







MapReduce之计数器及实例
http://www.aboutyun.com/thread-13745-1-1.html
计数器使用:
http://www.aboutyun.com/thread-13745-1-1.html
感兴趣的直接点上面链接,会有更详细的解析
问题导读
1.hadoop有哪些内置计数器?
2.job.getCounters()可以得到什么?
3.MapReduce是否允许用户自定义计数器?
简述:
Hadoop计数器:可以让开发人员以全局的视角来审查相关作业的运行情况以及各项指标,及时做出错误诊断并进行相应处理。
相比而言,计数器方式比日志更易于分析。
内置计数器:
相比而言,计数器方式比日志更易于分析。
(1)Hadoop内置的计数器,主要用来记录作业的执行情况
(2)内置计数器包括如下:
—MapReduce框架计数器(Map-Reduce Framework)
—文件系统计数器(File System Counters)
—作业计数器(Job Counters)
—文件输入格式计数器(File Output Format Counters)
—文件输出格式计数器(File Input Format Counters)
—Shuffle 错误计数器(Shuffle Errors)
(3)计数器由相关的task进行维护,定期传递给tasktracker,再由tasktracker传给jobtracker;
(4)最终的作业计数器实际上是由jobtracker维护,所以计数器可以被全局汇总,同时也不必在整个网络中传递。
(5)只有当一个作业执行成功后,最终的计数器的值才是完整可靠的;
(2)内置计数器包括如下:
—MapReduce框架计数器(Map-Reduce Framework)
—文件系统计数器(File System Counters)
—作业计数器(Job Counters)
—文件输入格式计数器(File Output Format Counters)
—文件输出格式计数器(File Input Format Counters)
—Shuffle 错误计数器(Shuffle Errors)
(3)计数器由相关的task进行维护,定期传递给tasktracker,再由tasktracker传给jobtracker;
(4)最终的作业计数器实际上是由jobtracker维护,所以计数器可以被全局汇总,同时也不必在整个网络中传递。
(5)只有当一个作业执行成功后,最终的计数器的值才是完整可靠的;
[Bash shell]
纯文本查看
复制代码
01 | 内置计数器: |
02 | 15/06/15 08:46:47 INFO mapreduce.Job: Job job_1434248323399_0004 completed successfully |
03 | 15/06/15 08:46:47 INFO mapreduce.Job: Counters: 49 |
04 | File System Counters |
05 | FILE: Number of bytes read=103 |
06 | FILE: Number of bytes written=315873 |
07 | FILE: Number of read operations=0 |
08 | FILE: Number of large read operations=0 |
09 | FILE: Number of write operations=0 |
10 | HDFS: Number of bytes read=116 |
11 | HDFS: Number of bytes written=40 |
12 | HDFS: Number of read operations=9 |
13 | HDFS: Number of large read operations=0 |
14 | HDFS: Number of write operations=4 |
15 | Job Counters |
16 | Launched map tasks=1 |
17 | Launched reduce tasks=2 |
18 | Data-local map tasks=1 |
19 | Total time spent by all maps in occupied slots (ms)=2893 |
20 | Total time spent by all reduces in occupied slots (ms)=6453 |
21 | Total time spent by all map tasks (ms)=2893 |
22 | Total time spent by all reduce tasks (ms)=6453 |
23 | Total vcore-seconds taken by all map tasks=2893 |
24 | Total vcore-seconds taken by all reduce tasks=6453 |
25 | Total megabyte-seconds taken by all map tasks=2962432 |
26 | Total megabyte-seconds taken by all reduce tasks=6607872 |
27 | Map-Reduce Framework |
28 | Map input records=7 |
29 | Map output records=7 |
30 | Map output bytes=77 |
31 | Map output materialized bytes=103 |
32 | Input split bytes=95 |
33 | Combine input records=0 |
34 | Combine output records=0 |
35 | Reduce input groups=2 |
36 | Reduce shuffle bytes=103 |
37 | Reduce input records=7 |
38 | Reduce output records=2 |
39 | Spilled Records=14 |
40 | Shuffled Maps =2 |
41 | Failed Shuffles=0 |
42 | Merged Map outputs=2 |
43 | GC time elapsed (ms)=59 |
44 | CPU time spent (ms)=3600 |
45 | Physical memory (bytes) snapshot=606015488 |
46 | Virtual memory (bytes) snapshot=2672865280 |
47 | Total committed heap usage (bytes)=602996736 |
48 | Shuffle Errors |
49 | BAD_ID=0 |
50 | CONNECTION=0 |
