







0. 背景
获得2014年ImageNet挑战赛(ILSVRC14)第一名,google出品
paper地址:going deeper with convolutions
caffe网络结构地址:train_val.prototxt
1. 主要贡献
保证计算资源不变(cpu/memory)的基础上,增加了神经网络的深度和宽度。网络共使用了 22 层隐层,用于classification & object detection。
2. Motivation(现状)
- 加大深度、加大宽度、增加训练数据是现有深度学习获取更好效果的方式;
- 首先训练数据有限,作者举了哈士奇和爱斯基摩犬这种需要专业人士才能区分的例子;
- 加深和加宽都算是增加网络的尺寸,而大尺寸意为着更多的参数,更容易产生过拟合,尤其是当训练数据有限时;
- 增加网络尺寸另外一个缺点是对计算资源侵占过多。
现有的解决办法是使用稀疏网络结构,但问题是目前的计算资源对稀疏网络结构产生的非一致性稀疏数据表现不好,例如缓存命中率低等,且这种缺陷超过了稀疏网络结构带来的优势。
解决办法
使用稀疏网络结构,但是产生稠密的数据,既能增加神经网络表现,又能保证计算资源的使用效率。
- 宽度上,使用金字塔模型,不同尺度的卷积核并联,增加卷积核输出宽度,称为Inception module,如图2a
- 较大尺度卷积核增加了参数,为了减少参数,使用 1×1 的卷积核,如图2b

↑
2a. Inception module, Naïve version

↑
2b. Inception Module with dimension reductions
网络分析

↑
Tabel 1: GoogLeNet incarnation of the Inception architecture
其中的
#3×3 reduce
等表示在这之前使用了
1×1
的卷积核降维之后输出宽度。
第 1 行卷积层
输入(data):
224×224×3
卷积核:
7×7
,滑动步长 2,padding为 3
输出维度:
112×112×64
,计算方式:
12×(224+2×3−7+1)=112
此处有疑惑:我认为参数个数应该是
7×7×64×3=9408
个,而列表当中 params 写的2.7k,谁算清楚了请留言,感谢。
2017-06-26更新:这里面的
7×7
卷积很可能使用了先
7×1
然后
1×7
的方式,这样的话就有
(7+7)×64×3=2,688
个参数。
第 2 行pooling层
输入:
112×112×64
卷积核:
3×3
,滑动步长 2,padding为 1
输出维度:
56×56×64
,计算方式:
12×(112+2×1−3+1)=56
第 5 行 Inception module
分为 4 条支线,输入均为上层产生的 28×28×192 结果:
- 第 1 部分, 1×1 卷积层,输出大小为 28×28×64 ;
- 第 2 部分,先 1×1 卷积层,输出大小为 28×28×96 ,作为输入进行 3×3 卷积层,输出大小为 28×28×128 ;
- 第 3 部分,先 1×1 卷积层,输出大小为 28×28×32 ,作为输入进行 3×3 卷积层,输出大小为 28×28×32 ;
- 第 3 部分, 3×3 的 pooling 层,输出大小为输出大小为 28×28×32 ;
怎么增加网络宽度的?
第 5 行 Inception module 最后会对这四部分输出结果的第三维并联,即 64+128+32+32=256 ,最终输出结果维度: 28×28×256 。
为什么说会降低参数个数?
我们以第 5 行的第 2 部分解说一下。
- 如果没有那个 1×1 卷积层,参数个数为 3×3×192×128=221,184 个;
- 如果加了一个 1×1 卷积层,参数个数为 1×1×192×96+3×3×96×128=129,024 个;
其实很好解释,当 p<m,n 时,有 m×n>m×p+n×p 。
实验部分
- dropout 层 70% 概率 drop;
- SGD 使用 momentum = 0.9,学习率固定,每 8 次全量训练数据( epochs),下降 4%;
- 图像尺寸 8% - 100% 采样,宽高比介于 3:4 和 4:3 之间
- photometric distortions(图像扭曲?)
- 随机使用一种resize方法缩放(bilinear, area, nearest neighbor and cubic,
with equal probability)
Classification
- 使用相同网络结构、网络初始参数、学习参数等,训练 7 个模型,他们只有采样方法、输入图片顺序不同。最终结果同时考虑这 7 个模型结果;
- 一幅图片,缩放为四种尺寸,最短边分别是:256,288,320,352,然后分别截取左中右(上中下)三个正方形子图片。每个子图片的左上、右上、左下、右下以及中心,加上子图片缩放后,共采样 6 次,这 6 张图片又左右镜像,共计 4×3×6×2=144 个最终产生的采样图;
- 最终实验中,上面这些采样图产生的 softmax 结果做均值,产生最终结果。
实验结果与其他结果对比如下表:

