






 本文介绍了一种称为管道和过滤器的设计模式,该模式在云计算环境中特别有用。通过将复杂处理分解为一系列独立的任务(过滤器),可以提高系统的性能、可扩展性和代码的可重用性。
本文介绍了一种称为管道和过滤器的设计模式,该模式在云计算环境中特别有用。通过将复杂处理分解为一系列独立的任务(过滤器),可以提高系统的性能、可扩展性和代码的可重用性。
云计算设计模式(十五)——管道和过滤器模式
分解,执行复杂处理成一系列可重复使用分立元件的一个任务。这种模式可以允许执行的处理进行部署和独立缩放任务元素提高性能,可扩展性和可重用性。
背景和问题
一个应用程序可能需要执行各种关于它处理的信息不同复杂的任务。一个简单,但不灵活的方式来实施这个应用程序可以执行此处理为单一模块。然而,这种方法有可能减少用于重构代码,对其进行优化,或者重新使用它,如果是在应用程序中其他地方所需要的相同的处理的部件的机会。
图1通过使用单片式的方式示出了与处理数据的问题。一个应用程序接收并处理来自两个来源的数据进行处理。从每个源数据是由执行一系列任务来转换该数据,并传递结果给应用程序的业务逻辑之前的独立模块进行处理。
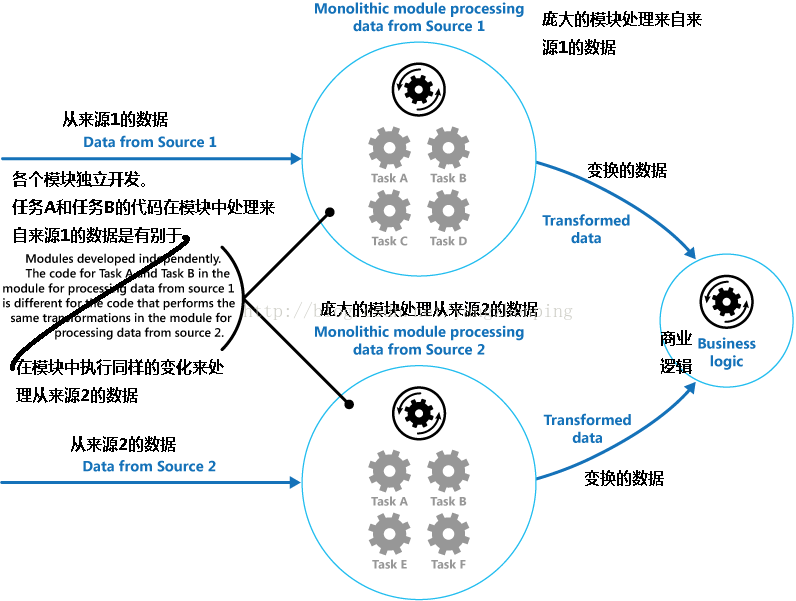
图1 - 使用单一模块实现的解决方案
部分的单片模块执行的任务在功能上是非常相似的,但在模块已被分开设计的。实现该任务的代码被紧密模块内耦合,并且此代码已开发具有很少或没有给定重新使用或可伸缩性的思想。
然而,由每个模块或每个任务的部署要求执行的处理任务,可能会改变,因为业务需求进行修改。有些任务可能是计算密集型的,并可能受益于强大的硬件上运行,而其他人可能并不需要如此昂贵的资源。此外,额外的处理可能需要在将来,或顺序,其中由所述处理执行的任务可能会改变。一个解决方案是必需的,解决了这些问题,并且增加的可能性代码重用。
解决方案
分解需要为每个数据流转换为一组离散的元件(或过滤器)的处理,其中每一个执行单任务。通过标准化每个组件接收和发射的数据的格式,这些过滤器可以组合在一起成为一个管道。这有助于避免重复代码,并且可以很容易地移除,替换或集成额外的组件,如果处理要求改变。图2显示了这种结构的一个例子。

图2 - 通过使用管道和过滤器实现的解决方案
处理一个请求所花费的时间取决于最慢的过滤器管道中的速度。这可能是一个或多个滤波器可能被证明是一个瓶颈,尤其是如果出现在从一个特定的数据源的数据流的大量请求。流水线结构的一个关键优点是它提供了机会,运行速度慢的过滤器的并联情况下,使系统能够分散负载并提高吞吐量。
可以独立缩放组成一个管道可以在不同的机器上运行过滤器,使他们和可以利用的弹性,许多云计算环境提供的优势。过滤器是计算密集型可以在高性能的硬件上运行,而其他要求不高的过滤器可以对商品(便宜)的硬件来承载。过滤器甚至不需要是在同一数据中心或地理位置,它允许在一个管道中的每个元素的环境下接近它需要的资源来运行。
图3示出了从源1施加到管道中的数据的一个例子。
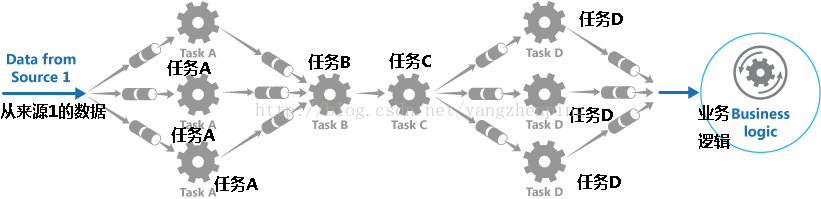
图3 - 在一个管道负载平衡组件
如果一个滤波器的输入和输出被构造为一个流,它可能是能够进行的处理并行的每个过滤器。在流水线的第一个过滤器可以开始工作,并开始发射其结果,它们会直接传递到序列中的下一个过滤器之前的第一过滤器已经完成它的工作。
另一个好处是灵活性,这种模式可以提供。如果一个过滤器发生故障或者其上运行的机器不再可用时,管道可能能够重新安排滤波器所执行的工作,并指示此工作到组件的另一个实例。单个过滤器的故障不会必然导致整个管道的故障。
使用管道和过滤器与补偿交易模式相结合的模式可以提供一种替代的方法来实现分布式事务。分布式事务可以被分解成单独的赔的任务,每个都可以通过使用一个过滤器,也实现了补偿事务图案来实现。在一个管道中的过滤器可以在运行接近它们保持数据被实现为单独的托管工作。
问题和注意事项