51 | IO_ERROR=0 |
52 | WRONG_LENGTH=0 |
53 | WRONG_MAP=0 |
54 | WRONG_REDUCE=0 |
55 |
56 | BAD_ID=0 |
57 | CONNECTION=0 |
58 | IO_ERROR=0 |
59 | WRONG_LENGTH=0 |
60 | WRONG_MAP=0 |
61 | WRONG_REDUCE=0 |
62 | File Input Format Counters |
63 | Bytes Read=21 |
64 | File Output Format Counters |
65 | Bytes Written=40 |
计数器使用:
1、Web UI进行查看
(注:要启动历史服务器)
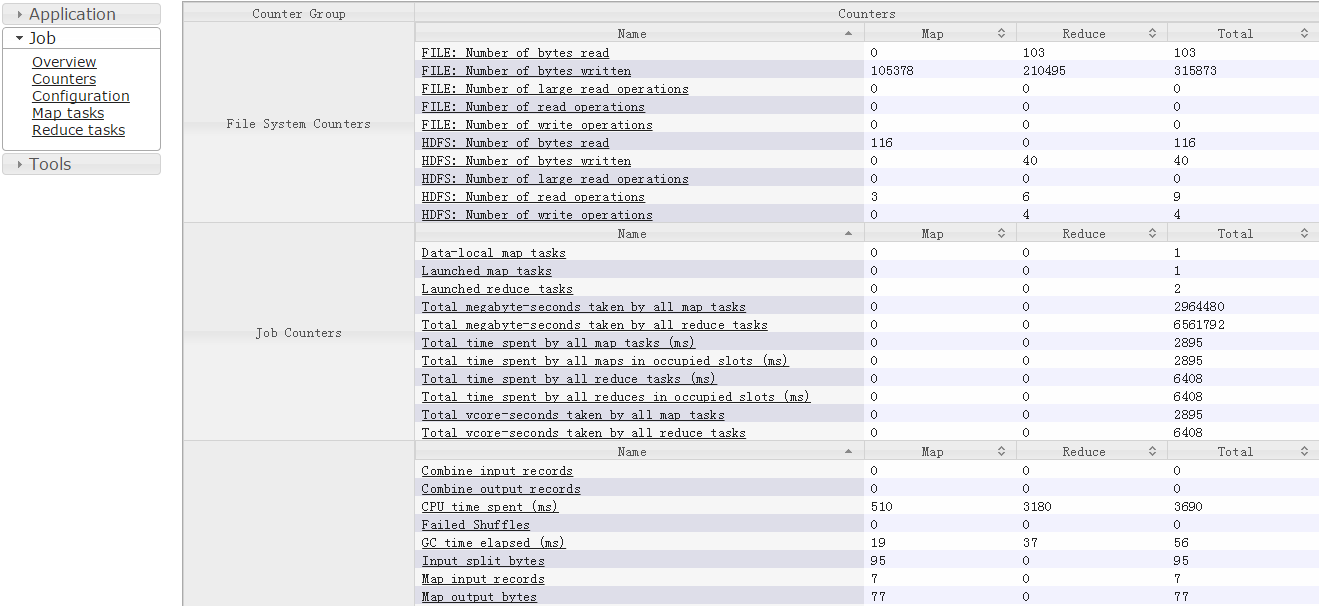
(注:要启动历史服务器)
2、命令行方式:
hadoop job -counter(Hadoop2.x无效)
hadoop job -counter(Hadoop2.x无效)
3、使用Hadoop API
通过job.getCounters()得到Counters,而后调用counters.findCounter()方法去得到计数器对象;查看最终的计数器的值需要等作业完成之后。
自定义计数器及实例:
通过job.getCounters()得到Counters,而后调用counters.findCounter()方法去得到计数器对象;查看最终的计数器的值需要等作业完成之后。
MapReduce允许用户自定义计数器,计数器是一个全局变量,计数器有组的概念,可以用Java的枚举类型或者用字符串来定义方法;
[Java]
纯文本查看
复制代码
01 | package org.apache.hadoop.mapreduce; |
02 | public interface TaskAttemptContext extends JobContext, Progressable { |
03 | //Get the {@link Counter} for the given |
04 | //<code>counterName</code>. |
05 | public Counter getCounter(Enum<?> counterName); |
06 |
07 | //Get the {@link Counter} for the given |
08 | //<code>groupName</code> and <code>counterName</code>. |
09 | public Counter getCounter(String groupName, String counterName); |
10 | } |
字符串方式(动态计数器)比枚举类型要更加灵活,可以动态在一个组下面添加多个计数器;在旧API中使用Reporter,而新API用context.getCounter(groupName,counterName)来获取计数器配置并设置;然后让计数器递增。
[Java]
纯文本查看
复制代码
01 | package org.apache.hadoop.mapreduce; |
02 | /** |
03 | * A named counter that tracks the progress of a map/reduce job. |
04 | * <p><code>Counters</code> represent global counters, defined either by the |
05 | * Map-Reduce framework or applications. Each <code>Counter</code> is named by |
06 | * an {@link Enum} and has a long for the value.</p> |
07 | * <p><code>Counters</code> are bunched into Groups, each comprising of |
08 | * counters from a particular <code>Enum</code> class. |
09 | */ |
10 | public interface Counter extends Writable { |
11 | /** |
12 | * Increment this counter by the given value |
13 | * @param incr the value to increase this counter by |
14 | */ |
15 | void increment(long incr); |
16 | } |
自定义计数器实例
统计词汇行中词汇数 超过2个或少于2个的行数:
输入数据文件counter
统计词汇行中词汇数 超过2个或少于2个的行数:
输入数据文件counter
[Bash shell]
纯文本查看
复制代码
01 | [root@liguodong file]# vi counter |
02 | [root@liguodong file]# hdfs dfs -put counter /counter |
03 | [root@liguodong file]# hdfs dfs -cat /counter |
04 | hello world |
05 | hello hadoop |
06 | hi baby |
07 | hello 4325 7785993 |
08 | java hadoop |
09 | come |
[Java]
纯文本查看
复制代码
01 | package MyCounter; |
02 |
03 | import java.io.IOException; |
04 | import java.net.URI; |
05 | import java.net.URISyntaxException; |
06 |
07 | import org.apache.hadoop.conf.Configuration; |
08 | import org.apache.hadoop.fs.FileSystem; |
09 | import org.apache.hadoop.fs.Path; |
10 | import org.apache.hadoop.io.IntWritable; |
11 | import org.apache.hadoop.io.LongWritable; |
12 | import org.apache.hadoop.io.Text; |
13 | import org.apache.hadoop.mapreduce.Job; |
14 | import org.apache.hadoop.mapreduce.Mapper; |
15 | import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; |
