csdn.net/xingchenbingbuyu/article/details/53677630
微博:http://weibo.com/xingchenbing
前一篇博客Net类的设计和神经网络的初始化中,大部分还是比较简单的。因为最重要事情就是生成各种矩阵并初始化。神经网络中的重点和核心就是本文的内容——前向和反向传播两大计算过程。每层的前向传播分别包含加权求和(卷积?)的线性运算和激活函数的非线性运算。反向传播主要是用BP算法更新权值。本文也分为两部分介绍。
一、前向过程
如前所述,前向过程分为线性运算和非线性运算两部分。相对来说比较简单。
线型运算可以用Y = WX+b来表示,其中X是输入样本,这里即是第N层的单列矩阵,W是权值矩阵,Y是加权求和之后的结果矩阵,大小与N+1层的单列矩阵相同。b是偏置,默认初始化全部为0。不难推知(鬼知道我推了多久!),W的大小是(N+1).rows * N.rows。正如上一篇中生成weights矩阵的代码实现一样:
weights[i].create(layer[i + 1].rows, layer[i].rows, CV_32FC1); 非线性运算可以用O=f(Y)来表示。Y就是上面得到的Y。O就是第N+1层的输出。f就是我们一直说的激活函数。激活函数一般都是非线性函数。它存在的价值就是给神经网络提供非线性建模能力。激活函数的种类有很多,比如sigmoid函数,tanh函数,ReLU函数等。各种函数的优缺点可以参考更为专业的论文和其他更为专业的资料。
我们可以先来看一下前向函数forward()的代码:
//Forward
void Net::farward()
{
for (int i = 0; i < layer_neuron_num.size() - 1; ++i)
{
cv::Mat product = weights[i] * layer[i] + bias[i];
layer[i + 1] = activationFunction(product, activation_function);
}
}for循环里面的两句就分别是上面说的线型运算和激活函数的非线性运算。
激活函数activationFunction()里面实现了不同种类的激活函数,可以通过第二个参数来选取用哪一种。代码如下:
//Activation function
cv::Mat Net::activationFunction(cv::Mat &x, std::string func_type)
{
activation_function = func_type;
cv::Mat fx;
if (func_type == "sigmoid")
{
fx = sigmoid(x);
}
if (func_type == "tanh")
{
fx = tanh(x);
}
if (func_type == "ReLU")
{
fx = ReLU(x);
}
return fx;
}各个函数更为细节的部分在Function.h和Function.cpp文件中。在此略去不表,感兴趣的请君移步Github。
需要再次提醒的是,上一篇博客中给出的Net类是精简过的,下面可能会出现一些上一篇Net类里没有出现过的成员变量。完整的Net类的定义还是在Github里。
二、反向传播过程
反向传播原理是链式求导法则,其实就是我们高数中学的复合函数求导法则。这只是在推导公式的时候用的到。具体的推导过程我推荐看看下面这一篇教程,用图示的方法,把前向传播和反向传播表现的清晰明了,强烈推荐!
Principles of training multi-layer neural network using backpropagation。
一会将从这一篇文章中截取一张图来说明权值更新的代码。在此之前,还是先看一下反向传播函数backward()的代码是什么样的:
//Forward
void Net::backward()
{
calcLoss(layer[layer.size() - 1], target, output_error, loss);
deltaError();
updateWeights();
}第一个函数calcLoss()计算输出误差和目标函数,所有输出误差平方和的均值作为需要最小化的目标函数。
第二个函数deltaError()计算delta误差,也就是下图中delta1*df()那部分。
第三个函数updateWeights()更新权值,也就是用下图中的公式更新权值。
下面是从前面强烈推荐的文章中截的一张图:
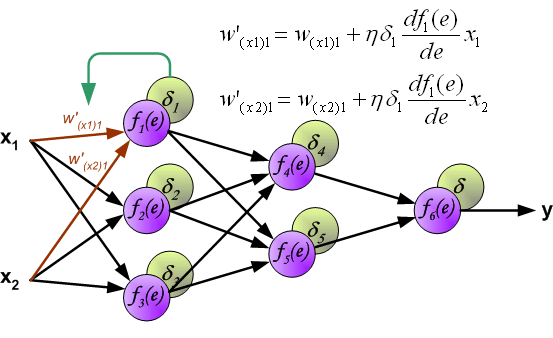
(PS:写到这里的时候,总感觉自己的程序哪里有问题,看了几遍没发现哪里有问题。而且程序确实可以训练。。感觉怪怪的,如果有人看出来了,一定要告诉我啊。)
就看下updateWeights()函数的代码:
//Update weights
void Net::updateWeights()
{
for (int i = 0; i < weights.size(); ++i)
{
cv::Mat delta_weights = learning_rate * (delta_err[i] * layer[i].t());
weights[i] = weights[i] + delta_weights;
}
}核心的两行代码应该还是能比较清晰反映上图中的那个权值更新的公式的。图中公式里的eta常被称作学习率。训练神经网络调参的时候经常要调节这货。
计算输出误差和delta误差的部分纯粹是数学运算,乏善可陈。但是把代码贴在下面吧,因为觉得怪怪的就是这一部分,希望高手指点。
calcLoss()函数在Function.cpp文件中:
//Objective function
void calcLoss(cv::Mat &output, cv::Mat &target, cv::Mat &output_error, float &loss)
{
if (target.empty())
{
std::cout << "Can't find the target cv::Matrix" << std::endl;
return;
}
output_error = target - output;
cv::Mat err_sqrare;
pow(output_error, 2., err_sqrare);
cv::Scalar err_sqr_sum = sum(err_sqrare);
loss = err_sqr_sum[0] / (float)(output.rows);
}deltaError()在Net.cpp中(貌似感觉哪里不对的样子,好像没问题啊):
//Compute delta error
void Net::deltaError()
{
delta_err.resize(layer.size() - 1);
for (int i = delta_err.size() - 1; i >= 0; i--)
{
delta_err[i].create(layer[i + 1].size(), layer[i + 1].type());
//cv::Mat dx = layer[i+1].mul(1 - layer[i+1]);
cv::Mat dx = derivativeFunction(layer[i + 1], activation_function);
//Output layer delta error
if (i == delta_err.size() - 1)
{
delta_err[i] = dx.mul(output_error);
}
else //Hidden layer delta error
{
cv::Mat weight = weights[i];
cv::Mat weight_t = weights[i].t();
cv::Mat delta_err_1 = delta_err[i];
delta_err[i] = dx.mul((weights[i + 1]).t() * delta_err[i + 1]);
}
}
}需要注意的就是计算的时候输出层和隐藏层的计算公式是不一样的。
至此,神经网络最核心的部分已经实现完毕。剩下的就是想想该如何训练了。这个时候你如果愿意的话仍然可以写一个小程序进行几次前向传播和反向传播。还是那句话,鬼知道我在能进行传播之前到底花了多长时间调试!
未完待续...















 2356
2356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