↑
performance of the competition
各种策略比对:

↑
performance of fusions of Models
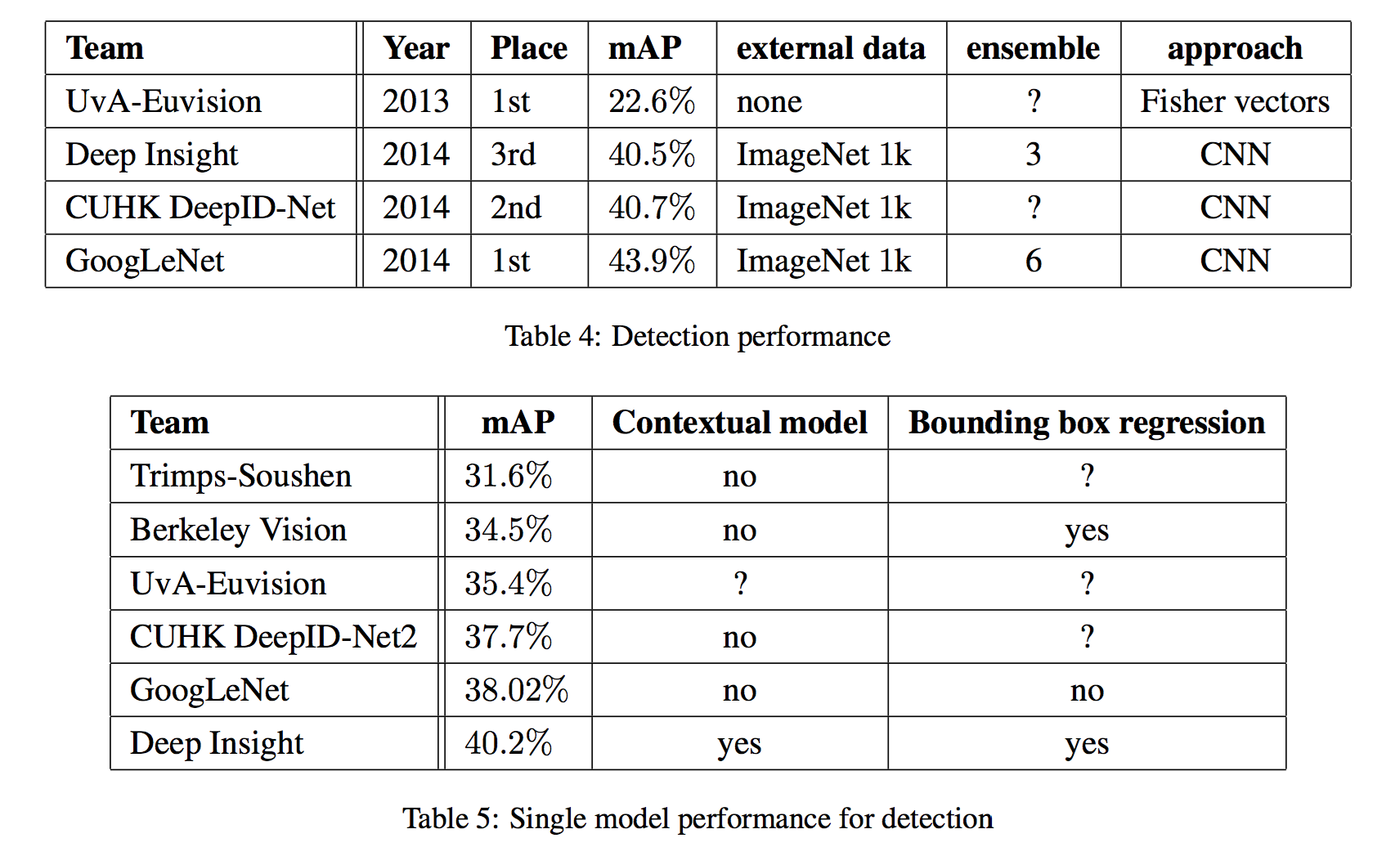
Object Detection
- 与 R-CNN 类似,先提取 proposal 然后使用 classification 模型分类;
- proposal 阶段使用 multi-box,superpixel size 翻倍,减少误召回;
- multi-box 用 200 个 bounding box,R-CNN 用 60%
- 前面说的 6 个分类模型结合分类
结果如下:















 746
746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