16 | import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; |
17 |
18 | import MyPartitioner.MyPartitioner; |
19 | import MyPartitioner.MyPartitioner.DefPartitioner; |
20 | import MyPartitioner.MyPartitioner.MyMapper; |
21 | import MyPartitioner.MyPartitioner.MyReducer; |
22 |
23 | public class MyCounter { |
24 | private final static String INPUT_PATH = "hdfs://liguodong:8020/counter"; |
25 | private final static String OUTPUT_PATH = "hdfs://liguodong:8020/outputcounter"; |
26 | public static class MyMapper extends Mapper<LongWritable, Text, LongWritable, Text> |
27 | { |
28 | @Override |
29 | protected void map(LongWritable key, Text value, Context context) |
30 | throws IOException, InterruptedException |
31 | { |
32 | String[] val = value.toString().split("\\s+"); |
33 | if(val.length<2){ |
34 | context.getCounter("ErrorCounter","below_2").increment(1); |
35 | }else if(val.length>2){ |
36 | context.getCounter("ErrorCounter", "above_2").increment(1); |
37 | } |
38 | context.write(key, value); |
39 | } |
40 | } |
41 |
42 | public static void main(String[] args) throws IllegalArgumentException, IOException, |
43 | URISyntaxException, ClassNotFoundException, InterruptedException { |
44 | Configuration conf = new Configuration(); |
45 | final FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH),conf); |
46 | if(fileSystem.exists(new Path(OUTPUT_PATH))) |
47 | { |
48 | fileSystem.delete(new Path(OUTPUT_PATH),true); |
49 | } |
50 | Job job = Job.getInstance(conf, "define counter"); |
51 |
52 | job.setJarByClass(MyPartitioner.class); |
53 |
54 | FileInputFormat.addInputPath(job, new Path(INPUT_PATH)); |
55 | job.setMapperClass(MyMapper.class); |
56 |
57 | job.setNumReduceTasks(0); |
58 |
59 | FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH)); |
60 | //提交作业 |
61 | System.exit(job.waitForCompletion(true) ? 0 : 1); |
62 | } |
63 | } |
[Bash shell]
纯文本查看
复制代码
01 | 运行结果: |
02 | [main] INFO org.apache.hadoop.mapreduce.Job - Counters: 25 |
03 | File System Counters |
04 | FILE: Number of bytes read=148 |
05 | FILE: Number of bytes written=187834 |
06 | FILE: Number of read operations=0 |
07 | FILE: Number of large read operations=0 |
08 | FILE: Number of write operations=0 |
09 | HDFS: Number of bytes read=69 |
10 | HDFS: Number of bytes written=86 |
11 | HDFS: Number of read operations=8 |
12 | HDFS: Number of large read operations=0 |
13 | HDFS: Number of write operations=3 |
14 | Map-Reduce Framework |
15 | Map input records=6 |
16 | Map output records=6 |
17 | Input split bytes=94 |
18 | Spilled Records=0 |
19 | Failed Shuffles=0 |
20 | Merged Map outputs=0 |
21 | GC time elapsed (ms)=12 |
22 | CPU time spent (ms)=0 |
23 | Physical memory (bytes) snapshot=0 |
24 | Virtual memory (bytes) snapshot=0 |
25 | Total committed heap usage (bytes)=16252928 |
26 | ErrorCounter |
27 | above_2=1 |
28 | below_2=1 |
29 | File Input Format Counters |
30 | Bytes Read=69 |
31 | File Output Format Counters |
32 | Bytes Written=86 |















 563
563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