在决定如何实现这个模式时,您应考虑以下几点:
•复杂性。增加的灵活性,这种模式提供了还可以引入复杂性,特别是如果被分布在不同的服务器上在管道的过滤器。
•可靠性。使用一个基础结构,可以确保在管道中的过滤器之间流动的数据也不会丢失。
•幂等性。如果在管道中的过滤失败接收到消息后,任务被重新调度到过滤器的另一个实例,所述部分工作可能已经完成。如果这个工作更新的全局状态的某些方面(如存储在数据库中的信息),同样更新可以重复。如果公布的结果,在管道中的下一个过滤器后,过滤器出现故障,但在此之前表示,该公司已经成功地完成了它的工作可能会出现类似的问题。在这些情况下,相同的工作可以由过滤器的另一个实例被重复,导致相同的结果要贴两次。这可能导致在管道随后过滤两次处理相同的数据。因此,在一个管道的过滤器应该被设计为幂等。欲了解更多信息,请参见乔纳森·奥利弗的博客幂等模式。
•重复的消息。如果在管道中的过滤器可以发布一个消息给流水线的下一个阶段之后发生故障时,过滤器的另一个实例,可以执行(由幂等考虑以上所描述的),并且将发布相同消息的拷贝到流水线。这可能导致同样的信息的两个实例被传递到下一个过滤器。为了避免这种情况,该管道应检测并消除重复的消息。
注意:
如果要实现管道使用消息队列(如微软的Azure服务总线队列),消息队列基础设施可以提供自动重复消息检测和清除。
•上下文和状态。在管道中,每个过滤器主要运行在孤立和不应该做这件事是如何被调用的任何假设。这意味着,每一个过滤器必须具有足够的上下文与它能够执行它的工作提供。这种情况下可包含相当数量的状态信息。
何时使用这个模式
使用这种模式时:
•由一个应用程序所需的处理可以很容易地被分解成一组离散的,独立的步骤。
•由应用程序执行的处理步骤具有不同的可扩展性要求。
注意:
它可能会向组过滤器应扩展一起在相同的过程。欲了解更多信息,请参阅计算资源整合模式。
•灵活性是必需的,以允许通过一个应用程序,或能力进行添加和删除步骤中的处理步骤重新排序。
•该系统可以受益于分配处理跨不同服务器的步骤。
•一个可靠的解决方案是必需的,当数据正在被处理的最小化在一个步骤失败的影响。
这种模式可能不适合时:
•通过应用程序执行的处理步骤并不是独立的,或者他们必须共同作为同一事务的一部分来执行。
•在一个步骤所需的上下文或状态的信息量使得这种方法效率很低。它可能会持续状态信息到数据库代替,但不要使用此策略,如果在数据库上的额外负载会导致过度竞争。
例子
可以使用消息队列的一个序列,以提供执行流水线所需的基础设施。最初的消息队列接收未处理的消息。实现为过滤器的任务侦听此队列的消息的组件,它执行其工作,然后投递转化的消息序列中的下一个队列。另一个过滤器的任务可以侦听在这个队列中的消息,对其进行处理,后的结果到另一个队列,依此类推,直到完全转化的数据出现在队列中的最后一个消息。

图4 - 通过使用消息队列实现管道
如果你正在构建一个解决方案,在Azure上,你可以使用服务总线队列提供了可靠的,可扩展的排队机制。下面所示的ServiceBusPipeFilter类提供了一个例子。它演示了如何实现接收从队列中输入消息,处理这些邮件的过滤器,并张贴结果到另一个队列。
注意:
该ServiceBusPipeFilter类在PipesAndFilters解决方案PipesAndFilters.Shared项目定义。此示例代码都可以可以下载本指导意见。
public class ServiceBusPipeFilter
{
...
private readonly string inQueuePath;
private readonly string outQueuePath;
...
private QueueClient inQueue;
private QueueClient outQueue;
...
public ServiceBusPipeFilter(..., string inQueuePath, string outQueuePath = null)
