









首先我们需要了解WEB服务器接收到数据是怎样处理的?
WEB服务器端程序接收到客户端传递的整个参数信息后:
1.首先从中分离出每个参数的名称和值的部分(即Key Value这种形式)
2.接着对单个的名称和值部分进行URL解码(此时得到的是字节数组)
3.然后将URL解码得到的字节数组按照某种字符集编码转换成Unicode字符串
注意:
URL编码并不对字符进行直接的编码操作,而是对代表这个字符的数值进行编码,这个数值具体是多少,就要看字符当前使用的字符集编码了。(如果是网页的话,就用显示当前页面的编码来进行URL编码)
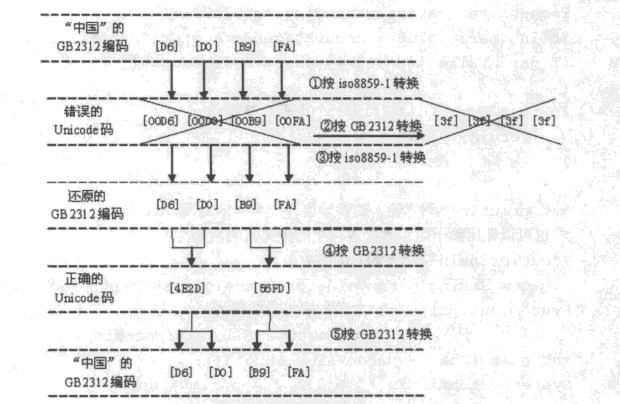
第一行:
浏览器提交数据给服务器,这个数据中带有中文数据,而且进行的是GB2312编码的URL编码。
第二行:
因为没有指定URL解码后以什么编码来转换URL解码后的字节数组。这时系统默认的是ISO-8859-1编码转换。转换后得到的Unicode码肯定和用GB2312转换(解码)后的Unicod码不同,即是错误的Unicode码。
这时,如果将错误的Unicode码再进行GB2312的编码输出给浏览器,得到的就是乱码了。如图中①②两步。
注意:
ISO-8859-1字符集编码到Unicode编码的转换是一种可逆的运算,没有发生信息缺失。
转换规律就是在原来的那一个字节前加一个内容为0的字节。
所以,只要将转换成的Unicode字符串再转换成ISO-8859-1编码(编码),就可以还原出最初的字节数组。
第五行:
还原成最初的进行URL解码后的字节数组。 就是平时我们看到的 new String("".getBytes("ISO-8859-1"),"GB2312");
第六行:
按照GB2312编码转换成Unicode码。
第七行:
此时将正确的Unicode码用GB2312进行编码后输出给浏览器就是正确的“中国”两字了。
总结:
Java内存中的字符串是以Unicode码形式存在的,而外围输入输出设备不使用Unicode,而是使用其他编码(例如UTF-8,GBK )。
所以,输入和输出字符串时,要在某种编码的字节数组和字符串之间进行转换,实际就是在编码和Unicode之间进行转换。















 6641
6641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









