







今年6月份开始的自己的数据分析项目,到现在已经快3个月的时间了。因为中间停歇了两个月的时间,导致现在依然滞留在数据采集那一部分,还好这两天又有了时间来折腾折腾。
我看到有网友说利用python Scrapy框架可以很方便,并且可以伪造ip,以来防止网站的反爬虫,但是我想把python的爬虫工具都过一遍,所以在开始阶段代码有些冗余、粗糙。
还需不断的改进,嗯,github是个很好的工具。
数据采集这一块我暂时瞄准了VOA网站的数据,想利用自然语言分析来看看当下人们关注的趋势、热点,主要的是学习算法、数据挖掘,这是挚爱啊!但是整个流程挺复杂,从制定需求,到Web scraping、Data processing、SQL OR data Analysis、visualization等等这些功能都需要自己一个人来完成。
最难的是算法(机器学习)那一块,还准备剃个光头去学习数学(以防谢顶让自己难过…)
好了,废话说的挺到位,下面开始进入这篇博客的正题:构建自己的代理ip池
先来描述一下思路:
我在网上看过别人构建ip池,说实话,一点也没看懂,他们说话拐弯抹角的,让人找不到直接的答案。索性就再也没有研究过别人的ip池是怎么构建的。
以我自己的理解,就是构建一个存放ip的库,在爬取web内容的时候,用的代理ip是从自己的库里面取的。(希望看到这篇博客的朋友,如果有好的建议,欢迎直接地提出来,期待与您一起讨论。)
首先有个问题:库的ip从哪里来?
http://www.mimiip.com/gngao/
上面的内容可以爬去下来,不用复杂,爬一页就行。页面更新较频繁,可以用shell做定时任务。
代码:
#-*-coding=utf-8-*-
"""
构建代理IP池,存放在mysql中。
"""
from urlparse import urlparse
from bs4 import BeautifulSoup
from requests.exceptions import ProxyError,ConnectionError
import chardet
import requests
import os
import re
import sys
import datetime
import random
import pymysql.cursors
logging_path = os.getenv('LOGGING_PATH')
sys.path.append(logging_path)
from JobLogging import JobLogging
class CreateProxy():
"""实例化日志输出"""
def __init__(self, log_lev = 'INFO'):
date_today = datetime.datetime.now().date()
log_name = os.path.splitext( os.path.split( sys.argv[0])[1])[0]
log_dir = os.getenv('TASK_LOG_PATH_VOA')
if log_dir is None:
log_dir = '/home/sunnyin/Project/Python/ProjectOfSelf/VOA/ipProxy'
log_dir += '/' + date_today.strftime("%Y%m%d")
if not os.path.isdir(log_dir):
try:
os.makedirs(log_dir)
except :
pass
mylog = JobLogging(log_name,log_dir)
self.log = mylog.get_logger()
self.log.info("Log create success")
#构建代理IP池
def ipList(self):
url_raw = url = "http://www.mimiip.com/gngao/"
urlList = []
ipDicts = {}
session = requests.Session()
#添加请求头
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11'}
req = session.get(url,headers=headers)
bsObj = BeautifulSoup(req.text,"html.parser")
# print(bsObj)
ipField = bsObj.find("table",{"class":"list"}).findAll("tr")
# print(ipField)
#找出所有的IP和PORT
for content in ipField[1:]:
ip = content.find("td",text=re.compile("(\d{1,4}.*)")).text.encode('utf-8')
port = content.find("td",text=re.compile("^(\d{1,4})$")).text.encode('utf-8')
ipDicts[ip] = port
return ipDicts
def insertTable(self,ipDicts):
connection = pymysql.connect(host='localhost',
user='hive',
password='hive',
db='ScrapyProxy',
cursorclass=pymysql.cursors.DictCursor)
try:
with connection.cursor() as cursor:
for ip in ipDicts:
sql = "INSERT INTO IPProxy (ip,port) VALUES (%s,%s)"
cursor.execute(sql,(ip,ipDicts[ip]))
self.log.info("The "+ip+" added the table IPProxy" )
connection.commit()
finally:
connection.close()
self.log.info("IP Proxy added ip completed,please check it..")
if __name__ == '__main__':
x = CreateProxy()
ips = x.ipList()
x.insertTable(ips)知识点:
1 安装mysql,我用的是ubuntu 16版本的,mysql是5.7的。操作和之前的版本不太一样,具体请参考官方文档。
默认root用户是不知道密码的,只能用安装后默认给出的。
cat /etc/mysql/debian.cnf
# Automatically generated for Debian scripts. DO NOT TOUCH!
[client]
host = localhost
user = debian-sys-maint
password = 9ADuU74ctDlaWmY7
socket = /var/run/mysqld/mysqld.sock
[mysql_upgrade]
host = localhost
user = debian-sys-maint
password = 9ADuU74ctDlaWmY7
socket = /var/run/mysqld/mysqld.sock修改密码:
ALTER USER 'root'@'localhost' IDENTIFIED BY 'new_password' PASSWORD EXPIRE INTERVAL 360 DAY;2 python 连接 mysql并查询mysql中的数据
安装 pymysql : pip install pymysql
测试:下图是在ipython notebook上测试的截图

其中有一个函数需要注意,fetchmany(),它可以保存多条查询结果;fetchone()可以保存一条结果,以字典类型存储。
3 数据库连接测试没有问题之后,就可以开始爬取web上的ip了。
效果图:
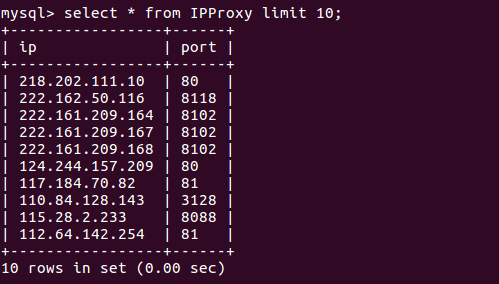
部分日志内容:
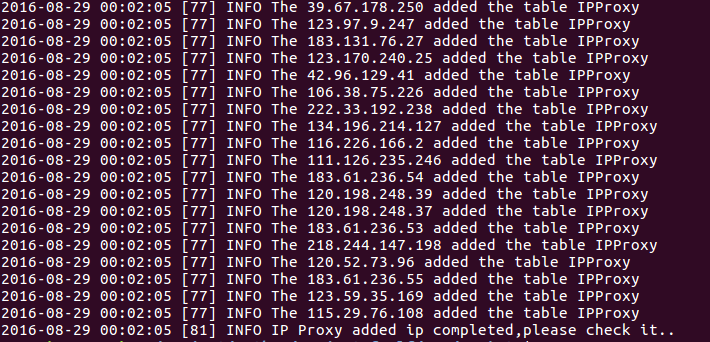
有关日志打印的内容,在上一篇文章中有介绍。
希望攥写博客的习惯可以坚持,爱分享,爱生活。














 417
417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