{
...
this.inQueuePath = inQueuePath;
this.outQueuePath = outQueuePath;
}
public void Start()
{
...
// Create the outbound filter queue if it does not exist.
...
this.outQueue = QueueClient.CreateFromConnectionString(...);
...
// Create the inbound and outbound queue clients.
this.inQueue = QueueClient.CreateFromConnectionString(...);
}
public void OnPipeFilterMessageAsync(
Func<BrokeredMessage, Task<BrokeredMessage>> asyncFilterTask, ...)
{
...
this.inQueue.OnMessageAsync(
async (msg) =>
{
...
// Process the filter and send the output to the
// next queue in the pipeline.
var outMessage = await asyncFilterTask(msg);
// Send the message from the filter processor
// to the next queue in the pipeline.
if (outQueue != null)
{
await outQueue.SendAsync(outMessage);
}
// Note: There is a chance that the same message could be sent twice
// or that a message may be processed by an upstream or downstream
// filter at the same time.
// This would happen in a situation where processing of a message was
// completed, it was sent to the next pipe/queue, and then failed
// to complete when using the PeekLock method.
// Idempotent message processing and concurrency should be considered
// in a real-world implementation.
},
options);
}
public async Task Close(TimeSpan timespan)
{
// Pause the processing threads.
this.pauseProcessingEvent.Reset();
// There is no clean approach for waiting for the threads to complete
// the processing. This example simply stops any new processing, waits
// for the existing thread to complete, then closes the message pump
// and finally returns.
Thread.Sleep(timespan);
this.inQueue.Close();
...
}
...
