







 本文介绍了作者在大数据处理工作中,如何使用Shell脚本来高效处理FTP上传的大量数据并将其入库到Hive。每天处理约1.8TB数据,通过并发处理优化,避免了Hive的慢速load操作,提升了效率。文章还分享了脚本代码,并强调了环境间密钥设置的重要性。
本文介绍了作者在大数据处理工作中,如何使用Shell脚本来高效处理FTP上传的大量数据并将其入库到Hive。每天处理约1.8TB数据,通过并发处理优化,避免了Hive的慢速load操作,提升了效率。文章还分享了脚本代码,并强调了环境间密钥设置的重要性。
哦哦哦,我本是对数据挖掘有着无限的兴趣,现在却从事大数据处理的工作,但是上班是上班,平时依然奋发向上,自学机器学习的东西。但是作为一名非常合格的员工(哈哈,很有不要脸的气质,这很Sunnyin),不能总是在自己博文中记录其他的学识吧,万一哪天被老大看到,岂不得让我雨露均沾,受得万般恩宠。。。。
好了,今天的废话又是说的如此到位,下面进入正题。也就是我现在的这个loooooooooooow项目的数据处理架构。
当然今天不是来讲架构的,而是向贴上去一段我写的shell脚本。希望看到的朋友给出一些宝贵的建议。
先简单说一下我们这个loooooooooow架构:
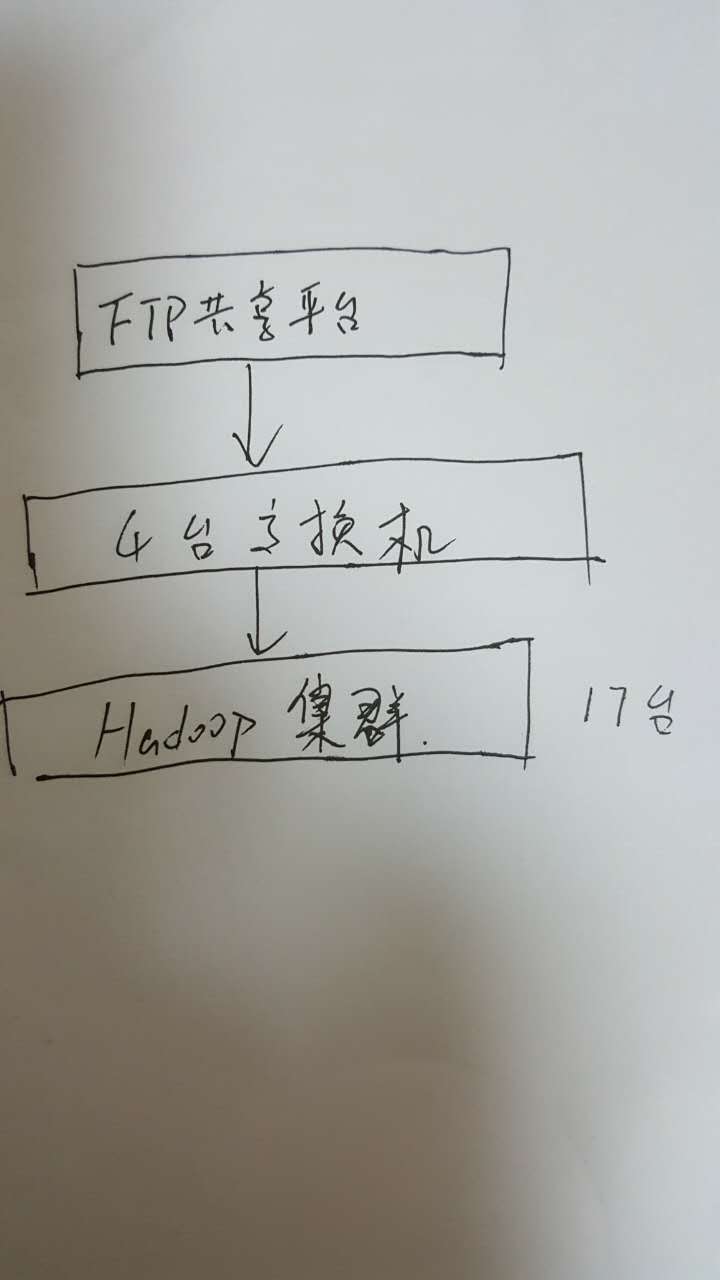
其中交换机与FTP共享平台之间是用的万兆光纤传输,每个文件有380m左右大小,每小时有将近200个文件需要处理,也就是一天大概处理1.8T的数据量,需要插入10张表中。
为了实现在处理数据时可以并发处理,我针对每一张表都写了两个脚本,其中一个放在交换机中,另一个放在Hadoop集群中(最好放在Datanode节点中)。
代码如下:
#/bin/bash
#This script will deal with the dns_data.
LOGIN_FTP_USER=$1
LOGIN_FTP_PASSWD=$2
REMOTE_DIR=/home/sunnyin/test/longName #test dir
LOCAL_DIR=$3 #test dir /home/hadoop/test_818/dataxx
FTP_HOST=$4
TIME_NOW=$5
length_p5=`echo ${TIME_NOW}|wc -L`
data_dir=$LOCAL_DIR/dns/$TIME_NOW #接口路径
#check the parameter
if [ -z ${TIME_NOW} ]; then
TIME_NOW=`date +%Y%m%d%H`
echo "Will get 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 425
425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