}
在ServiceBusPipeFilter类Start方法连接到一对输入和输出队列,以及关闭方法从输入队列断开。该OnPipeFilterMessageAsync方法执行消息的实际处理;该asyncFilterTask参数这种方法指定要执行的处理。该OnPipeFilterMessageAsync方法等待输入队列中收到的消息,因为它到达,并张贴结果到输出队列通过运行在每个邮件的asyncFilterTask参数指定的代码。队列本身的构造函数中指定。
样品溶液的过滤器实现了在一组工作角色。每个工人的作用可独立进行调整,这取决于它执行的业务处理的复杂性,或者它需要执行此处理的资源。此外,各辅助角色的多个实例可以并行地运行,以提高吞吐量。
下面的代码显示了一个名为PipeFilterARoleEntry的Azure工作者角色,这是在样品溶液中PipeFilterA项目定义。
public class PipeFilterARoleEntry : RoleEntryPoint
{
...
private ServiceBusPipeFilter pipeFilterA;
public override bool OnStart()
{
...
this.pipeFilterA = new ServiceBusPipeFilter(
...,
Constants.QueueAPath,
Constants.QueueBPath);
this.pipeFilterA.Start();
...
}
public override void Run()
{
this.pipeFilterA.OnPipeFilterMessageAsync(async (msg) =>
{
// Clone the message and update it.
// Properties set by the broker (Deliver count, enqueue time, ...)
// are not cloned and must be copied over if required.
var newMsg = msg.Clone();
await Task.Delay(500); // DOING WORK
Trace.TraceInformation("Filter A processed message:{0} at {1}",
msg.MessageId, DateTime.UtcNow);
newMsg.Properties.Add(Constants.FilterAMessageKey, "Complete");
return newMsg;
});
...
}
...
}
这个角色包含ServiceBusPipeFilter对象。在角色OnStart方法连接到队列接收输入的信息并张贴输出消息(队列的名称在常量类中定义)。 Run方法调用OnPipeFilterMessagesAsync方法来对接收到的(在本例中,该处理通过等待较短的时间段模拟的)的每个消息执行某些处理。何时处理完成时,一个新的消息被构造包含结果(在这种情况下,输入消息被简单地增加了一个自定义属性),并将该消息发送到输出队列。
示例代码中包含一个名为PipeFilterBRoleEntry在PipeFilterB项目的另一名工人的作用。这个角色类似于PipeFilterARoleEntry不同之处在于它的Run方法进行不同的处理。在本例中的解决方案,这两种作用结合起来,构建一个管道;为PipeFilterARoleEntry角色输出队列是用于PipeFilterBRoleEntry角色的输入队列。
样品溶液还提供了两个名为InitialSenderRoleEntry(在InitialSender项目)和FinalReceiverRoleEntry(在FinalReceiver项目),进一步的角色。该InitialSenderRoleEntry作用提供了在管道中的初始消息。 OnStart方法连接到单个队列和运行方法的帖子的方法来此队列。这个队列是所使用的PipeFilterARoleEntry作用,所以发布一条消息到这个队列的输入队列导致由PipeFilterARoleEntry作用来接收和处理消息。经处理的信息,然后通过PipeFilterBRoleEntry作用传递。
为FinalReceiveRoleEntry角色输入队列是用于PipeFilterBRoleEntry角色的输出队列。 Run方法在FinalReceiveRoleEntry作用,如下图所示,接收到该消息,并且执行一些最后的处理。然后将其写入了过滤器的管道跟踪输出添加自定义属性的值。
public class FinalReceiverRoleEntry : RoleEntryPoint
{
...
// Final queue/pipe in the pipeline from which to process data.
private ServiceBusPipeFilter queueFinal;
public override bool OnStart()
{
...
// Set up the queue.
this.queueFinal = new ServiceBusPipeFilter(...,Constants.QueueFinalPath);
this.queueFinal.Start();
...
}
public override void Run()
{
this.queueFinal.OnPipeFilterMessageAsync(
async (msg) =>
{
await Task.Delay(500); // DOING WORK
// The pipeline message was received.
Trace.TraceInformation(
"Pipeline Message Complete - FilterA:{0} FilterB:{1}",
msg.Properties[Constants.FilterAMessageKey],
msg.Properties[Constants.FilterBMessageKey]);
return null;
});
...
}
...
}

















 1336
1336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









